 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmBoP: Semi-autoregressive Bottom-up Semantic Parsing
Paper and Code
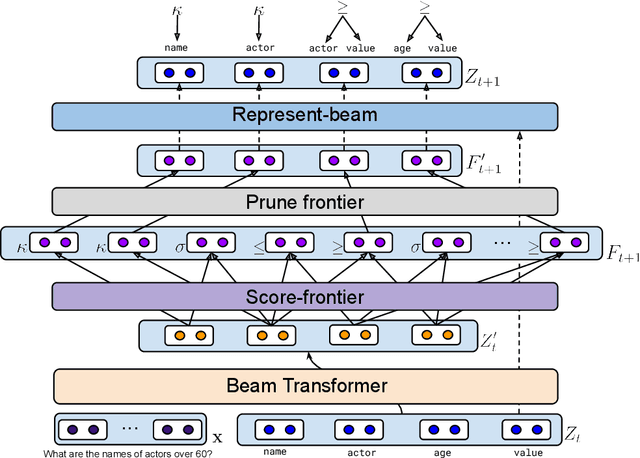
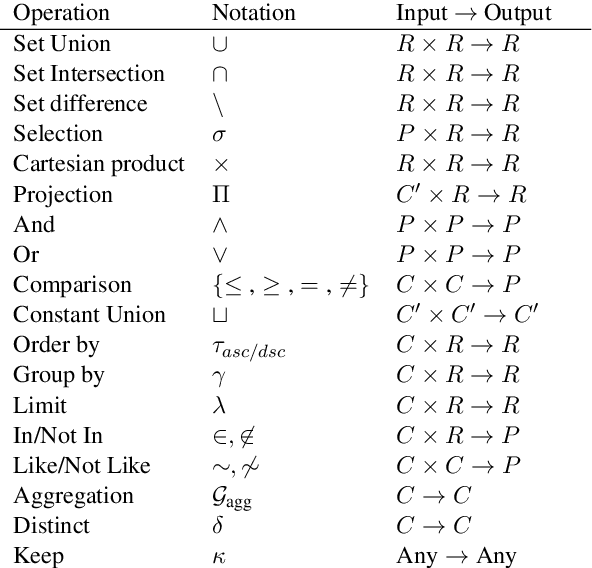
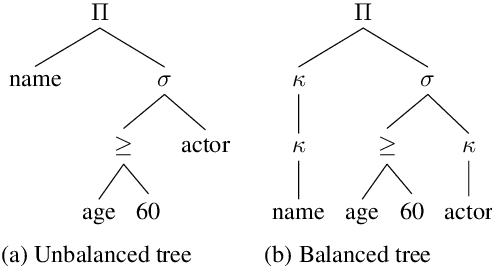

The de-facto standard decoding method for semantic parsing in recent years has been to autoregressively decode the abstract syntax tree of the target program using a top-down depth-first traversal. In this work, we propose an alternative approach: a Semi-autoregressive Bottom-up Parser (SmBoP) that constructs at decoding step $t$ the top-$K$ sub-trees of height $\leq t$. Our parser enjoys several benefits compared to top-down autoregressive parsing. First, since sub-trees in each decoding step are generated in parallel, the theoretical runtime is logarithmic rather than linear. Second, our bottom-up approach learns representations with meaningful semantic sub-programs at each step, rather than semantically vague partial trees. Last, SmBoP includes Transformer-based layers that contextualize sub-trees with one another, allowing us, unlike traditional beam-search, to score trees conditioned on other trees that have been previously explored. We apply SmBoP on Spider, a challenging zero-shot semantic parsing benchmark, and show that SmBoP is competitive with top-down autoregressive parsing. On the test set, SmBoP obtains an EM score of $60.5\%$, similar to the best published score for a model that does not use database content, which is at $60.6\%$.