 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Effective Ensembles for Sentiment Analysis
Feb 26, 2024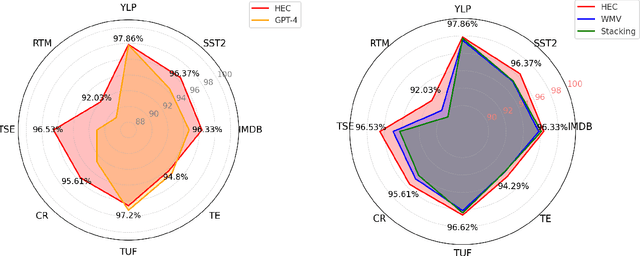
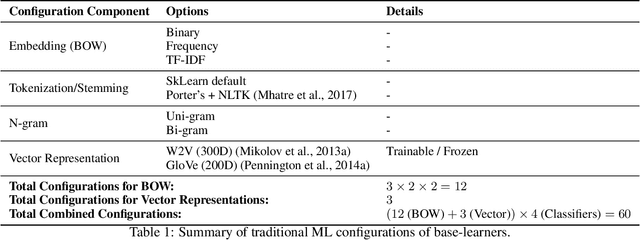

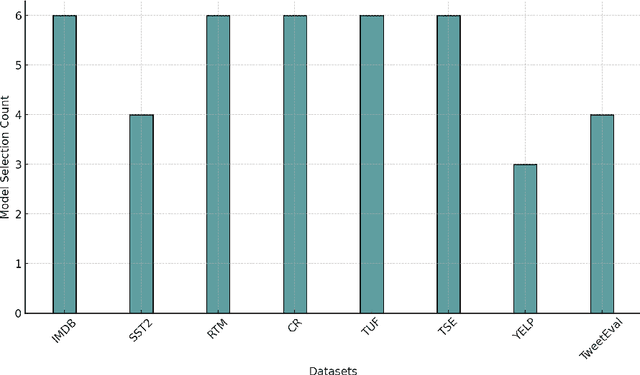
In recent years, transformer models have revolutionized Natural Language Processing (NLP), achieving exceptional results across various tasks, including Sentiment Analysis (SA). As such, current state-of-the-art approaches for SA predominantly rely on transformer models alone, achieving impressive accuracy levels on benchmark datasets. In this paper, we show that the key for further improving the accuracy of such ensembles for SA is to include not only transformers, but also traditional NLP models, despite the inferiority of the latter compared to transformer models. However, as we empirically show, this necessitates a change in how the ensemble is constructed, specifically relying on the Hierarchical Ensemble Construction (HEC) algorithm we present. Our empirical studies across eight canonical SA datasets reveal that ensembles incorporating a mix of model types, structured via HEC, significantly outperform traditional ensembles. Finally, we provide a comparative analysis of the performance of the HEC and GPT-4, demonstrating that while GPT-4 closely approaches state-of-the-art SA methods, it remains outperformed by our proposed ensemble strategy.
Justifying Social-Choice Mechanism Outcome for Improving Participant Satisfaction
May 24, 2022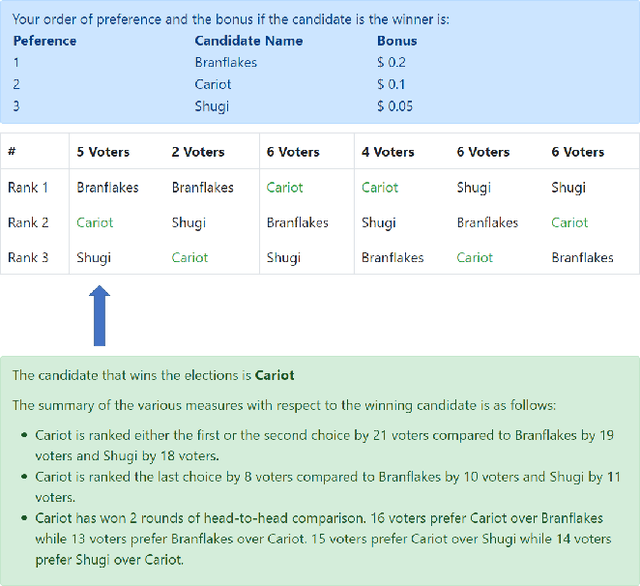
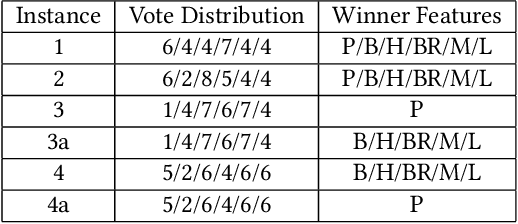
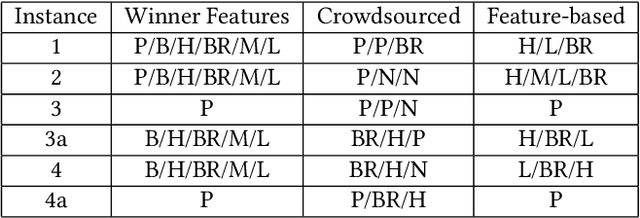
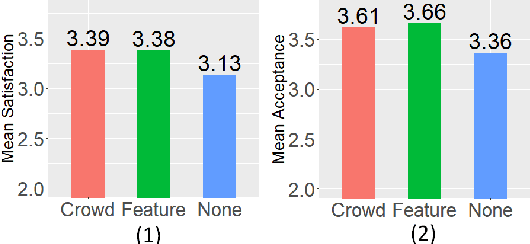
In many social-choice mechanisms the resulting choice is not the most preferred one for some of the participants, thus the need for methods to justify the choice made in a way that improves the acceptance and satisfaction of said participants. One natural method for providing such explanations is to ask people to provide them, e.g., through crowdsourcing, and choosing the most convincing arguments among those received. In this paper we propose the use of an alternative approach, one that automatically generates explanations based on desirable mechanism features found in theoretical mechanism design literature. We test the effectiveness of both of the methods through a series of extensive experiments conducted with over 