 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentive-Compatible Recovery from Manipulated Signals, with Applications to Decentralized Physical Infrastructure
Mar 10, 2025We introduce the first formal model capturing the elicitation of unverifiable information from a party (the "source") with implicit signals derived by other players (the "observers"). Our model is motivated in part by applications in decentralized physical infrastructure networks (a.k.a. "DePIN"), an emerging application domain in which physical services (e.g., sensor information, bandwidth, or energy) are provided at least in part by untrusted and self-interested parties. A key challenge in these signal network applications is verifying the level of service that was actually provided by network participants. We first establish a condition called source identifiability, which we show is necessary for the existence of a mechanism for which truthful signal reporting is a strict equilibrium. For a converse, we build on techniques from peer prediction to show that in every signal network that satisfies the source identifiability condition, there is in fact a strictly truthful mechanism, where truthful signal reporting gives strictly higher total expected payoff than any less informative equilibrium. We furthermore show that this truthful equilibrium is in fact the unique equilibrium of the mechanism if there is positive probability that any one observer is unconditionally honest (e.g., if an observer were run by the network owner). Also, by extending our condition to coalitions, we show that there are generally no collusion-resistant mechanisms in the settings that we consider. We apply our framework and results to two DePIN applications: proving location, and proving bandwidth. In the location-proving setting observers learn (potentially enlarged) Euclidean distances to the source. Here, our condition has an appealing geometric interpretation, implying that the source's location can be truthfully elicited if and only if it is guaranteed to lie inside the convex hull of the observers.
Online Stackelberg Optimization via Nonlinear Control
Jun 27, 2024In repeated interaction problems with adaptive agents, our objective often requires anticipating and optimizing over the space of possible agent responses. We show that many problems of this form can be cast as instances of online (nonlinear) control which satisfy \textit{local controllability}, with convex losses over a bounded state space which encodes agent behavior, and we introduce a unified algorithmic framework for tractable regret minimization in such cases. When the instance dynamics are known but otherwise arbitrary, we obtain oracle-efficient $O(\sqrt{T})$ regret by reduction to online convex optimization, which can be made computationally efficient if dynamics are locally \textit{action-linear}. In the presence of adversarial disturbances to the state, we give tight bounds in terms of either the cumulative or per-round disturbance magnitude (for \textit{strongly} or \textit{weakly} locally controllable dynamics, respectively). Additionally, we give sublinear regret results for the cases of unknown locally action-linear dynamics as well as for the bandit feedback setting. Finally, we demonstrate applications of our framework to well-studied problems including performative prediction, recommendations for adaptive agents, adaptive pricing of real-valued goods, and repeated gameplay against no-regret learners, directly yielding extensions beyond prior results in each case.
Utilitarian Algorithm Configuration
Oct 31, 2023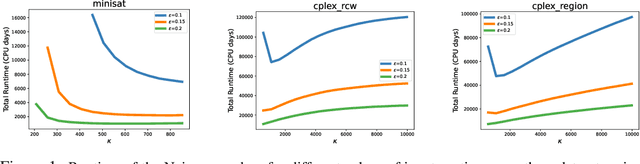

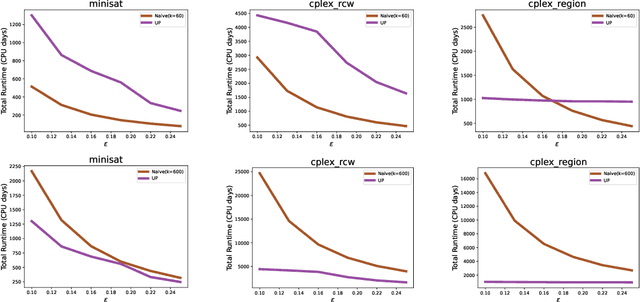
We present the first nontrivial procedure for configuring heuristic algorithms to maximize the utility provided to their end users while also offering theoretical guarantees about performance. Existing procedures seek configurations that minimize expected runtime. However, very recent theoretical work argues that expected runtime minimization fails to capture algorithm designers' preferences. Here we show that the utilitarian objective also confers significant algorithmic benefits. Intuitively, this is because mean runtime is dominated by extremely long runs even when they are incredibly rare; indeed, even when an algorithm never gives rise to such long runs, configuration procedures that provably minimize mean runtime must perform a huge number of experiments to demonstrate this fact. In contrast, utility is bounded and monotonically decreasing in runtime, allowing for meaningful empirical bounds on a configuration's performance. This paper builds on this idea to describe effective and theoretically sound configuration procedures. We prove upper bounds on the runtime of these procedures that are similar to theoretical lower bounds, while also demonstrating their performance empirically.
