 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAURA: Affordance-Understanding and Risk-aware Alignment Technique for Large Language Models
Aug 08, 2025Present day LLMs face the challenge of managing affordance-based safety risks-situations where outputs inadvertently facilitate harmful actions due to overlooked logical implications. Traditional safety solutions, such as scalar outcome-based reward models, parameter tuning, or heuristic decoding strategies, lack the granularity and proactive nature needed to reliably detect and intervene during subtle yet crucial reasoning steps. Addressing this fundamental gap, we introduce AURA, an innovative, multi-layered framework centered around Process Reward Models (PRMs), providing comprehensive, step level evaluations across logical coherence and safety-awareness. Our framework seamlessly combines introspective self-critique, fine-grained PRM assessments, and adaptive safety-aware decoding to dynamically and proactively guide models toward safer reasoning trajectories. Empirical evidence clearly demonstrates that this approach significantly surpasses existing methods, significantly improving the logical integrity and affordance-sensitive safety of model outputs. This research represents a pivotal step toward safer, more responsible, and contextually aware AI, setting a new benchmark for alignment-sensitive applications.
RA-MTR: A Retrieval Augmented Multi-Task Reader based Approach for Inspirational Quote Extraction from Long Documents
Feb 17, 2025Inspirational quotes from famous individuals are often used to convey thoughts in news articles, essays, and everyday conversations. In this paper, we propose a novel context-based quote extraction system that aims to extract the most relevant quote from a long text. We formulate this quote extraction as an open domain question answering problem first by employing a vector-store based retriever and then applying a multi-task reader. We curate three context-based quote extraction datasets and introduce a novel multi-task framework RA-MTR that improves the state-of-the-art performance, achieving a maximum improvement of 5.08% in BoW F1-score.
* Accepted at COLING2025-MAIN
REVERSUM: A Multi-staged Retrieval-Augmented Generation Method to Enhance Wikipedia Tail Biographies through Personal Narratives
Feb 17, 2025Wikipedia is an invaluable resource for factual information about a wide range of entities. However, the quality of articles on less-known entities often lags behind that of the well-known ones. This study proposes a novel approach to enhancing Wikipedia's B and C category biography articles by leveraging personal narratives such as autobiographies and biographies. By utilizing a multi-staged retrieval-augmented generation technique -- REVerSum -- we aim to enrich the informational content of these lesser-known articles. Our study reveals that personal narratives can significantly improve the quality of Wikipedia articles, providing a rich source of reliable information that has been underutilized in previous studies. Based on crowd-based evaluation, REVerSum generated content outperforms the best performing baseline by 17% in terms of integrability to the original Wikipedia article and 28.5\% in terms of informativeness. Code and Data are available at: https://github.com/sayantan11995/wikipedia_enrichment
* Accepted at COLING2025 Industry Track
