 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilitarian Algorithm Configuration for Infinite Parameter Spaces
May 28, 2024

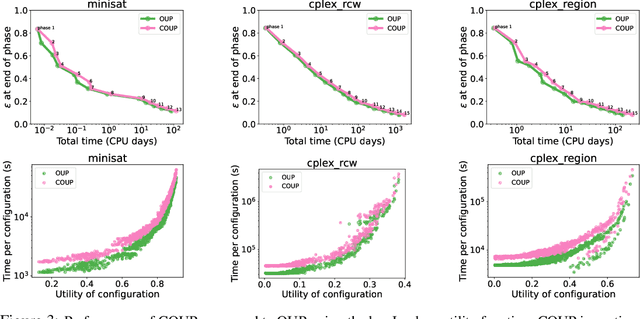

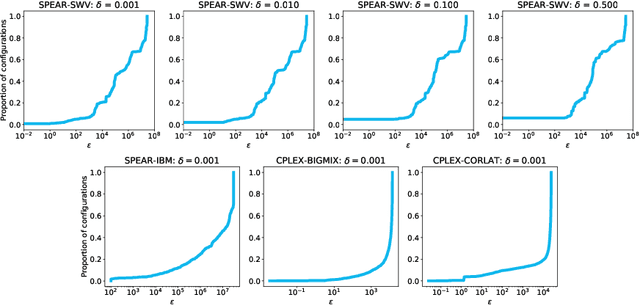
Utilitarian algorithm configuration is a general-purpose technique for automatically searching the parameter space of a given algorithm to optimize its performance, as measured by a given utility function, on a given set of inputs. Recently introduced utilitarian configuration procedures offer optimality guarantees about the returned parameterization while provably adapting to the hardness of the underlying problem. However, the applicability of these approaches is severely limited by the fact that they only search a finite, relatively small set of parameters. They cannot effectively search the configuration space of algorithms with continuous or uncountable parameters. In this paper we introduce a new procedure, which we dub COUP (Continuous, Optimistic Utilitarian Procrastination). COUP is designed to search infinite parameter spaces efficiently to find good configurations quickly. Furthermore, COUP maintains the theoretical benefits of previous utilitarian configuration procedures when applied to finite parameter spaces but is significantly faster, both provably and experimentally.
Smarter Parking: Using AI to Identify Parking Inefficiencies in Vancouver
Mar 21, 2020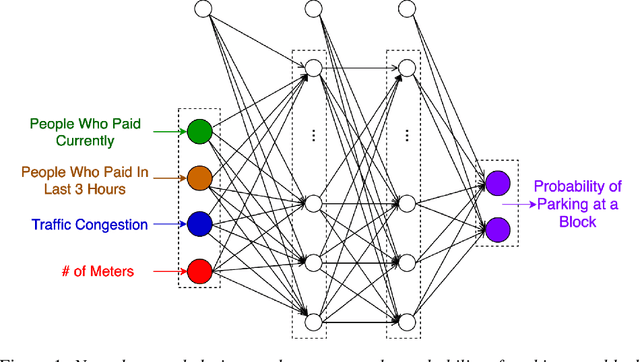
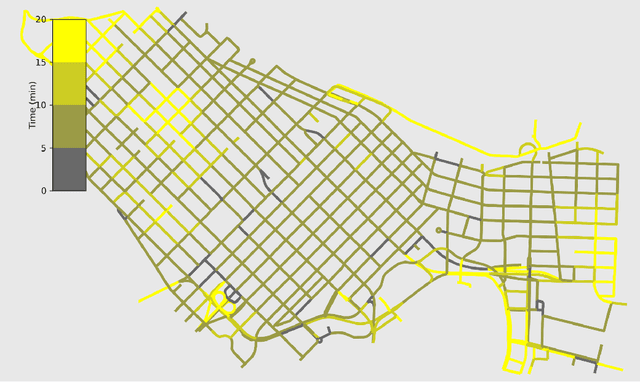
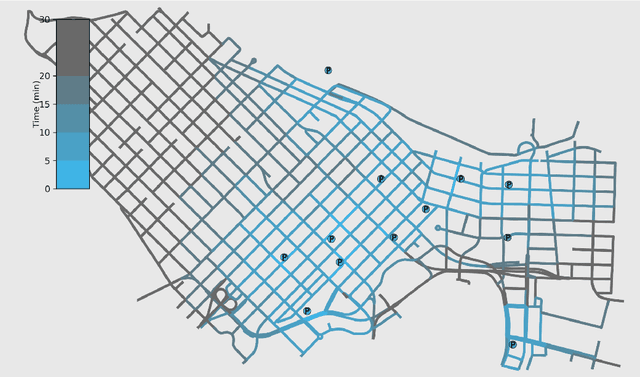
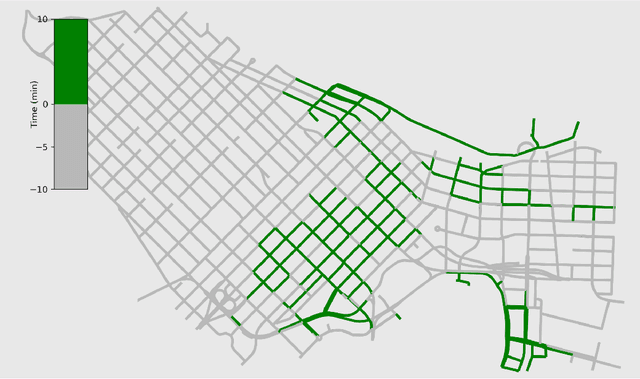
On-street parking is convenient, but has many disadvantages: on-street spots come at the expense of other road uses such as traffic lanes, transit lanes, bike lanes, or parklets; drivers looking for parking contribute substantially to traffic congestion and hence to greenhouse gas emissions; safety is reduced both due to the fact that drivers looking for spots are more distracted than other road users and that people exiting parked cars pose a risk to cyclists. These social costs may not be worth paying when off-street parking lots are nearby and have surplus capacity. To see where this might be true in downtown Vancouver, we used artificial intelligence techniques to estimate the amount of time it would take drivers to both park on and off street for destinations throughout the city. For on-street parking, we developed (1) a deep-learning model of block-by-block parking availability based on data from parking meters and audits and (2) a computational simulation of drivers searching for an on-street spot. For off-street parking, we developed a computational simulation of the time it would take drivers drive from their original destination to the nearest city-owned off-street lot and then to queue for a spot based on traffic and lot occupancy data. Finally, in both cases we also computed the time it would take the driver to walk from their parking spot to their original destination. We compared these time estimates for destinations in each block of Vancouver's downtown core and each hour of the day. We found many areas where off street would actually save drivers time over searching the streets for a spot, and many more where the time cost for parking off street was small. The identification of such areas provides an opportunity for the city to repurpose valuable curbside space for community-friendly uses more in line with its transportation goals.
Deep Models for Relational Databases
Mar 21, 2019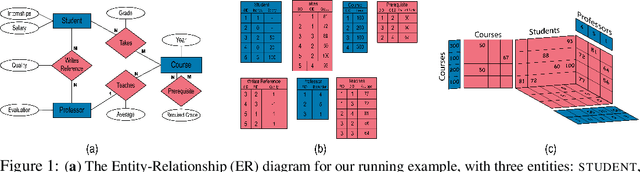

