 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Mapping of Natural Language to SQL through Question Decomposition
Paper and Code
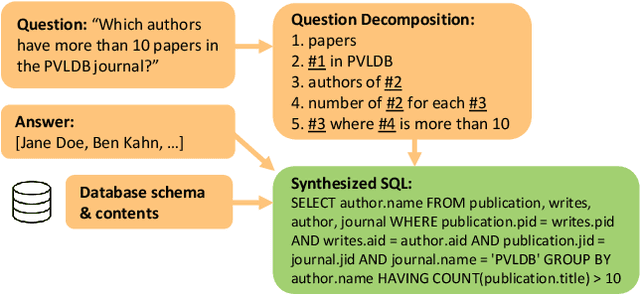
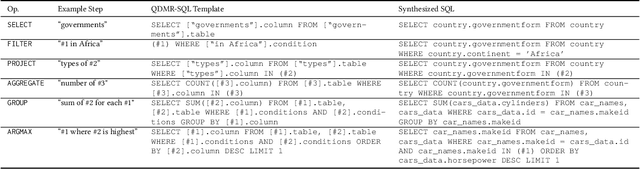
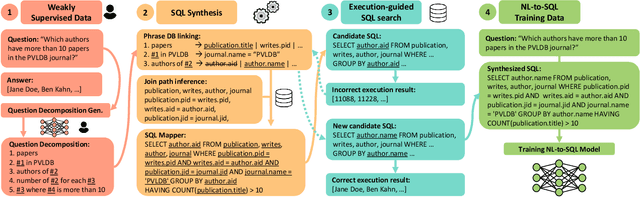

Natural Language Interfaces to Databases (NLIDBs), where users pose queries in Natural Language (NL), are crucial for enabling non-experts to gain insights from data. Developing such interfaces, by contrast, is dependent on experts who often code heuristics for mapping NL to SQL. Alternatively, NLIDBs based on machine learning models rely on supervised examples of NL to SQL mappings (NL-SQL pairs) used as training data. Such examples are again procured using experts, which typically involves more than a one-off interaction. Namely, each data domain in which the NLIDB is deployed may have different characteristics and therefore require either dedicated heuristics or domain-specific training examples. To this end, we propose an alternative approach for training machine learning-based NLIDBs, using weak supervision. We use the recently proposed question decomposition representation called QDMR, an intermediate between NL and formal query languages. Recent work has shown that non-experts are generally successful in translating NL to QDMR. We consequently use NL-QDMR pairs, along with the question answers, as supervision for automatically synthesizing SQL queries. The NL questions and synthesized SQL are then used to train NL-to-SQL models, which we test on five benchmark datasets. Extensive experiments show that our solution, requiring zero expert annotations, performs competitively with models trained on expert annotated data.