Formalizing Preferences Over Runtime Distributions
May 25, 2022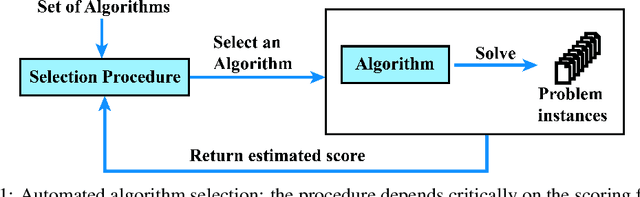
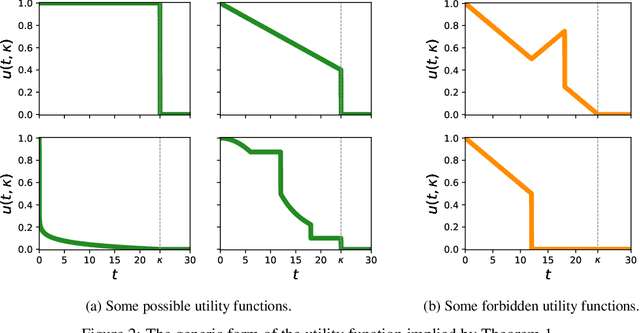
When trying to solve a computational problem we are often faced with a choice among algorithms that are all guaranteed to return the right answer but that differ in their runtime distributions (e.g., SAT solvers, sorting algorithms). This paper aims to lay theoretical foundations for such choices by formalizing preferences over runtime distributions. It might seem that we should simply prefer the algorithm that minimizes expected runtime. However, such preferences would be driven by exactly how slow our algorithm is on bad inputs, whereas in practice we are typically willing to cut off occasional, sufficiently long runs before they finish. We propose a principled alternative, taking a utility-theoretic approach to characterize the scoring functions that describe preferences over algorithms. These functions depend on the way our value for solving our problem decreases with time and on the distribution from which captimes are drawn. We describe examples of realistic utility functions and show how to leverage a maximum-entropy approach for modeling underspecified captime distributions. Finally, we show how to efficiently estimate an algorithm's expected utility from runtime samples.
No-Regret Learning with Unbounded Losses: The Case of Logarithmic Pooling
Feb 22, 2022For each of $T$ time steps, $m$ experts report probability distributions over $n$ outcomes; we wish to learn to aggregate these forecasts in a way that attains a no-regret guarantee. We focus on the fundamental and practical aggregation method known as logarithmic pooling -- a weighted average of log odds -- which is in a certain sense the optimal choice of pooling method if one is interested in minimizing log loss (as we take to be our loss function). We consider the problem of learning the best set of parameters (i.e. expert weights) in an online adversarial setting. We assume (by necessity) that the adversarial choices of outcomes and forecasts are consistent, in the sense that experts report calibrated forecasts. Our main result is an algorithm based on online mirror descent that learns expert weights in a way that attains $O(\sqrt{T} \log T)$ expected regret as compared with the best weights in hindsight.
