 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-range Language Modeling with Self-retrieval
Jun 23, 2023Retrieval-augmented language models (LMs) have received much attention recently. However, typically the retriever is not trained jointly as a native component of the LM, but added to an already-pretrained LM, which limits the ability of the LM and the retriever to adapt to one another. In this work, we propose the Retrieval-Pretrained Transformer (RPT), an architecture and training procedure for jointly training a retrieval-augmented LM from scratch for the task of modeling long texts. Given a recently generated text chunk in a long document, the LM computes query representations, which are then used to retrieve earlier chunks in the document, located potentially tens of thousands of tokens before. Information from retrieved chunks is fused into the LM representations to predict the next target chunk. We train the retriever component with a semantic objective, where the goal is to retrieve chunks that increase the probability of the next chunk, according to a reference LM. We evaluate RPT on four long-range language modeling tasks, spanning books, code, and mathematical writing, and demonstrate that RPT improves retrieval quality and subsequently perplexity across the board compared to strong baselines.
QAMPARI: : An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs
May 26, 2022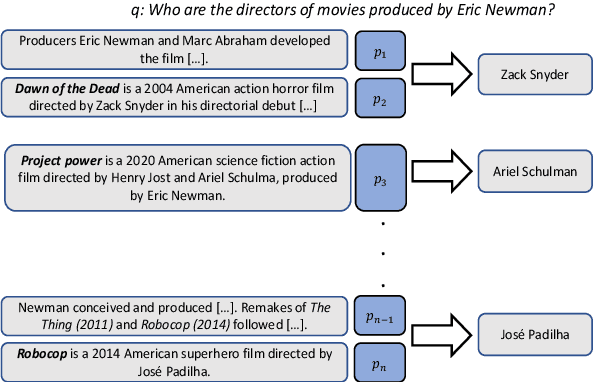

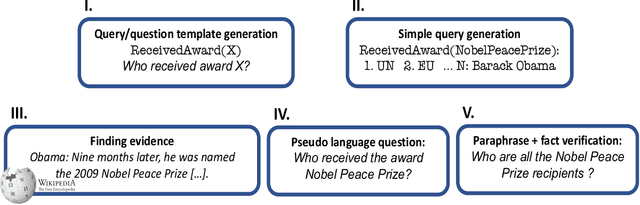
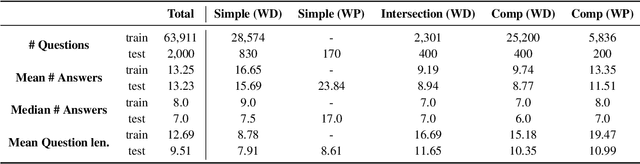
Existing benchmarks for open-domain question answering (ODQA) typically focus on questions whose answers can be extracted from a single paragraph. By contrast, many natural questions, such as "What players were drafted by the Brooklyn Nets?" have a list of answers. Answering such questions requires retrieving and reading from many passages, in a large corpus. We introduce QAMPARI, an ODQA benchmark, where question answers are lists of entities, spread across many paragraphs. We created QAMPARI by (a) generating questions with multiple answers from Wikipedia's knowledge graph and tables, (b) automatically pairing answers with supporting evidence in Wikipedia paragraphs, and (c) manually paraphrasing questions and validating each answer. We train ODQA models from the retrieve-and-read family and find that QAMPARI is challenging in terms of both passage retrieval and answer generation, reaching an F1 score of 26.6 at best. Our results highlight the need for developing ODQA models that handle a broad range of question types, including single and multi-answer questions.
Learning To Retrieve Prompts for In-Context Learning
Dec 16, 2021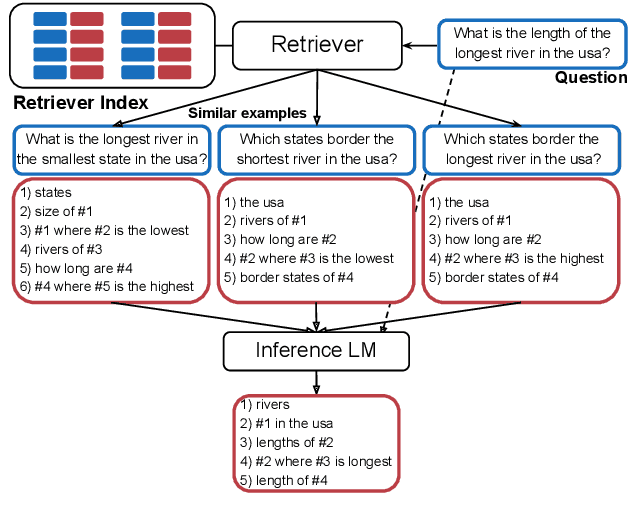