GRAFFORD: A Benchmark Dataset for Testing the Knowledge of Object Affordances of Language and Vision Models
Feb 20, 2024



We investigate the knowledge of object affordances in pre-trained language models (LMs) and pre-trained Vision-Language models (VLMs). Transformers-based large pre-trained language models (PTLM) learn contextual representation from massive amounts of unlabeled text and are shown to perform impressively in downstream NLU tasks. In parallel, a growing body of literature shows that PTLMs fail inconsistently and non-intuitively, showing a lack of reasoning and grounding. To take a first step toward quantifying the effect of grounding (or lack thereof), we curate a novel and comprehensive dataset of object affordances -- GrAFFORD, characterized by 15 affordance classes. Unlike affordance datasets collected in vision and language domains, we annotate in-the-wild sentences with objects and affordances. Experimental results reveal that PTLMs exhibit limited reasoning abilities when it comes to uncommon object affordances. We also observe that pre-trained VLMs do not necessarily capture object affordances effectively. Through few-shot fine-tuning, we demonstrate improvement in affordance knowledge in PTLMs and VLMs. Our research contributes a novel dataset for language grounding tasks, and presents insights into LM capabilities, advancing the understanding of object affordances. Codes and data are available at https://github.com/sayantan11995/Affordance
Placing Facts on a Timeline: A Classification cum Coref Resolution Approach
Jun 28, 2022
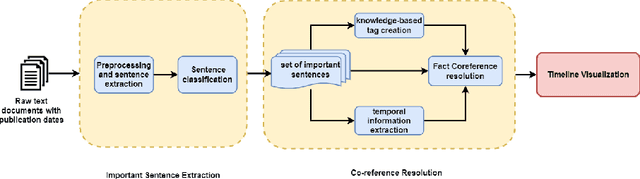
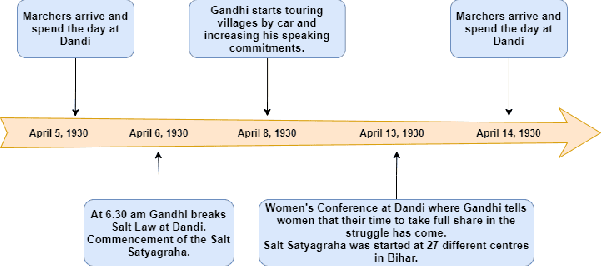
A timeline provides one of the most effective ways to visualize the important historical facts that occurred over a period of time, presenting the insights that may not be so apparent from reading the equivalent information in textual form. By leveraging generative adversarial learning for important sentence classification and by assimilating knowledge based tags for improving the performance of event coreference resolution we introduce a two staged system for event timeline generation from multiple (historical) text documents. We demonstrate our results on two manually annotated historical text documents. Our results can be extremely helpful for historians, in advancing research in history and in understanding the socio-political landscape of a country as reflected in the writings of famous personas.
cs60075_team2 at SemEval-2021 Task 1 : Lexical Complexity Prediction using Transformer-based Language Models pre-trained on various text corpora
Jun 04, 2021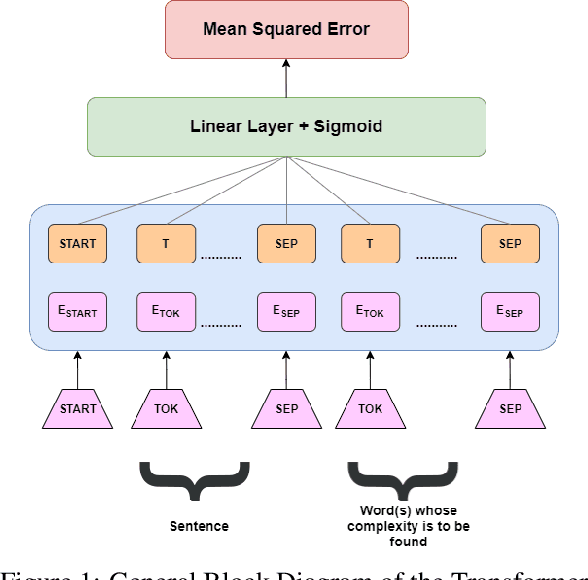
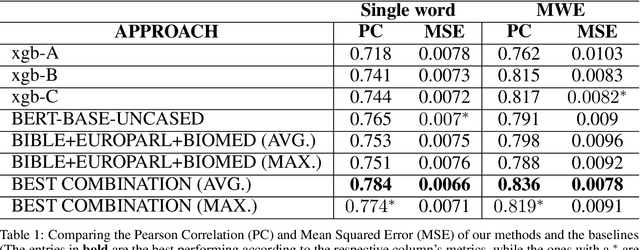
This paper describes the performance of the team cs60075_team2 at SemEval 2021 Task 1 - Lexical Complexity Prediction. The main contribution of this paper is to fine-tune transformer-based language models pre-trained on several text corpora, some being general (E.g., Wikipedia, BooksCorpus), some being the corpora from which the CompLex Dataset was extracted, and others being from other specific domains such as Finance, Law, etc. We perform ablation studies on selecting the transformer models and how their individual complexity scores are aggregated to get the resulting complexity scores. Our method achieves a best Pearson Correlation of $0.784$ in sub-task 1 (single word) and $0.836$ in sub-task 2 (multiple word expressions).