 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitive Retrieval: Going Beyond the Single Query
Apr 14, 2024Previous work on the competitive retrieval setting focused on a single-query setting: document authors manipulate their documents so as to improve their future ranking for a given query. We study a competitive setting where authors opt to improve their document's ranking for multiple queries. We use game theoretic analysis to prove that equilibrium does not necessarily exist. We then empirically show that it is more difficult for authors to improve their documents' rankings for multiple queries with a neural ranker than with a state-of-the-art feature-based ranker. We also present an effective approach for predicting the document most highly ranked in the next induced ranking.
Driving the Herd: Search Engines as Content Influencers
Oct 21, 2021
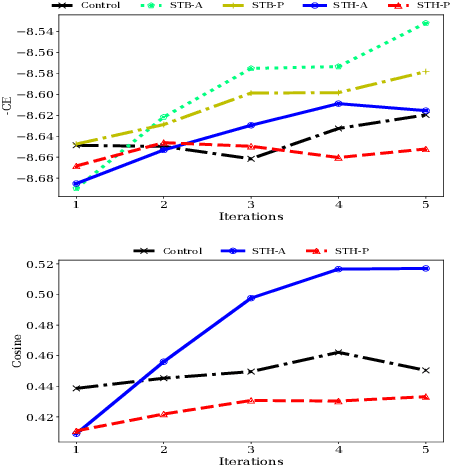

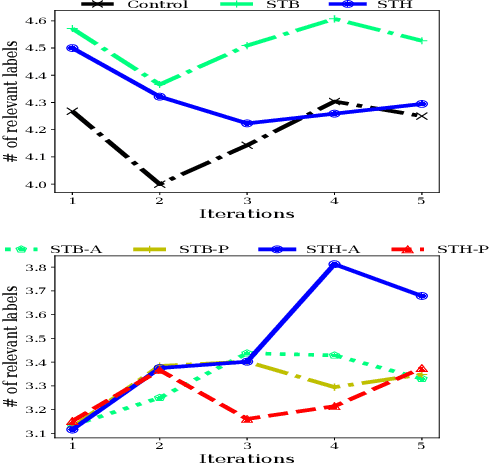
In competitive search settings such as the Web, many documents' authors (publishers) opt to have their documents highly ranked for some queries. To this end, they modify the documents - specifically, their content - in response to induced rankings. Thus, the search engine affects the content in the corpus via its ranking decisions. We present a first study of the ability of search engines to drive pre-defined, targeted, content effects in the corpus using simple techniques. The first is based on the herding phenomenon - a celebrated result from the economics literature - and the second is based on biasing the relevance ranking function. The types of content effects we study are either topical or touch on specific document properties - length and inclusion of query terms. Analysis of ranking competitions we organized between incentivized publishers shows that the types of content effects we target can indeed be attained by applying our suggested techniques. These findings have important implications with regard to the role of search engines in shaping the corpus.