 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Sentence Retrieval for Open-Ended Dialogues
May 24, 2022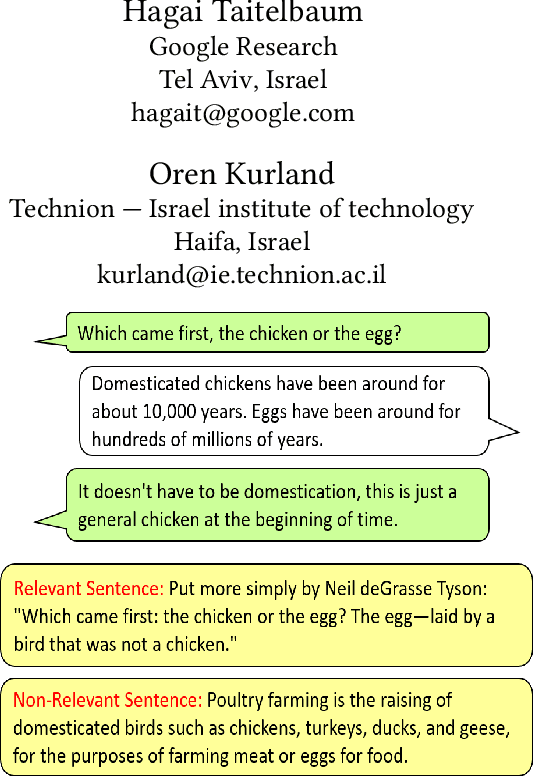

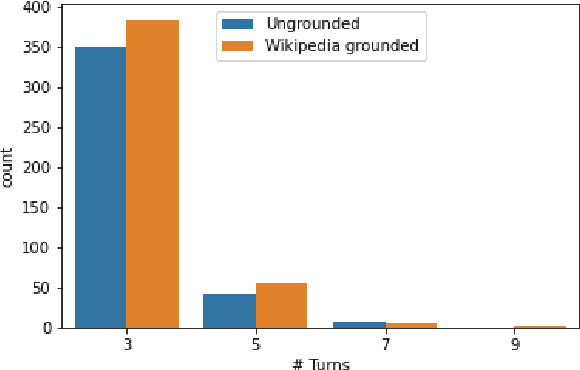
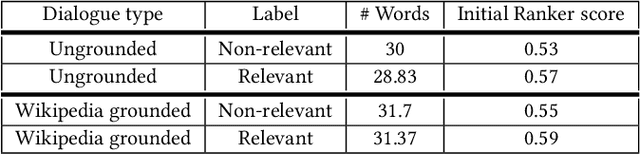
We address the task of sentence retrieval for open-ended dialogues. The goal is to retrieve sentences from a document corpus that contain information useful for generating the next turn in a given dialogue. Prior work on dialogue-based retrieval focused on specific types of dialogues: either conversational QA or conversational search. To address a broader scope of this task where any type of dialogue can be used, we constructed a dataset that includes open-ended dialogues from Reddit, candidate sentences from Wikipedia for each dialogue and human annotations for the sentences. We report the performance of several retrieval baselines, including neural retrieval models, over the dataset. To adapt neural models to the types of dialogues in the dataset, we explored an approach to induce a large-scale weakly supervised training data from Reddit. Using this training set significantly improved the performance over training on the MS MARCO dataset.