 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Makes Language Models Normative, Not Descriptive
Mar 17, 2026Post-training alignment optimizes language models to match human preference signals, but this objective is not equivalent to modeling observed human behavior. We compare 120 base-aligned model pairs on more than 10,000 real human decisions in multi-round strategic games - bargaining, persuasion, negotiation, and repeated matrix games. In these settings, base models outperform their aligned counterparts in predicting human choices by nearly 10:1, robustly across model families, prompt formulations, and game configurations. This pattern reverses, however, in settings where human behavior is more likely to follow normative predictions: aligned models dominate on one-shot textbook games across all 12 types tested and on non-strategic lottery choices - and even within the multi-round games themselves, at round one, before interaction history develops. This boundary-condition pattern suggests that alignment induces a normative bias: it improves prediction when human behavior is relatively well captured by normative solutions, but hurts prediction in multi-round strategic settings, where behavior is shaped by descriptive dynamics such as reciprocity, retaliation, and history-dependent adaptation. These results reveal a fundamental trade-off between optimizing models for human use and using them as proxies for human behavior.
Addressing Corpus Knowledge Poisoning Attacks on RAG Using Sparse Attention
Feb 05, 2026Retrieval Augmented Generation (RAG) is a highly effective paradigm for keeping LLM-based responses up-to-date and reducing the likelihood of hallucinations. Yet, RAG was recently shown to be quite vulnerable to corpus knowledge poisoning: an attacker injects misleading documents to the corpus to steer an LLM's output to an undesired response. We argue that the standard causal attention mechanism in LLMs enables harmful cross-document interactions, specifically in cases of attacks. Accordingly, we introduce a novel defense approach for RAG: Sparse Document Attention RAG (SDAG). This is a block-sparse attention mechanism that disallows cross-attention between retrieved documents. SDAG requires a minimal inference-time change to the attention mask; furthermore, no fine-tuning or additional architectural changes are needed. We present an empirical evaluation of LLM-based question answering (QA) with a variety of attack strategies on RAG. We show that our SDAG method substantially outperforms the standard causal attention mechanism in terms of attack success rate. We further demonstrate the clear merits of integrating SDAG with state-of-the-art RAG defense methods. Specifically, the integration results in performance that is statistically significantly better than the state-of-the-art.
The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents
Jan 16, 2026The integration of AI agents into economic markets fundamentally alters the landscape of strategic interaction. We investigate the economic implications of expanding the set of available technologies in three canonical game-theoretic settings: bargaining (resource division), negotiation (asymmetric information trade), and persuasion (strategic information transmission). We find that simply increasing the choice of AI delegates can drastically shift equilibrium payoffs and regulatory outcomes, often creating incentives for regulators to proactively develop and release technologies. Conversely, we identify a strategic phenomenon termed the "Poisoned Apple" effect: an agent may release a new technology, which neither they nor their opponent ultimately uses, solely to manipulate the regulator's choice of market design in their favor. This strategic release improves the releaser's welfare at the expense of their opponent and the regulator's fairness objectives. Our findings demonstrate that static regulatory frameworks are vulnerable to manipulation via technology expansion, necessitating dynamic market designs that adapt to the evolving landscape of AI capabilities.
On the Merits of LLM-Based Corpus Enrichment
Jun 06, 2025Generative AI (genAI) technologies -- specifically, large language models (LLMs) -- and search have evolving relations. We argue for a novel perspective: using genAI to enrich a document corpus so as to improve query-based retrieval effectiveness. The enrichment is based on modifying existing documents or generating new ones. As an empirical proof of concept, we use LLMs to generate documents relevant to a topic which are more retrievable than existing ones. In addition, we demonstrate the potential merits of using corpus enrichment for retrieval augmented generation (RAG) and answer attribution in question answering.
Fairness under Competition
May 22, 2025



Algorithmic fairness has emerged as a central issue in ML, and it has become standard practice to adjust ML algorithms so that they will satisfy fairness requirements such as Equal Opportunity. In this paper we consider the effects of adopting such fair classifiers on the overall level of ecosystem fairness. Specifically, we introduce the study of fairness with competing firms, and demonstrate the failure of fair classifiers in yielding fair ecosystems. Our results quantify the loss of fairness in systems, under a variety of conditions, based on classifiers' correlation and the level of their data overlap. We show that even if competing classifiers are individually fair, the ecosystem's outcome may be unfair; and that adjusting biased algorithms to improve their individual fairness may lead to an overall decline in ecosystem fairness. In addition to these theoretical results, we also provide supporting experimental evidence. Together, our model and results provide a novel and essential call for action.
