 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Corpus Knowledge Poisoning Attacks on RAG Using Sparse Attention
Feb 05, 2026Retrieval Augmented Generation (RAG) is a highly effective paradigm for keeping LLM-based responses up-to-date and reducing the likelihood of hallucinations. Yet, RAG was recently shown to be quite vulnerable to corpus knowledge poisoning: an attacker injects misleading documents to the corpus to steer an LLM's output to an undesired response. We argue that the standard causal attention mechanism in LLMs enables harmful cross-document interactions, specifically in cases of attacks. Accordingly, we introduce a novel defense approach for RAG: Sparse Document Attention RAG (SDAG). This is a block-sparse attention mechanism that disallows cross-attention between retrieved documents. SDAG requires a minimal inference-time change to the attention mask; furthermore, no fine-tuning or additional architectural changes are needed. We present an empirical evaluation of LLM-based question answering (QA) with a variety of attack strategies on RAG. We show that our SDAG method substantially outperforms the standard causal attention mechanism in terms of attack success rate. We further demonstrate the clear merits of integrating SDAG with state-of-the-art RAG defense methods. Specifically, the integration results in performance that is statistically significantly better than the state-of-the-art.
On the Merits of LLM-Based Corpus Enrichment
Jun 06, 2025Generative AI (genAI) technologies -- specifically, large language models (LLMs) -- and search have evolving relations. We argue for a novel perspective: using genAI to enrich a document corpus so as to improve query-based retrieval effectiveness. The enrichment is based on modifying existing documents or generating new ones. As an empirical proof of concept, we use LLMs to generate documents relevant to a topic which are more retrievable than existing ones. In addition, we demonstrate the potential merits of using corpus enrichment for retrieval augmented generation (RAG) and answer attribution in question answering.
A Multi-Agent Perspective on Modern Information Retrieval
Feb 20, 2025The rise of large language models (LLMs) has introduced a new era in information retrieval (IR), where queries and documents that were once assumed to be generated exclusively by humans can now also be created by automated agents. These agents can formulate queries, generate documents, and perform ranking. This shift challenges some long-standing IR paradigms and calls for a reassessment of both theoretical frameworks and practical methodologies. We advocate for a multi-agent perspective to better capture the complex interactions between query agents, document agents, and ranker agents. Through empirical exploration of various multi-agent retrieval settings, we reveal the significant impact of these interactions on system performance. Our findings underscore the need to revisit classical IR paradigms and develop new frameworks for more effective modeling and evaluation of modern retrieval systems.
Prompt-Based Document Modifications In Ranking Competitions
Feb 11, 2025We study prompting-based approaches with Large Language Models (LLMs) for modifying documents so as to promote their ranking in a competitive search setting. Our methods are inspired by prior work on leveraging LLMs as rankers. We evaluate our approach by deploying it as a bot in previous ranking competitions and in competitions we organized. Our findings demonstrate that our approach effectively improves document ranking while preserving high levels of faithfulness to the original content and maintaining overall document quality.
Search results diversification in competitive search
Jan 24, 2025In Web retrieval, there are many cases of competition between authors of Web documents: their incentive is to have their documents highly ranked for queries of interest. As such, the Web is a prominent example of a competitive search setting. Past work on competitive search focused on ranking functions based solely on relevance estimation. We study ranking functions that integrate a results-diversification aspect. We show that the competitive search setting with diversity-based ranking has an equilibrium. Furthermore, we theoretically and empirically show that the phenomenon of authors mimicking content in documents highly ranked in the past, which was demonstrated in previous work, is mitigated when search results diversification is applied.
Competitive Retrieval: Going Beyond the Single Query
Apr 14, 2024Previous work on the competitive retrieval setting focused on a single-query setting: document authors manipulate their documents so as to improve their future ranking for a given query. We study a competitive setting where authors opt to improve their document's ranking for multiple queries. We use game theoretic analysis to prove that equilibrium does not necessarily exist. We then empirically show that it is more difficult for authors to improve their documents' rankings for multiple queries with a neural ranker than with a state-of-the-art feature-based ranker. We also present an effective approach for predicting the document most highly ranked in the next induced ranking.
