 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing human and language models sentence processing difficulties on complex structures
Oct 08, 2025Large language models (LLMs) that fluently converse with humans are a reality - but do LLMs experience human-like processing difficulties? We systematically compare human and LLM sentence comprehension across seven challenging linguistic structures. We collect sentence comprehension data from humans and five families of state-of-the-art LLMs, varying in size and training procedure in a unified experimental framework. Our results show LLMs overall struggle on the target structures, but especially on garden path (GP) sentences. Indeed, while the strongest models achieve near perfect accuracy on non-GP structures (93.7% for GPT-5), they struggle on GP structures (46.8% for GPT-5). Additionally, when ranking structures based on average performance, rank correlation between humans and models increases with parameter count. For each target structure, we also collect data for their matched baseline without the difficult structure. Comparing performance on the target vs. baseline sentences, the performance gap observed in humans holds for LLMs, with two exceptions: for models that are too weak performance is uniformly low across both sentence types, and for models that are too strong the performance is uniformly high. Together, these reveal convergence and divergence in human and LLM sentence comprehension, offering new insights into the similarity of humans and LLMs.
When the LM misunderstood the human chuckled: Analyzing garden path effects in humans and language models
Feb 13, 2025Modern Large Language Models (LLMs) have shown human-like abilities in many language tasks, sparking interest in comparing LLMs' and humans' language processing. In this paper, we conduct a detailed comparison of the two on a sentence comprehension task using garden-path constructions, which are notoriously challenging for humans. Based on psycholinguistic research, we formulate hypotheses on why garden-path sentences are hard, and test these hypotheses on human participants and a large suite of LLMs using comprehension questions. Our findings reveal that both LLMs and humans struggle with specific syntactic complexities, with some models showing high correlation with human comprehension. To complement our findings, we test LLM comprehension of garden-path constructions with paraphrasing and text-to-image generation tasks, and find that the results mirror the sentence comprehension question results, further validating our findings on LLM understanding of these constructions.
GLEE: A Unified Framework and Benchmark for Language-based Economic Environments
Oct 07, 2024Large Language Models (LLMs) show significant potential in economic and strategic interactions, where communication via natural language is often prevalent. This raises key questions: Do LLMs behave rationally? Can they mimic human behavior? Do they tend to reach an efficient and fair outcome? What is the role of natural language in the strategic interaction? How do characteristics of the economic environment influence these dynamics? These questions become crucial concerning the economic and societal implications of integrating LLM-based agents into real-world data-driven systems, such as online retail platforms and recommender systems. While the ML community has been exploring the potential of LLMs in such multi-agent setups, varying assumptions, design choices and evaluation criteria across studies make it difficult to draw robust and meaningful conclusions. To address this, we introduce a benchmark for standardizing research on two-player, sequential, language-based games. Inspired by the economic literature, we define three base families of games with consistent parameterization, degrees of freedom and economic measures to evaluate agents' performance (self-gain), as well as the game outcome (efficiency and fairness). We develop an open-source framework for interaction simulation and analysis, and utilize it to collect a dataset of LLM vs. LLM interactions across numerous game configurations and an additional dataset of human vs. LLM interactions. Through extensive experimentation, we demonstrate how our framework and dataset can be used to: (i) compare the behavior of LLM-based agents to human players in various economic contexts; (ii) evaluate agents in both individual and collective performance measures; and (iii) quantify the effect of the economic characteristics of the environments on the behavior of agents.
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?
Jul 22, 2024Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses. We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points. While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero. Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze failures of current systems and highlight that web navigation remains a major challenge.
Large Language Models for Psycholinguistic Plausibility Pretesting
Feb 08, 2024In psycholinguistics, the creation of controlled materials is crucial to ensure that research outcomes are solely attributed to the intended manipulations and not influenced by extraneous factors. To achieve this, psycholinguists typically pretest linguistic materials, where a common pretest is to solicit plausibility judgments from human evaluators on specific sentences. In this work, we investigate whether Language Models (LMs) can be used to generate these plausibility judgements. We investigate a wide range of LMs across multiple linguistic structures and evaluate whether their plausibility judgements correlate with human judgements. We find that GPT-4 plausibility judgements highly correlate with human judgements across the structures we examine, whereas other LMs correlate well with humans on commonly used syntactic structures. We then test whether this correlation implies that LMs can be used instead of humans for pretesting. We find that when coarse-grained plausibility judgements are needed, this works well, but when fine-grained judgements are necessary, even GPT-4 does not provide satisfactory discriminative power.
QAMPARI: : An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs
May 26, 2022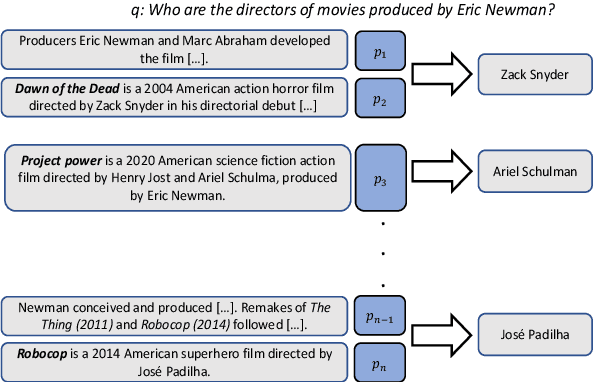

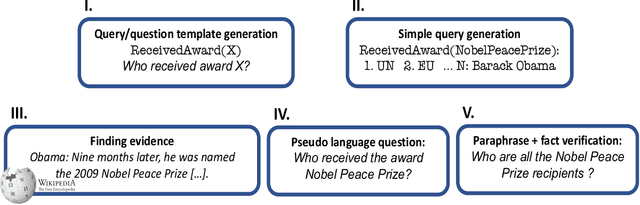
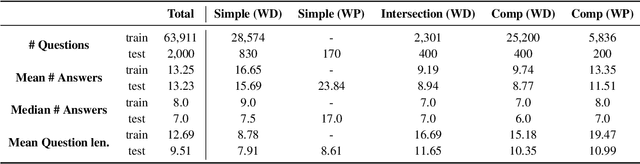
Existing benchmarks for open-domain question answering (ODQA) typically focus on questions whose answers can be extracted from a single paragraph. By contrast, many natural questions, such as "What players were drafted by the Brooklyn Nets?" have a list of answers. Answering such questions requires retrieving and reading from many passages, in a large corpus. We introduce QAMPARI, an ODQA benchmark, where question answers are lists of entities, spread across many paragraphs. We created QAMPARI by (a) generating questions with multiple answers from Wikipedia's knowledge graph and tables, (b) automatically pairing answers with supporting evidence in Wikipedia paragraphs, and (c) manually paraphrasing questions and validating each answer. We train ODQA models from the retrieve-and-read family and find that QAMPARI is challenging in terms of both passage retrieval and answer generation, reaching an F1 score of 26.6 at best. Our results highlight the need for developing ODQA models that handle a broad range of question types, including single and multi-answer questions.