 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Questions by Meta-Reasoning over Multiple Chains of Thought
Apr 25, 2023



Modern systems for multi-hop question answering (QA) typically break questions into a sequence of reasoning steps, termed chain-of-thought (CoT), before arriving at a final answer. Often, multiple chains are sampled and aggregated through a voting mechanism over the final answers, but the intermediate steps themselves are discarded. While such approaches improve performance, they do not consider the relations between intermediate steps across chains and do not provide a unified explanation for the predicted answer. We introduce Multi-Chain Reasoning (MCR), an approach which prompts large language models to meta-reason over multiple chains of thought, rather than aggregating their answers. MCR examines different reasoning chains, mixes information between them and selects the most relevant facts in generating an explanation and predicting the answer. MCR outperforms strong baselines on 7 multi-hop QA datasets. Moreover, our analysis reveals that MCR explanations exhibit high quality, enabling humans to verify its answers.
Weakly Supervised Mapping of Natural Language to SQL through Question Decomposition
Dec 12, 2021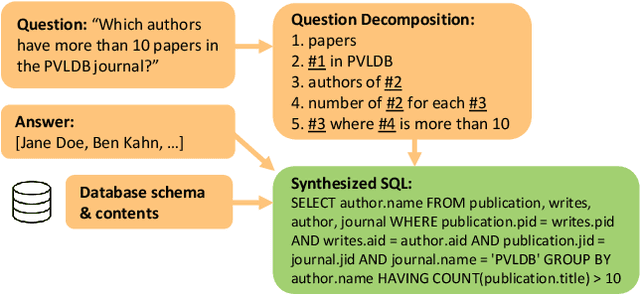
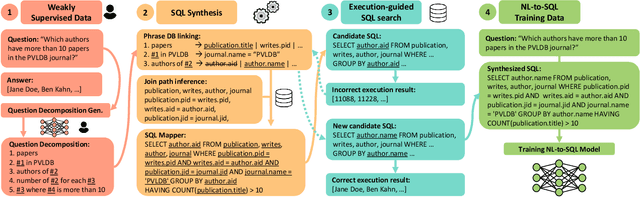

Natural Language Interfaces to Databases (NLIDBs), where users pose queries in Natural Language (NL), are crucial for enabling non-experts to gain insights from data. Developing such interfaces, by contrast, is dependent on experts who often code heuristics for mapping NL to SQL. Alternatively, NLIDBs based on machine learning models rely on supervised examples of NL to SQL mappings (NL-SQL pairs) used as training data. Such examples are again procured using experts, which typically involves more than a one-off interaction. Namely, each data domain in which the NLIDB is deployed may have different characteristics and therefore require either dedicated heuristics or domain-specific training examples. To this end, we propose an alternative approach for training machine learning-based NLIDBs, using weak supervision. We use the recently proposed question decomposition representation called QDMR, an intermediate between NL and formal query languages. Recent work has shown that non-experts are generally successful in translating NL to QDMR. We consequently use NL-QDMR pairs, along with the question answers, as supervision for automatically synthesizing SQL queries. The NL questions and synthesized SQL are then used to train NL-to-SQL models, which we test on five benchmark datasets. Extensive experiments show that our solution, requiring zero expert annotations, performs competitively with models trained on expert annotated data.
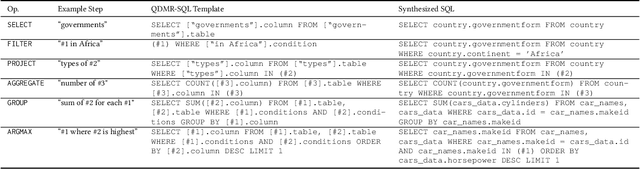
Break It Down: A Question Understanding Benchmark
Jan 31, 2020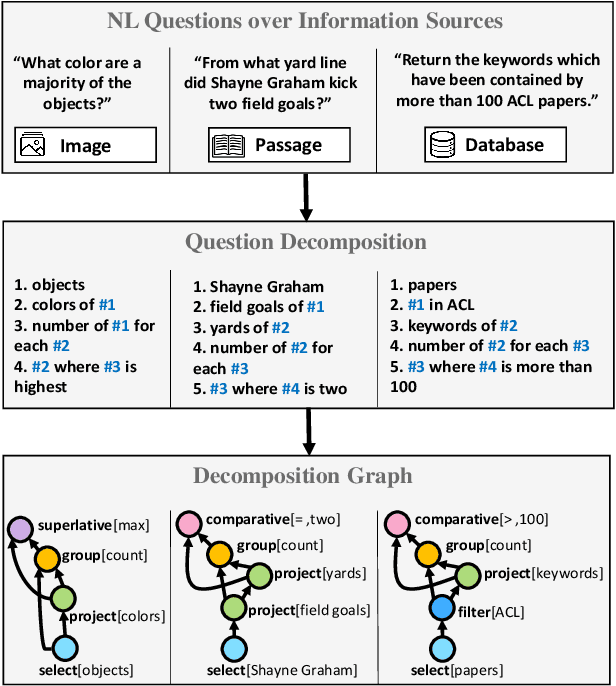
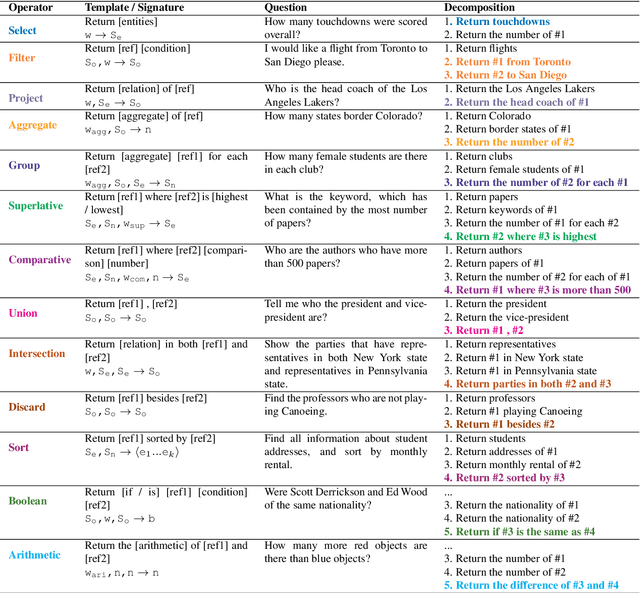
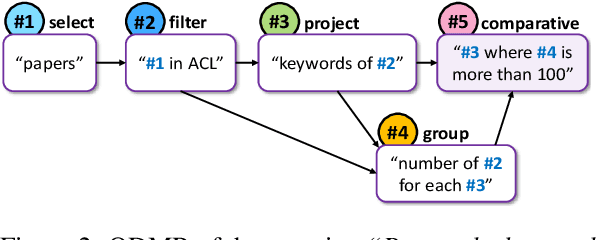