Are You Smarter Than a Random Expert? The Robust Aggregation of Substitutable Signals
Nov 04, 2021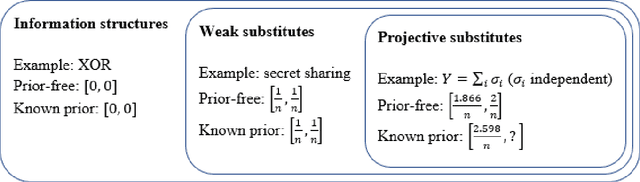
The problem of aggregating expert forecasts is ubiquitous in fields as wide-ranging as machine learning, economics, climate science, and national security. Despite this, our theoretical understanding of this question is fairly shallow. This paper initiates the study of forecast aggregation in a context where experts' knowledge is chosen adversarially from a broad class of information structures. While in full generality it is impossible to achieve a nontrivial performance guarantee, we show that doing so is possible under a condition on the experts' information structure that we call \emph{projective substitutes}. The projective substitutes condition is a notion of informational substitutes: that there are diminishing marginal returns to learning the experts' signals. We show that under the projective substitutes condition, taking the average of the experts' forecasts improves substantially upon the strategy of trusting a random expert. We then consider a more permissive setting, in which the aggregator has access to the prior. We show that by averaging the experts' forecasts and then \emph{extremizing} the average by moving it away from the prior by a constant factor, the aggregator's performance guarantee is substantially better than is possible without knowledge of the prior. Our results give a theoretical grounding to past empirical research on extremization and help give guidance on the appropriate amount to extremize.
Smoothed Analysis with Adaptive Adversaries
Feb 16, 2021
We prove novel algorithmic guarantees for several online problems in the smoothed analysis model. In this model, at each time an adversary chooses an input distribution with density function bounded above by $\tfrac{1}{\sigma}$ times that of the uniform distribution; nature then samples an input from this distribution. Crucially, our results hold for {\em adaptive} adversaries that can choose an input distribution based on the decisions of the algorithm and the realizations of the inputs in the previous time steps. This paper presents a general technique for proving smoothed algorithmic guarantees against adaptive adversaries, in effect reducing the setting of adaptive adversaries to the simpler case of oblivious adversaries. We apply this technique to prove strong smoothed guarantees for three problems: -Online learning: We consider the online prediction problem, where instances are generated from an adaptive sequence of $\sigma$-smooth distributions and the hypothesis class has VC dimension $d$. We bound the regret by $\tilde{O}\big(\sqrt{T d\ln(1/\sigma)} + d\sqrt{\ln(T/\sigma)}\big)$. This answers open questions of [RST11,Hag18]. -Online discrepancy minimization: We consider the online Koml\'os problem, where the input is generated from an adaptive sequence of $\sigma$-smooth and isotropic distributions on the $\ell_2$ unit ball. We bound the $\ell_\infty$ norm of the discrepancy vector by $\tilde{O}\big(\ln^2\!\big( \frac{nT}{\sigma}\big) \big)$. -Dispersion in online optimization: We consider online optimization of piecewise Lipschitz functions where functions with $\ell$ discontinuities are chosen by a smoothed adaptive adversary and show that the resulting sequence is $\big( {\sigma}/{\sqrt{T\ell}}, \tilde O\big(\sqrt{T\ell} \big)\big)$-dispersed. This matches the parameters of [BDV18] for oblivious adversaries, up to log factors.
