 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuickScope: Certifying Hard Questions in Dynamic LLM Benchmarks
Apr 20, 2026LLM benchmarks are increasingly dynamic: instead of containing a fixed set of questions, they define templates and parameters that can generate an effectively unlimited number of question variants. This flexibility is valuable, but it makes evaluation expensive -- especially when the goal is not just determining an average score, but reliably identifying a model's weak spots. This paper introduces a new methodology for identifying hard questions in dynamic benchmarks. It leverages COUP, a recent Bayesian optimization algorithm (Graham, Velez & Leyton-Brown, 2026), after introducing several substantive modifications to make the algorithm suitable for practical LLM pipelines. We also wrap it in a tool that supports flexible choices of datasets and utility functions, enabling users to target the kinds of questions they care about (e.g., low-accuracy questions; questions that are unusually hard relative to their measured complexity). In experiments across a range of benchmarks, we show that our method, dubbed $\texttt{QuickScope}$, discovers truly difficult questions more sample efficiently than standard baselines, while also reducing false positives from noisy outcomes.
STEER-ME: Assessing the Microeconomic Reasoning of Large Language Models
Feb 19, 2025



How should one judge whether a given large language model (LLM) can reliably perform economic reasoning? Most existing LLM benchmarks focus on specific applications and fail to present the model with a rich variety of economic tasks. A notable exception is Raman et al. [2024], who offer an approach for comprehensively benchmarking strategic decision-making; however, this approach fails to address the non-strategic settings prevalent in microeconomics, such as supply-and-demand analysis. We address this gap by taxonomizing microeconomic reasoning into $58$ distinct elements, focusing on the logic of supply and demand, each grounded in up to $10$ distinct domains, $5$ perspectives, and $3$ types. The generation of benchmark data across this combinatorial space is powered by a novel LLM-assisted data generation protocol that we dub auto-STEER, which generates a set of questions by adapting handwritten templates to target new domains and perspectives. Because it offers an automated way of generating fresh questions, auto-STEER mitigates the risk that LLMs will be trained to over-fit evaluation benchmarks; we thus hope that it will serve as a useful tool both for evaluating and fine-tuning models for years to come. We demonstrate the usefulness of our benchmark via a case study on $27$ LLMs, ranging from small open-source models to the current state of the art. We examined each model's ability to solve microeconomic problems across our whole taxonomy and present the results across a range of prompting strategies and scoring metrics.
Rationality Report Cards: Assessing the Economic Rationality of Large Language Models
Feb 14, 2024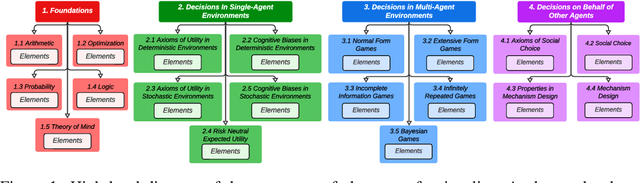
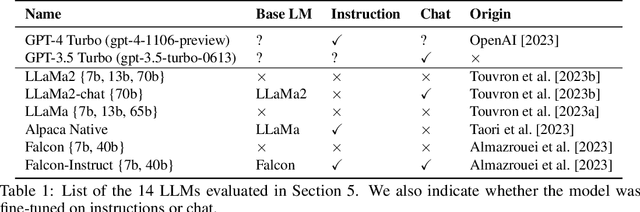

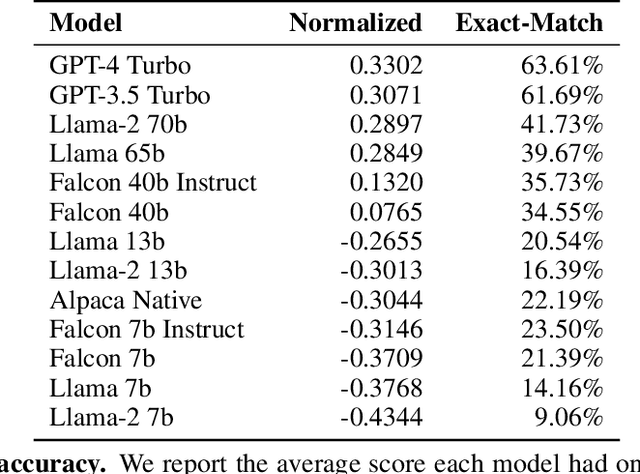
There is increasing interest in using LLMs as decision-making "agents." Doing so includes many degrees of freedom: which model should be used; how should it be prompted; should it be asked to introspect, conduct chain-of-thought reasoning, etc? Settling these questions -- and more broadly, determining whether an LLM agent is reliable enough to be trusted -- requires a methodology for assessing such an agent's economic rationality. In this paper, we provide one. We begin by surveying the economic literature on rational decision making, taxonomizing a large set of fine-grained "elements" that an agent should exhibit, along with dependencies between them. We then propose a benchmark distribution that quantitatively scores an LLMs performance on these elements and, combined with a user-provided rubric, produces a "rationality report card." Finally, we describe the results of a large-scale empirical experiment with 14 different LLMs, characterizing the both current state of the art and the impact of different model sizes on models' ability to exhibit rational behavior.