Data Sharing with a Generative AI Competitor
May 18, 2025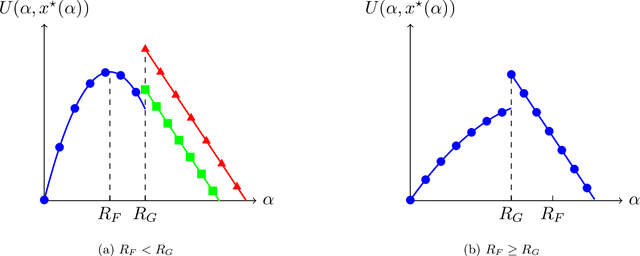
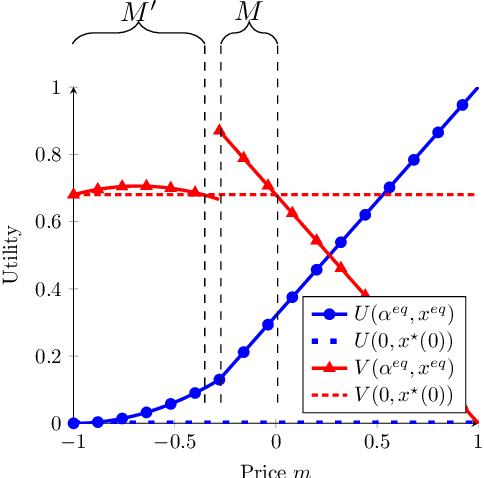
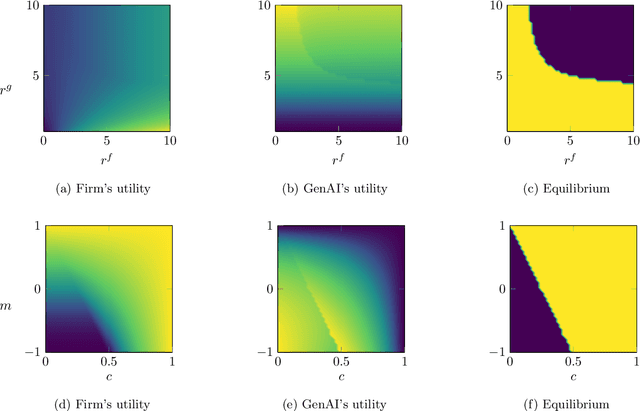
As GenAI platforms grow, their dependence on content from competing providers, combined with access to alternative data sources, creates new challenges for data-sharing decisions. In this paper, we provide a model of data sharing between a content creation firm and a GenAI platform that can also acquire content from third-party experts. The interaction is modeled as a Stackelberg game: the firm first decides how much of its proprietary dataset to share with GenAI, and GenAI subsequently determines how much additional data to acquire from external experts. Their utilities depend on user traffic, monetary transfers, and the cost of acquiring additional data from external experts. We characterize the unique subgame perfect equilibrium of the game and uncover a surprising phenomenon: The firm may be willing to pay GenAI to share the firm's own data, leading to a costly data-sharing equilibrium. We further characterize the set of Pareto improving data prices, and show that such improvements occur only when the firm pays to share data. Finally, we study how the price can be set to optimize different design objectives, such as promoting firm data sharing, expert data acquisition, or a balance of both. Our results shed light on the economic forces shaping data-sharing partnerships in the age of GenAI, and provide guidance for platforms, regulators and policymakers seeking to design effective data exchange mechanisms.
A Multi-Agent Perspective on Modern Information Retrieval
Feb 20, 2025The rise of large language models (LLMs) has introduced a new era in information retrieval (IR), where queries and documents that were once assumed to be generated exclusively by humans can now also be created by automated agents. These agents can formulate queries, generate documents, and perform ranking. This shift challenges some long-standing IR paradigms and calls for a reassessment of both theoretical frameworks and practical methodologies. We advocate for a multi-agent perspective to better capture the complex interactions between query agents, document agents, and ranker agents. Through empirical exploration of various multi-agent retrieval settings, we reveal the significant impact of these interactions on system performance. Our findings underscore the need to revisit classical IR paradigms and develop new frameworks for more effective modeling and evaluation of modern retrieval systems.
Prompt-Based Document Modifications In Ranking Competitions
Feb 11, 2025We study prompting-based approaches with Large Language Models (LLMs) for modifying documents so as to promote their ranking in a competitive search setting. Our methods are inspired by prior work on leveraging LLMs as rankers. We evaluate our approach by deploying it as a bot in previous ranking competitions and in competitions we organized. Our findings demonstrate that our approach effectively improves document ranking while preserving high levels of faithfulness to the original content and maintaining overall document quality.
Search results diversification in competitive search
Jan 24, 2025In Web retrieval, there are many cases of competition between authors of Web documents: their incentive is to have their documents highly ranked for queries of interest. As such, the Web is a prominent example of a competitive search setting. Past work on competitive search focused on ranking functions based solely on relevance estimation. We study ranking functions that integrate a results-diversification aspect. We show that the competitive search setting with diversity-based ranking has an equilibrium. Furthermore, we theoretically and empirically show that the phenomenon of authors mimicking content in documents highly ranked in the past, which was demonstrated in previous work, is mitigated when search results diversification is applied.
GLEE: A Unified Framework and Benchmark for Language-based Economic Environments
Oct 07, 2024Large Language Models (LLMs) show significant potential in economic and strategic interactions, where communication via natural language is often prevalent. This raises key questions: Do LLMs behave rationally? Can they mimic human behavior? Do they tend to reach an efficient and fair outcome? What is the role of natural language in the strategic interaction? How do characteristics of the economic environment influence these dynamics? These questions become crucial concerning the economic and societal implications of integrating LLM-based agents into real-world data-driven systems, such as online retail platforms and recommender systems. While the ML community has been exploring the potential of LLMs in such multi-agent setups, varying assumptions, design choices and evaluation criteria across studies make it difficult to draw robust and meaningful conclusions. To address this, we introduce a benchmark for standardizing research on two-player, sequential, language-based games. Inspired by the economic literature, we define three base families of games with consistent parameterization, degrees of freedom and economic measures to evaluate agents' performance (self-gain), as well as the game outcome (efficiency and fairness). We develop an open-source framework for interaction simulation and analysis, and utilize it to collect a dataset of LLM vs. LLM interactions across numerous game configurations and an additional dataset of human vs. LLM interactions. Through extensive experimentation, we demonstrate how our framework and dataset can be used to: (i) compare the behavior of LLM-based agents to human players in various economic contexts; (ii) evaluate agents in both individual and collective performance measures; and (iii) quantify the effect of the economic characteristics of the environments on the behavior of agents.