Understanding natural language questions entails the ability to break down a question into the requisite steps for computing its answer. In this work, we introduce a Question Decomposition Meaning Representation (QDMR) for questions. QDMR constitutes the ordered list of steps, expressed through natural language, that are necessary for answering a question. We develop a crowdsourcing pipeline, showing that quality QDMRs can be annotated at scale, and release the Break dataset, containing over 83K pairs of questions and their QDMRs. We demonstrate the utility of QDMR by showing that (a) it can be used to improve open-domain question answering on the HotpotQA dataset, (b) it can be deterministically converted to a pseudo-SQL formal language, which can alleviate annotation in semantic parsing applications. Last, we use Break to train a sequence-to-sequence model with copying that parses questions into QDMR structures, and show that it substantially outperforms several natural baselines.
Explaining Queries over Web Tables to Non-Experts
Aug 14, 2018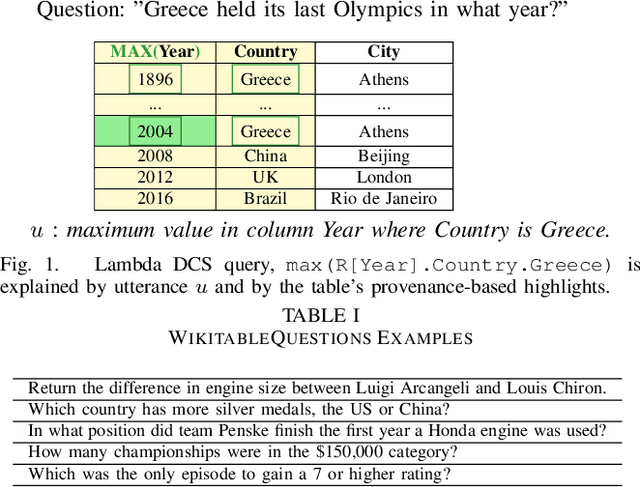
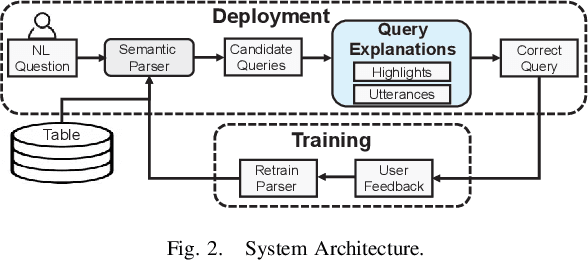

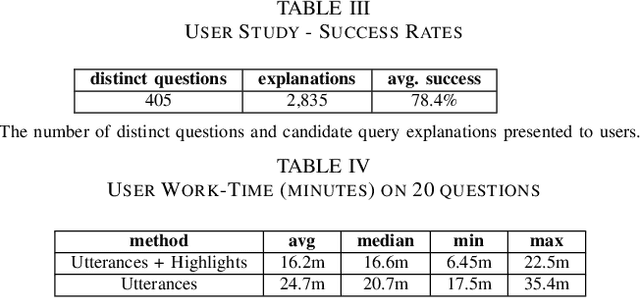
Designing a reliable natural language (NL) interface for querying tables has been a longtime goal of researchers in both the data management and natural language processing (NLP) communities. Such an interface receives as input an NL question, translates it into a formal query, executes the query and returns the results. Errors in the translation process are not uncommon, and users typically struggle to understand whether their query has been mapped correctly. We address this problem by explaining the obtained formal queries to non-expert users. Two methods for query explanations are presented: the first translates queries into NL, while the second method provides a graphic representation of the query cell-based provenance (in its execution on a given table). Our solution augments a state-of-the-art NL interface over web tables, enhancing it in both its training and deployment phase. Experiments, including a user study conducted on Amazon Mechanical Turk, show our solution to improve both the correctness and reliability of an NL interface.