A Dataset for Sentence Retrieval for Open-Ended Dialogues
May 24, 2022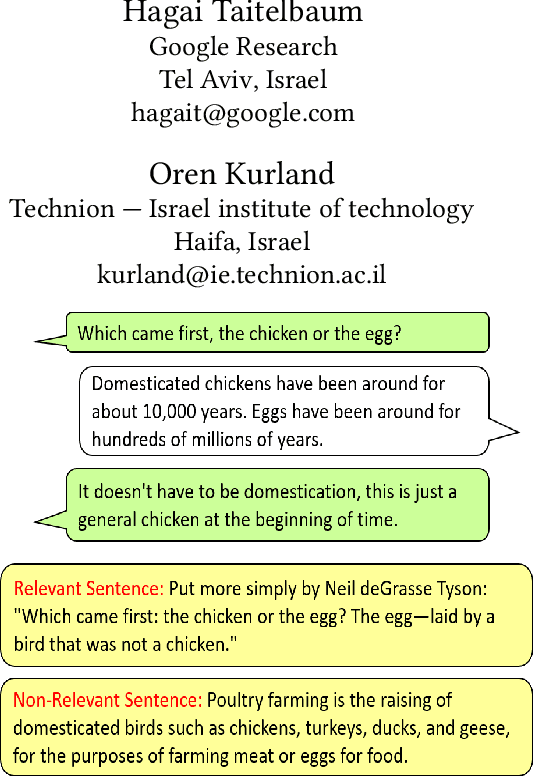

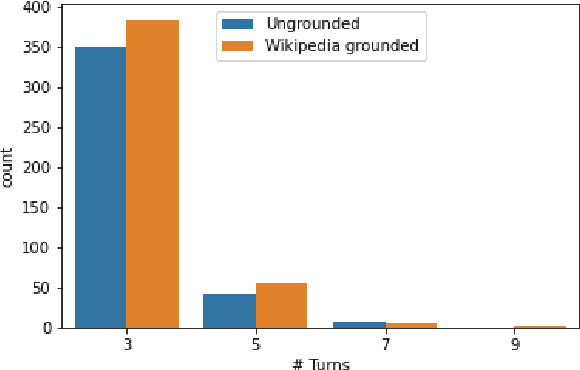
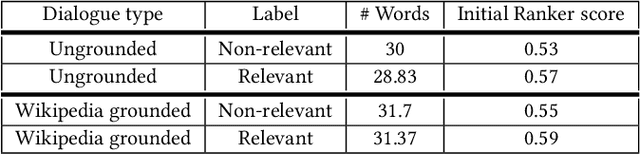
We address the task of sentence retrieval for open-ended dialogues. The goal is to retrieve sentences from a document corpus that contain information useful for generating the next turn in a given dialogue. Prior work on dialogue-based retrieval focused on specific types of dialogues: either conversational QA or conversational search. To address a broader scope of this task where any type of dialogue can be used, we constructed a dataset that includes open-ended dialogues from Reddit, candidate sentences from Wikipedia for each dialogue and human annotations for the sentences. We report the performance of several retrieval baselines, including neural retrieval models, over the dataset. To adapt neural models to the types of dialogues in the dataset, we explored an approach to induce a large-scale weakly supervised training data from Reddit. Using this training set significantly improved the performance over training on the MS MARCO dataset.