600 participants in ranked voting, a classic social choice mechanism. The analysis of the results reveals that explanations indeed affect both average satisfaction from and acceptance of the outcome in such settings. In particular, explanations are shown to have a positive effect on satisfaction and acceptance when the outcome (the winning candidate in our case) is the least desirable choice for the participant. A comparative analysis reveals that the automatically generated explanations result in similar levels of satisfaction from and acceptance of an outcome as with the more costly alternative of crowdsourced explanations, hence eliminating the need to keep humans in the loop. Furthermore, the automatically generated explanations significantly reduce participants' belief that a different winner should have been elected compared to crowdsourced explanations.
Co-clustering of Fuzzy Lagged Data
May 15, 2014
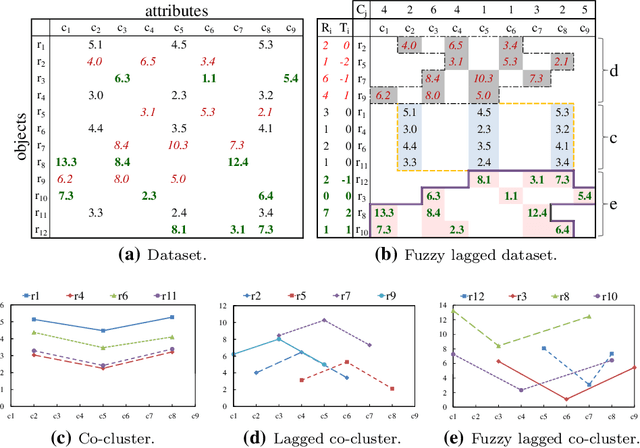
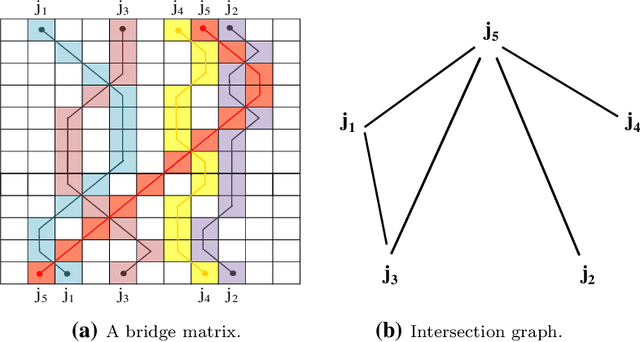
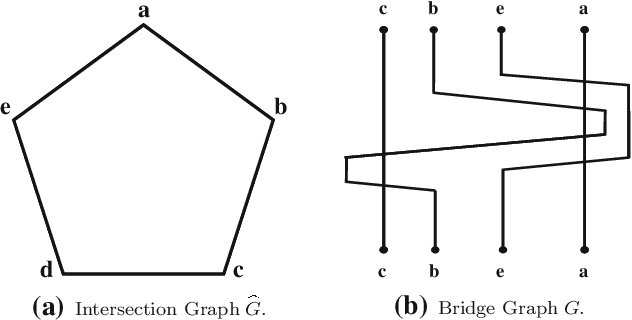
The paper focuses on mining patterns that are characterized by a fuzzy lagged relationship between the data objects forming them. Such a regulatory mechanism is quite common in real life settings. It appears in a variety of fields: finance, gene expression, neuroscience, crowds and collective movements are but a limited list of examples. Mining such patterns not only helps in understanding the relationship between objects in the domain, but assists in forecasting their future behavior. For most interesting variants of this problem, finding an optimal fuzzy lagged co-cluster is an NP-complete problem. We thus present a polynomial-time Monte-Carlo approximation algorithm for mining fuzzy lagged co-clusters. We prove that for any data matrix, the algorithm mines a fuzzy lagged co-cluster with fixed probability, which encompasses the optimal fuzzy lagged co-cluster by a maximum 2 ratio columns overhead and completely no rows overhead. Moreover, the algorithm handles noise, anti-correlations, missing values and overlapping patterns. The algorithm was extensively evaluated using both artificial and real datasets. The results not only corroborate the ability of the algorithm to efficiently mine relevant and accurate fuzzy lagged co-clusters, but also illustrate the importance of including the fuzziness in the lagged-pattern model.