 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespect My Authority! HITS Without Hyperlinks, Utilizing Cluster-Based Language Models
Paper and Code
Apr 22, 2008

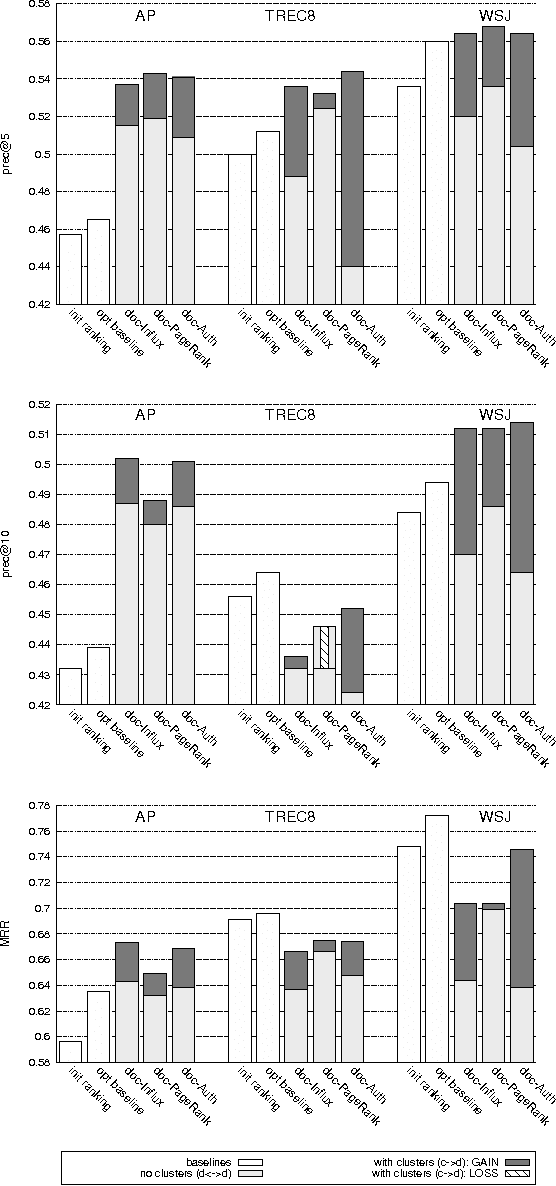
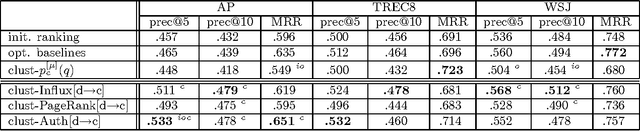
We present an approach to improving the precision of an initial document ranking wherein we utilize cluster information within a graph-based framework. The main idea is to perform re-ranking based on centrality within bipartite graphs of documents (on one side) and clusters (on the other side), on the premise that these are mutually reinforcing entities. Links between entities are created via consideration of language models induced from them. We find that our cluster-document graphs give rise to much better retrieval performance than previously proposed document-only graphs do. For example, authority-based re-ranking of documents via a HITS-style cluster-based approach outperforms a previously-proposed PageRank-inspired algorithm applied to solely-document graphs. Moreover, we also show that computing authority scores for clusters constitutes an effective method for identifying clusters containing a large percentage of relevant documents.