 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentive-Compatible Recovery from Manipulated Signals, with Applications to Decentralized Physical Infrastructure
Mar 10, 2025We introduce the first formal model capturing the elicitation of unverifiable information from a party (the "source") with implicit signals derived by other players (the "observers"). Our model is motivated in part by applications in decentralized physical infrastructure networks (a.k.a. "DePIN"), an emerging application domain in which physical services (e.g., sensor information, bandwidth, or energy) are provided at least in part by untrusted and self-interested parties. A key challenge in these signal network applications is verifying the level of service that was actually provided by network participants. We first establish a condition called source identifiability, which we show is necessary for the existence of a mechanism for which truthful signal reporting is a strict equilibrium. For a converse, we build on techniques from peer prediction to show that in every signal network that satisfies the source identifiability condition, there is in fact a strictly truthful mechanism, where truthful signal reporting gives strictly higher total expected payoff than any less informative equilibrium. We furthermore show that this truthful equilibrium is in fact the unique equilibrium of the mechanism if there is positive probability that any one observer is unconditionally honest (e.g., if an observer were run by the network owner). Also, by extending our condition to coalitions, we show that there are generally no collusion-resistant mechanisms in the settings that we consider. We apply our framework and results to two DePIN applications: proving location, and proving bandwidth. In the location-proving setting observers learn (potentially enlarged) Euclidean distances to the source. Here, our condition has an appealing geometric interpretation, implying that the source's location can be truthfully elicited if and only if it is guaranteed to lie inside the convex hull of the observers.
The Harvard USPTO Patent Dataset: A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications
Jul 08, 2022


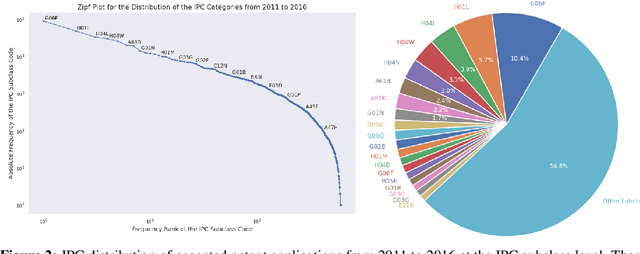
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Although the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, ML offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike previously proposed patent datasets in NLP, HUPD contains the inventor-submitted versions of patent applications--not the final versions of granted patents--thereby allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured metadata alongside the text of patent filings: By providing each application's metadata along with all of its text fields, the dataset enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on the types of research HUPD makes possible, we introduce a new task to the NLP community--namely, binary classification of patent decisions. We additionally show the structured metadata provided in the dataset enables us to conduct explicit studies of concept shifts for this task. Finally, we demonstrate how HUPD can be used for three additional tasks: multi-class classification of patent subject areas, language modeling, and summarization.
Recommending with Recommendations
Dec 02, 2021Recommendation systems are a key modern application of machine learning, but they have the downside that they often draw upon sensitive user information in making their predictions. We show how to address this deficiency by basing a service's recommendation engine upon recommendations from other existing services, which contain no sensitive information by nature. Specifically, we introduce a contextual multi-armed bandit recommendation framework where the agent has access to recommendations for other services. In our setting, the user's (potentially sensitive) information belongs to a high-dimensional latent space, and the ideal recommendations for the source and target tasks (which are non-sensitive) are given by unknown linear transformations of the user information. So long as the tasks rely on similar segments of the user information, we can decompose the target recommendation problem into systematic components that can be derived from the source recommendations, and idiosyncratic components that are user-specific and cannot be derived from the source, but have significantly lower dimensionality. We propose an explore-then-refine approach to learning and utilizing this decomposition; then using ideas from perturbation theory and statistical concentration of measure, we prove our algorithm achieves regret comparable to a strong skyline that has full knowledge of the source and target transformations. We also consider a generalization of our algorithm to a model with many simultaneous targets and no source. Our methods obtain superior empirical results on synthetic benchmarks.
Generalization by Recognizing Confusion
Jun 13, 2020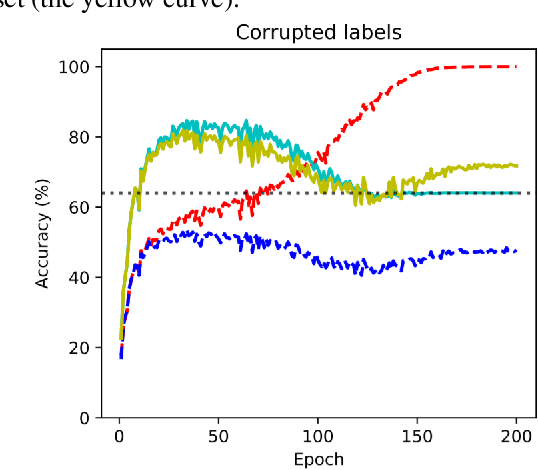
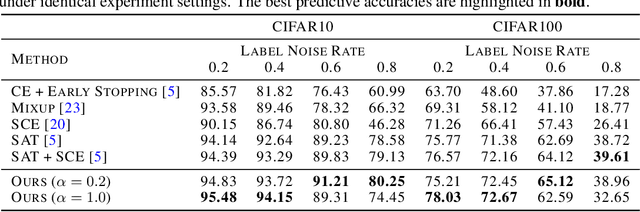
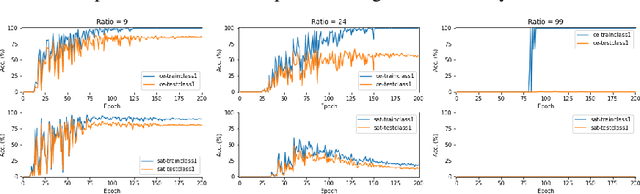

A recently-proposed technique called self-adaptive training augments modern neural networks by allowing them to adjust training labels on the fly, to avoid overfitting to samples that may be mislabeled or otherwise non-representative. By combining the self-adaptive objective with mixup, we further improve the accuracy of self-adaptive models for image recognition; the resulting classifier obtains state-of-the-art accuracies on datasets corrupted with label noise. Robustness to label noise implies a lower generalization gap; thus, our approach also leads to improved generalizability. We find evidence that the Rademacher complexity of these algorithms is low, suggesting a new path towards provable generalization for this type of deep learning model. Last, we highlight a novel connection between difficulties accounting for rare classes and robustness under noise, as rare classes are in a sense indistinguishable from label noise. Our code can be found at https://github.com/Tuxianeer/generalizationconfusion.