Monte Carlo Forest Search: UNSAT Solver Synthesis via Reinforcement learning
Nov 22, 2022We introduce Monte Carlo Forest Search (MCFS), an offline algorithm for automatically synthesizing strong tree-search solvers for proving \emph{unsatisfiability} on given distributions, leveraging ideas from the Monte Carlo Tree Search (MCTS) algorithm that led to breakthroughs in AlphaGo. The crucial difference between proving unsatisfiability and existing applications of MCTS, is that policies produce trees rather than paths. Rather than finding a good path (solution) within a tree, the search problem becomes searching for a small proof tree within a forest of candidate proof trees. We introduce two key ideas to adapt to this setting. First, we estimate tree size with paths, via the unbiased approximation from Knuth (1975). Second, we query a strong solver at a user-defined depth rather than learning a policy across the whole tree, in order to focus our policy search on early decisions, which offer the greatest potential for reducing tree size. We then present MCFS-SAT, an implementation of MCFS for learning branching policies for solving the Boolean satisfiability (SAT) problem that required many modifications from AlphaGo. We matched or improved performance over a strong baseline on two well-known SAT distributions (\texttt{sgen}, \texttt{random}). Notably, we improved running time by 9\% on \texttt{sgen} over the \texttt{kcnfs} solver and even further over the strongest UNSAT solver from the 2021 SAT competition.
The Perils of Learning Before Optimizing
Jun 18, 2021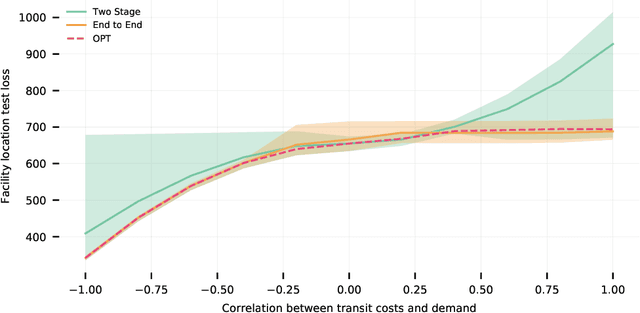
Formulating real-world optimization problems often begins with making predictions from historical data (e.g., an optimizer that aims to recommend fast routes relies upon travel-time predictions). Typically, learning the prediction model used to generate the optimization problem and solving that problem are performed in two separate stages. Recent work has showed how such prediction models can be learned end-to-end by differentiating through the optimization task. Such methods often yield empirical improvements, which are typically attributed to end-to-end making better error tradeoffs than the standard loss function used in a two-stage solution. We refine this explanation and more precisely characterize when end-to-end can improve performance. When prediction targets are stochastic, a two-stage solution must make an a priori choice about which statistics of the target distribution to model -- we consider expectations over prediction targets -- while an end-to-end solution can make this choice adaptively. We show that the performance gap between a two-stage and end-to-end approach is closely related to the \emph{price of correlation} concept in stochastic optimization and show the implications of some existing POC results for our predict-then-optimize problem. We then consider a novel and particularly practical setting, where coefficients in the objective function depend on multiple prediction targets. We give explicit constructions where (1) two-stage performs unboundedly worse than end-to-end; and (2) two-stage is optimal. We identify a large set of real-world applications whose objective functions rely on multiple prediction targets but which nevertheless deploy two-stage solutions. We also use simulations to experimentally quantify performance gaps.