Beyond the Worst-Case Analysis of Algorithms
Jul 26, 2020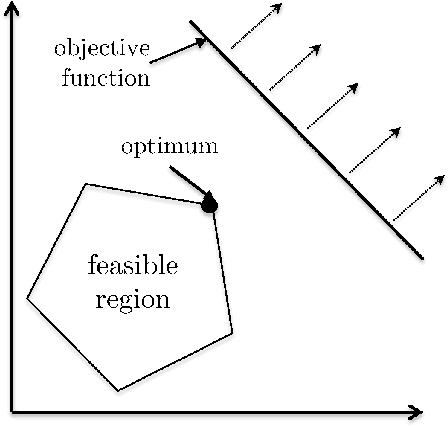


One of the primary goals of the mathematical analysis of algorithms is to provide guidance about which algorithm is the "best" for solving a given computational problem. Worst-case analysis summarizes the performance profile of an algorithm by its worst performance on any input of a given size, implicitly advocating for the algorithm with the best-possible worst-case performance. Strong worst-case guarantees are the holy grail of algorithm design, providing an application-agnostic certification of an algorithm's robustly good performance. However, for many fundamental problems and performance measures, such guarantees are impossible and a more nuanced analysis approach is called for. This chapter surveys several alternatives to worst-case analysis that are discussed in detail later in the book.
Smoothed Analysis of Online and Differentially Private Learning
Jun 17, 2020Practical and pervasive needs for robustness and privacy in algorithms have inspired the design of online adversarial and differentially private learning algorithms. The primary quantity that characterizes learnability in these settings is the Littlestone dimension of the class of hypotheses [Ben-David et al., 2009, Alon et al., 2019]. This characterization is often interpreted as an impossibility result because classes such as linear thresholds and neural networks have infinite Littlestone dimension. In this paper, we apply the framework of smoothed analysis [Spielman and Teng, 2004], in which adversarially chosen inputs are perturbed slightly by nature. We show that fundamentally stronger regret and error guarantees are possible with smoothed adversaries than with worst-case adversaries. In particular, we obtain regret and privacy error bounds that depend only on the VC dimension and the bracketing number of a hypothesis class, and on the magnitudes of the perturbations.
On the Computational Power of Online Gradient Descent
Jul 03, 2018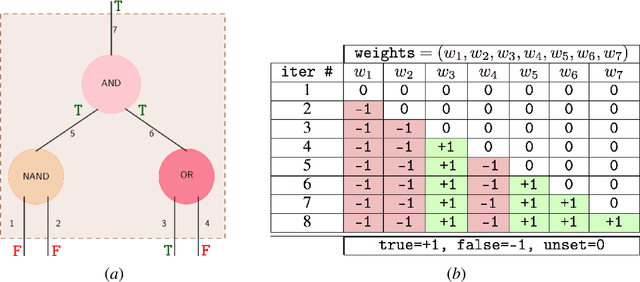
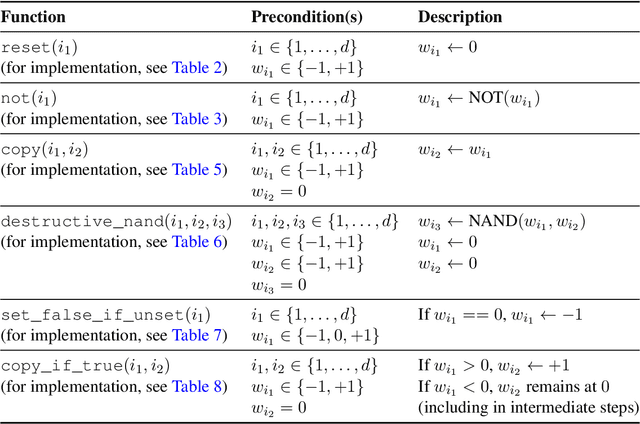
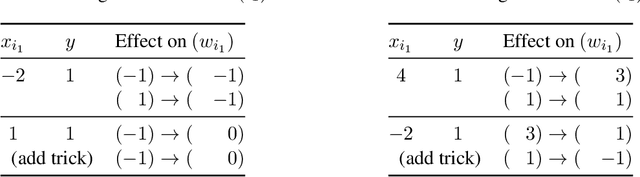

We prove that the evolution of weight vectors in online gradient descent can encode arbitrary polynomial-space computations, even in the special case of soft-margin support vector machines. Our results imply that, under weak complexity-theoretic assumptions, it is impossible to reason efficiently about the fine-grained behavior of online gradient descent.