Smarter Parking: Using AI to Identify Parking Inefficiencies in Vancouver
Mar 21, 2020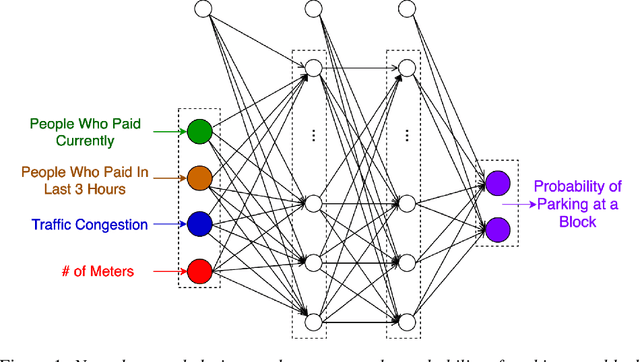
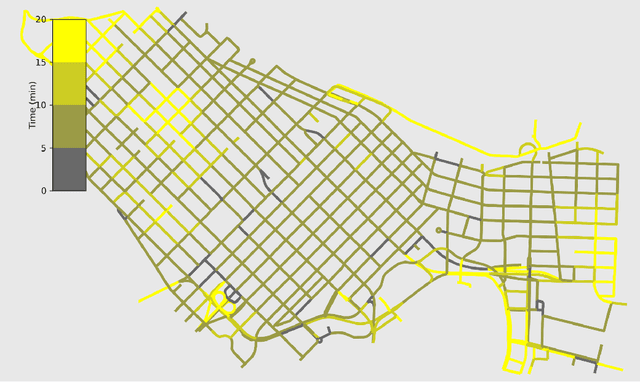
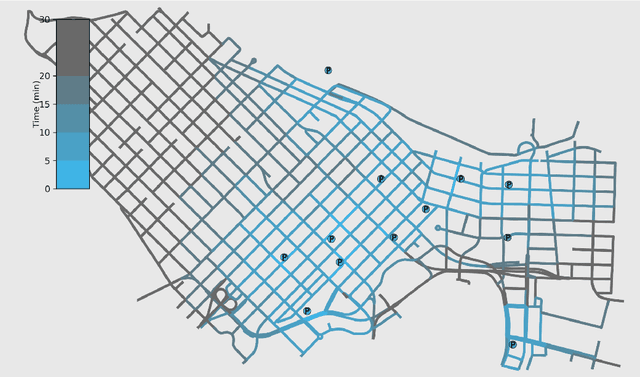
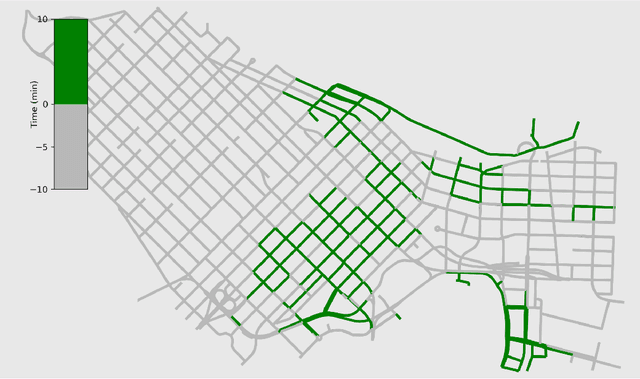
On-street parking is convenient, but has many disadvantages: on-street spots come at the expense of other road uses such as traffic lanes, transit lanes, bike lanes, or parklets; drivers looking for parking contribute substantially to traffic congestion and hence to greenhouse gas emissions; safety is reduced both due to the fact that drivers looking for spots are more distracted than other road users and that people exiting parked cars pose a risk to cyclists. These social costs may not be worth paying when off-street parking lots are nearby and have surplus capacity. To see where this might be true in downtown Vancouver, we used artificial intelligence techniques to estimate the amount of time it would take drivers to both park on and off street for destinations throughout the city. For on-street parking, we developed (1) a deep-learning model of block-by-block parking availability based on data from parking meters and audits and (2) a computational simulation of drivers searching for an on-street spot. For off-street parking, we developed a computational simulation of the time it would take drivers drive from their original destination to the nearest city-owned off-street lot and then to queue for a spot based on traffic and lot occupancy data. Finally, in both cases we also computed the time it would take the driver to walk from their parking spot to their original destination. We compared these time estimates for destinations in each block of Vancouver's downtown core and each hour of the day. We found many areas where off street would actually save drivers time over searching the streets for a spot, and many more where the time cost for parking off street was small. The identification of such areas provides an opportunity for the city to repurpose valuable curbside space for community-friendly uses more in line with its transportation goals.