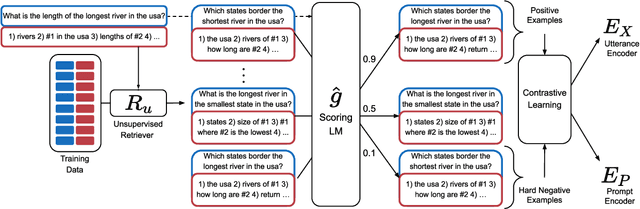

In-context learning is a recent paradigm in natural language understanding, where a large pre-trained language model (LM) observes a test instance and a few training examples as its input, and directly decodes the output without any update to its parameters. However, performance has been shown to strongly depend on the selected training examples (termed prompt). In this work, we propose an efficient method for retrieving prompts for in-context learning using annotated data and a LM. Given an input-output pair, we estimate the probability of the output given the input and a candidate training example as the prompt, and label training examples as positive or negative based on this probability. We then train an efficient dense retriever from this data, which is used to retrieve training examples as prompts at test time. We evaluate our approach on three sequence-to-sequence tasks where language utterances are mapped to meaning representations, and find that it substantially outperforms prior work and multiple baselines across the board.
SmBoP: Semi-autoregressive Bottom-up Semantic Parsing
Oct 23, 2020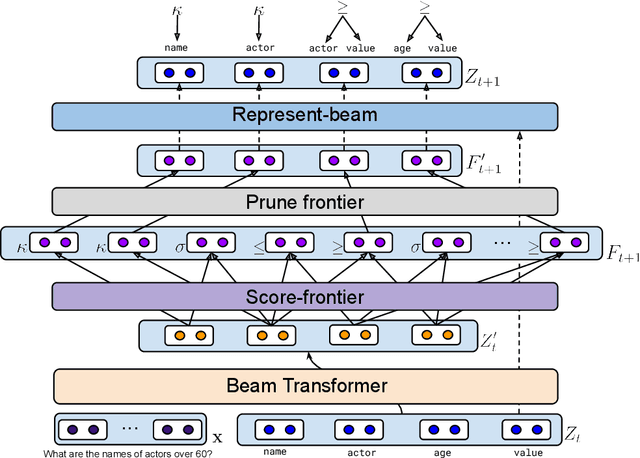
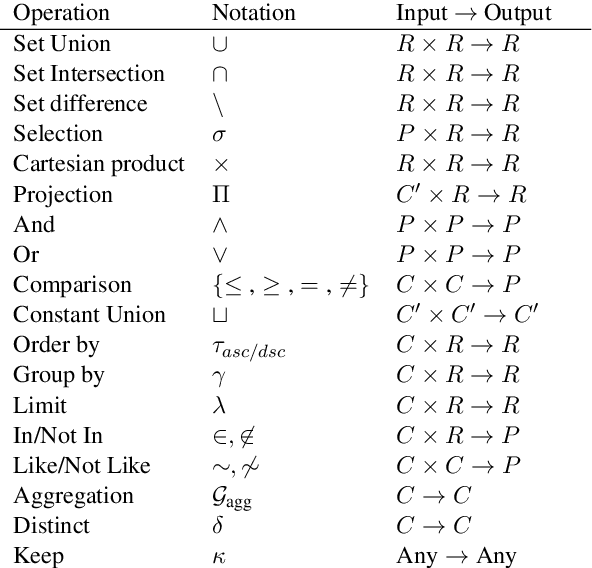
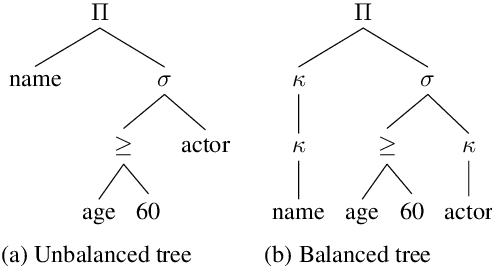

The de-facto standard decoding method for semantic parsing in recent years has been to autoregressively decode the abstract syntax tree of the target program using a top-down depth-first traversal. In this work, we propose an alternative approach: a Semi-autoregressive Bottom-up Parser (SmBoP) that constructs at decoding step $t$ the top-$K$ sub-trees of height $\leq t$. Our parser enjoys several benefits compared to top-down autoregressive parsing. First, since sub-trees in each decoding step are generated in parallel, the theoretical runtime is logarithmic rather than linear. Second, our bottom-up approach learns representations with meaningful semantic sub-programs at each step, rather than semantically vague partial trees. Last, SmBoP includes Transformer-based layers that contextualize sub-trees with one another, allowing us, unlike traditional beam-search, to score trees conditioned on other trees that have been previously explored. We apply SmBoP on Spider, a challenging zero-shot semantic parsing benchmark, and show that SmBoP is competitive with top-down autoregressive parsing. On the test set, SmBoP obtains an EM score of $60.5\%$, similar to the best published score for a model that does not use database content, which is at $60.6\%$.