 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-semantics Aware Generative Approach for Domain-Agnostic Multilabel Classification
Jun 07, 2025



The explosion of textual data has made manual document classification increasingly challenging. To address this, we introduce a robust, efficient domain-agnostic generative model framework for multi-label text classification. Instead of treating labels as mere atomic symbols, our approach utilizes predefined label descriptions and is trained to generate these descriptions based on the input text. During inference, the generated descriptions are matched to the pre-defined labels using a finetuned sentence transformer. We integrate this with a dual-objective loss function, combining cross-entropy loss and cosine similarity of the generated sentences with the predefined target descriptions, ensuring both semantic alignment and accuracy. Our proposed model LAGAMC stands out for its parameter efficiency and versatility across diverse datasets, making it well-suited for practical applications. We demonstrate the effectiveness of our proposed model by achieving new state-of-the-art performances across all evaluated datasets, surpassing several strong baselines. We achieve improvements of 13.94% in Micro-F1 and 24.85% in Macro-F1 compared to the closest baseline across all datasets.
Parameter-Efficient Instruction Tuning of Large Language Models For Extreme Financial Numeral Labelling
May 15, 2024


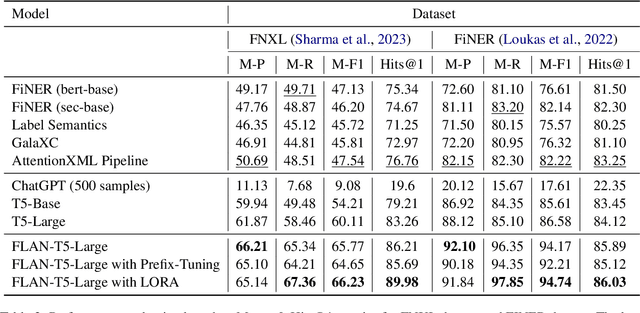
We study the problem of automatically annotating relevant numerals (GAAP metrics) occurring in the financial documents with their corresponding XBRL tags. Different from prior works, we investigate the feasibility of solving this extreme classification problem using a generative paradigm through instruction tuning of Large Language Models (LLMs). To this end, we leverage metric metadata information to frame our target outputs while proposing a parameter efficient solution for the task using LoRA. We perform experiments on two recently released financial numeric labeling datasets. Our proposed model, FLAN-FinXC, achieves new state-of-the-art performances on both the datasets, outperforming several strong baselines. We explain the better scores of our proposed model by demonstrating its capability for zero-shot as well as the least frequently occurring tags. Also, even when we fail to predict the XBRL tags correctly, our generated output has substantial overlap with the ground-truth in majority of the cases.
Instruction-Guided Bullet Point Summarization of Long Financial Earnings Call Transcripts
May 03, 2024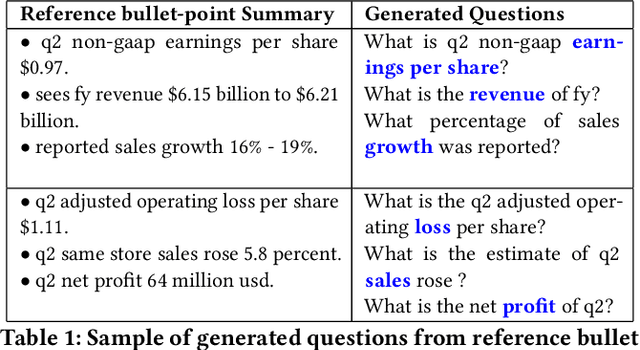
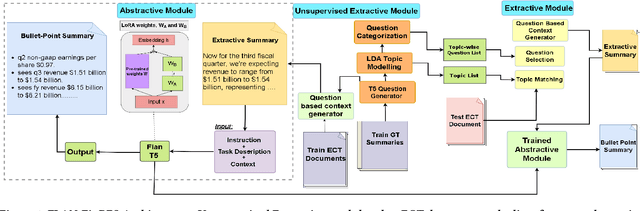

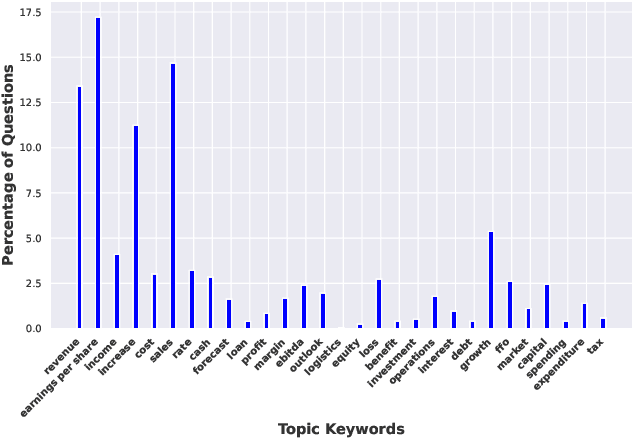
While automatic summarization techniques have made significant advancements, their primary focus has been on summarizing short news articles or documents that have clear structural patterns like scientific articles or government reports. There has not been much exploration into developing efficient methods for summarizing financial documents, which often contain complex facts and figures. Here, we study the problem of bullet point summarization of long Earning Call Transcripts (ECTs) using the recently released ECTSum dataset. We leverage an unsupervised question-based extractive module followed by a parameter efficient instruction-tuned abstractive module to solve this task. Our proposed model FLAN-FinBPS achieves new state-of-the-art performances outperforming the strongest baseline with 14.88% average ROUGE score gain, and is capable of generating factually consistent bullet point summaries that capture the important facts discussed in the ECTs.
Financial Numeric Extreme Labelling: A Dataset and Benchmarking for XBRL Tagging
Jun 06, 2023


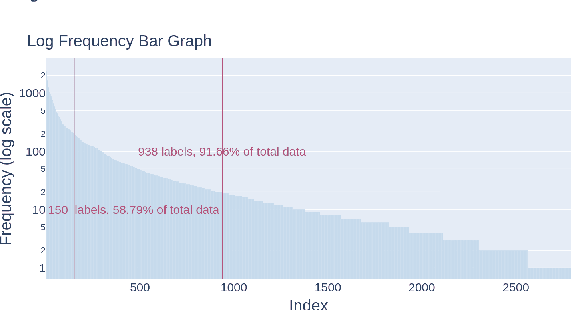
The U.S. Securities and Exchange Commission (SEC) mandates all public companies to file periodic financial statements that should contain numerals annotated with a particular label from a taxonomy. In this paper, we formulate the task of automating the assignment of a label to a particular numeral span in a sentence from an extremely large label set. Towards this task, we release a dataset, Financial Numeric Extreme Labelling (FNXL), annotated with 2,794 labels. We benchmark the performance of the FNXL dataset by formulating the task as (a) a sequence labelling problem and (b) a pipeline with span extraction followed by Extreme Classification. Although the two approaches perform comparably, the pipeline solution provides a slight edge for the least frequent labels.