Smarter Parking: Using AI to Identify Parking Inefficiencies in Vancouver
Mar 21, 2020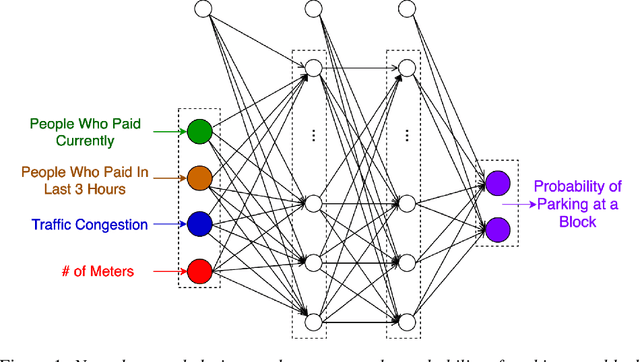
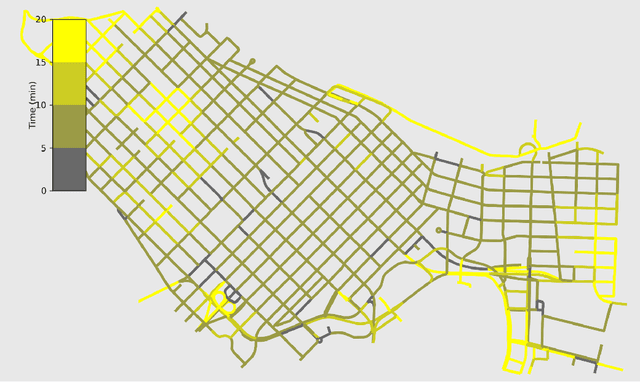
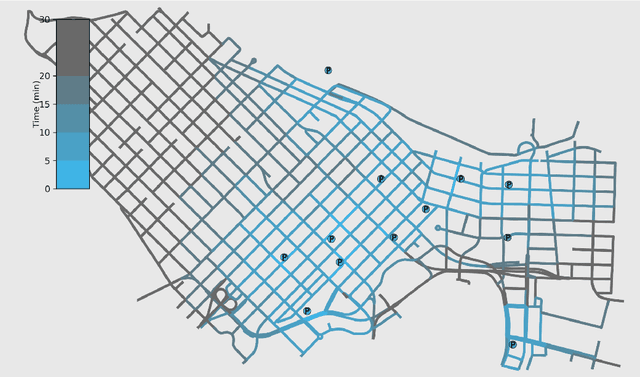
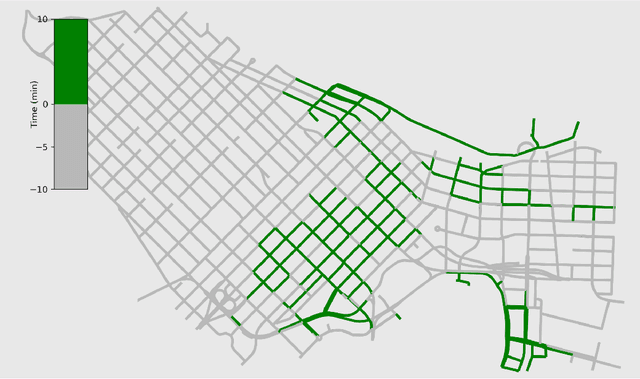
On-street parking is convenient, but has many disadvantages: on-street spots come at the expense of other road uses such as traffic lanes, transit lanes, bike lanes, or parklets; drivers looking for parking contribute substantially to traffic congestion and hence to greenhouse gas emissions; safety is reduced both due to the fact that drivers looking for spots are more distracted than other road users and that people exiting parked cars pose a risk to cyclists. These social costs may not be worth paying when off-street parking lots are nearby and have surplus capacity. To see where this might be true in downtown Vancouver, we used artificial intelligence techniques to estimate the amount of time it would take drivers to both park on and off street for destinations throughout the city. For on-street parking, we developed (1) a deep-learning model of block-by-block parking availability based on data from parking meters and audits and (2) a computational simulation of drivers searching for an on-street spot. For off-street parking, we developed a computational simulation of the time it would take drivers drive from their original destination to the nearest city-owned off-street lot and then to queue for a spot based on traffic and lot occupancy data. Finally, in both cases we also computed the time it would take the driver to walk from their parking spot to their original destination. We compared these time estimates for destinations in each block of Vancouver's downtown core and each hour of the day. We found many areas where off street would actually save drivers time over searching the streets for a spot, and many more where the time cost for parking off street was small. The identification of such areas provides an opportunity for the city to repurpose valuable curbside space for community-friendly uses more in line with its transportation goals.