 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel 3DPIFCM Algorithm for Noisy Brain MRI Images
Paper and Code
Feb 05, 2020
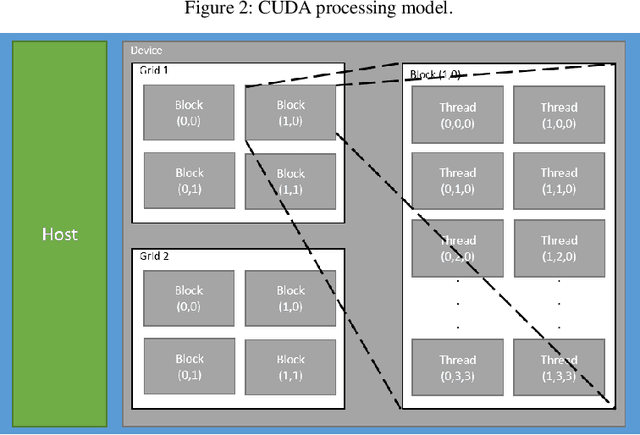
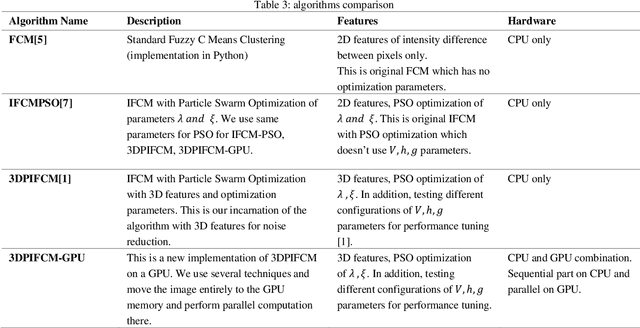
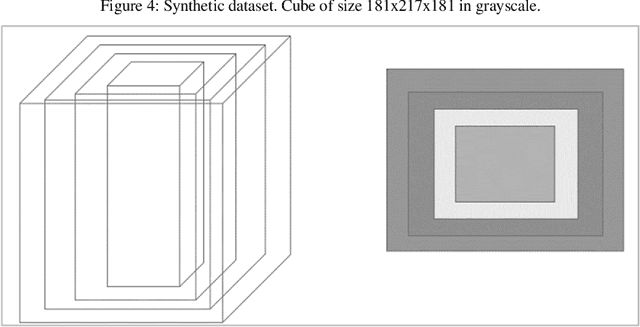
In this paper we implemented the algorithm we developed in [1] called 3DPIFCM in a parallel environment by using CUDA on a GPU. In our previous work we introduced 3DPIFCM which performs segmentation of images in noisy conditions and uses particle swarm optimization for finding the optimal algorithm parameters to account for noise. This algorithm achieved state of the art segmentation accuracy when compared to FCM (Fuzzy C-Means), IFCMPSO (Improved Fuzzy C-Means with Particle Swarm Optimization), GAIFCM (Genetic Algorithm Improved Fuzzy C-Means) on noisy MRI images of an adult Brain. When using a genetic algorithm or PSO (Particle Swarm Optimization) on a single machine for optimization we witnessed long execution times for practical clinical usage. Therefore, in the current paper our goal was to speed up the execution of 3DPIFCM by taking out parts of the algorithm and executing them as kernels on a GPU. The algorithm was implemented using the CUDA [13] framework from NVIDIA and experiments where performed on a server containing 64GB RAM , 8 cores and a TITAN X GPU with 3072 SP cores and 12GB of GPU memory. Our results show that the parallel version of the algorithm performs up to 27x faster than the original sequential version and 68x faster than GAIFCM algorithm. We show that the speedup of the parallel version increases as we increase the size of the image due to better utilization of cores in the GPU. Also, we show a speedup of up to 5x in our Brainweb experiment compared to other generic variants such as IFCMPSO and GAIFCM.