Driving the Herd: Search Engines as Content Influencers
Oct 21, 2021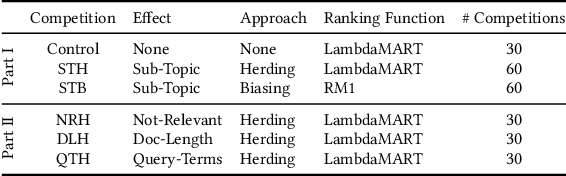
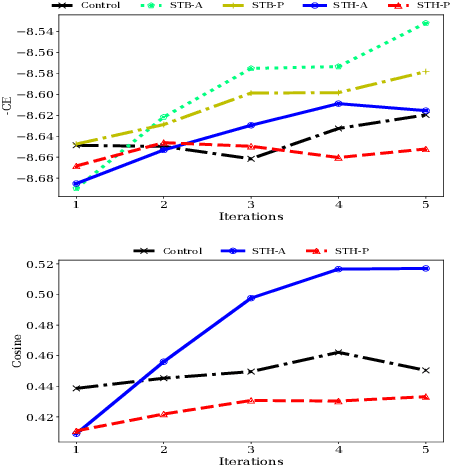

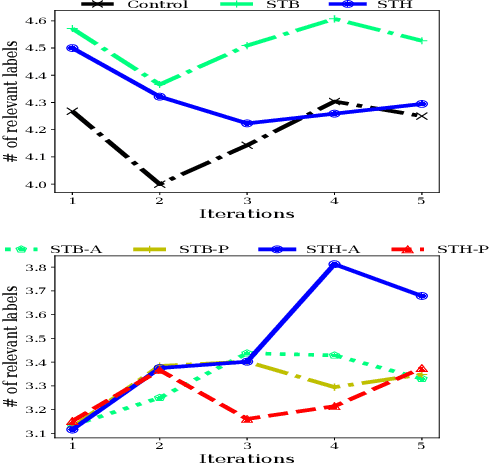
In competitive search settings such as the Web, many documents' authors (publishers) opt to have their documents highly ranked for some queries. To this end, they modify the documents - specifically, their content - in response to induced rankings. Thus, the search engine affects the content in the corpus via its ranking decisions. We present a first study of the ability of search engines to drive pre-defined, targeted, content effects in the corpus using simple techniques. The first is based on the herding phenomenon - a celebrated result from the economics literature - and the second is based on biasing the relevance ranking function. The types of content effects we study are either topical or touch on specific document properties - length and inclusion of query terms. Analysis of ranking competitions we organized between incentivized publishers shows that the types of content effects we target can indeed be attained by applying our suggested techniques. These findings have important implications with regard to the role of search engines in shaping the corpus.
Respect My Authority! HITS Without Hyperlinks, Utilizing Cluster-Based Language Models
Apr 22, 2008

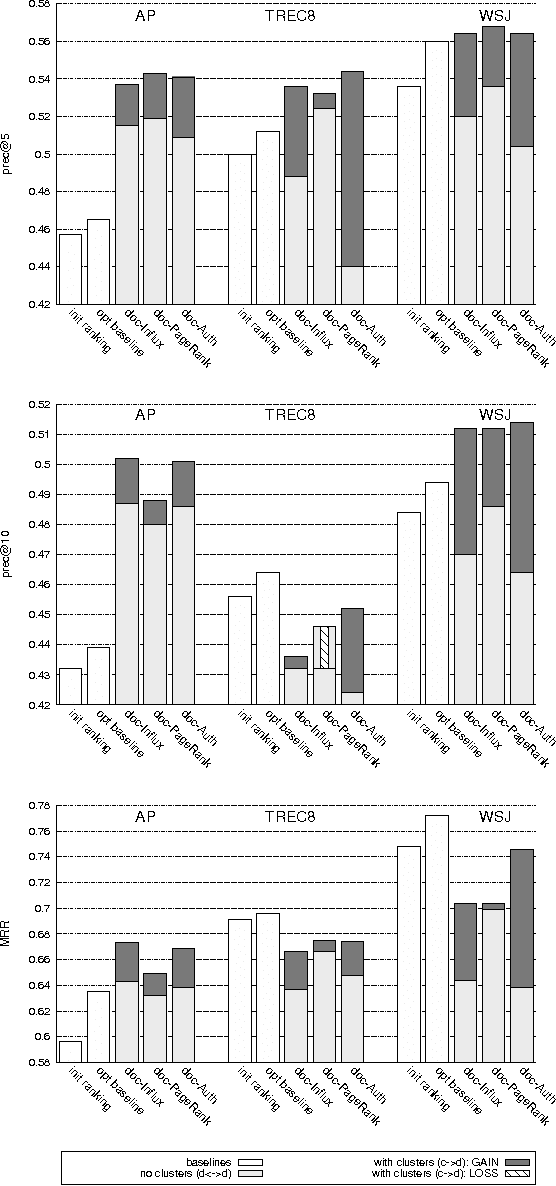
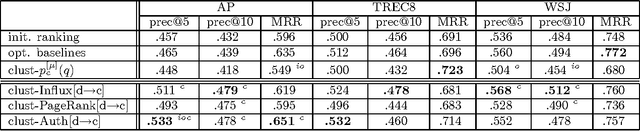
We present an approach to improving the precision of an initial document ranking wherein we utilize cluster information within a graph-based framework. The main idea is to perform re-ranking based on centrality within bipartite graphs of documents (on one side) and clusters (on the other side), on the premise that these are mutually reinforcing entities. Links between entities are created via consideration of language models induced from them. We find that our cluster-document graphs give rise to much better retrieval performance than previously proposed document-only graphs do. For example, authority-based re-ranking of documents via a HITS-style cluster-based approach outperforms a previously-proposed PageRank-inspired algorithm applied to solely-document graphs. Moreover, we also show that computing authority scores for clusters constitutes an effective method for identifying clusters containing a large percentage of relevant documents.
Better than the real thing? Iterative pseudo-query processing using cluster-based language models
Jan 11, 2006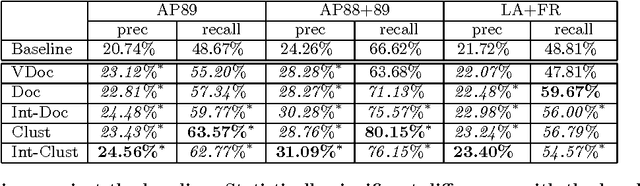
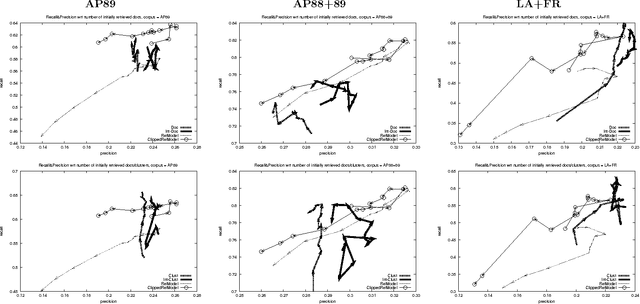
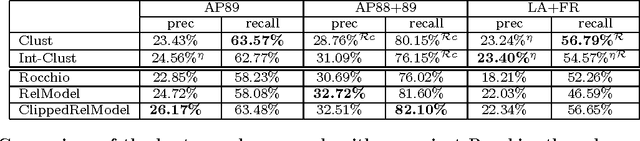
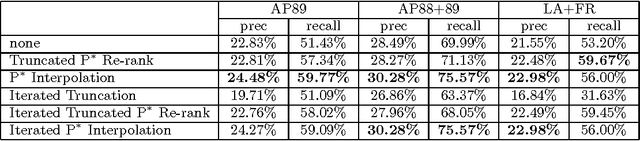
We present a novel approach to pseudo-feedback-based ad hoc retrieval that uses language models induced from both documents and clusters. First, we treat the pseudo-feedback documents produced in response to the original query as a set of pseudo-queries that themselves can serve as input to the retrieval process. Observing that the documents returned in response to the pseudo-queries can then act as pseudo-queries for subsequent rounds, we arrive at a formulation of pseudo-query-based retrieval as an iterative process. Experiments show that several concrete instantiations of this idea, when applied in conjunction with techniques designed to heighten precision, yield performance results rivaling those of a number of previously-proposed algorithms, including the standard language-modeling approach. The use of cluster-based language models is a key contributing factor to our algorithms' success.