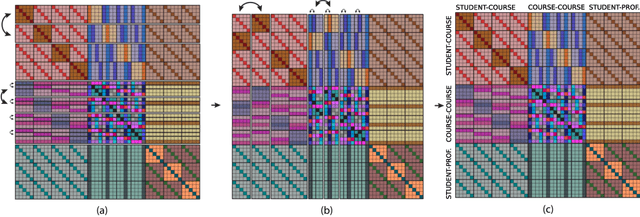
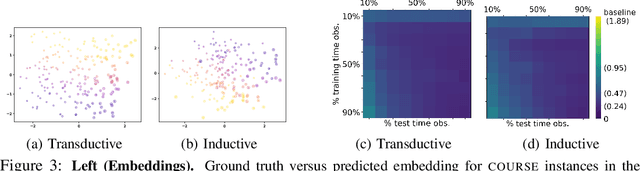
Due to its extensive use in databases, the relational model is ubiquitous in representing big-data. We propose to apply deep learning to this type of relational data by introducing an Equivariant Relational Layer (ERL), a neural network layer derived from the entity-relationship model of the database. Our layer relies on identification of exchangeabilities in the relational data(base), and their expression as a permutation group. We prove that an ERL is an optimal parameter-sharing scheme under the given exchangeability constraints, and subsumes recently introduced deep models for sets, exchangeable tensors, and graphs. The proposed model has a linear complexity in the size of the relational data, and it can be used for both inductive and transductive reasoning in databases, including the prediction of missing records, and database embedding. This opens the door to the application of deep learning to one of the most abundant forms of data.
Procrastinating with Confidence: Near-Optimal, Anytime, Adaptive Algorithm Configuration
Feb 14, 2019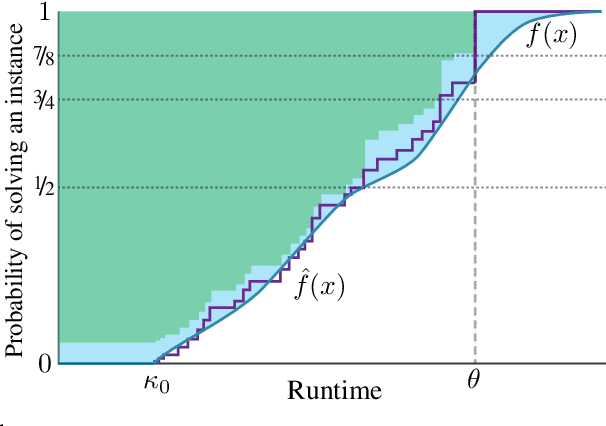
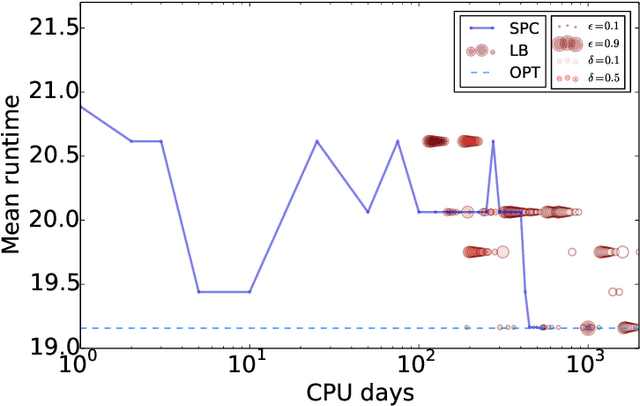
Algorithm configuration methods optimize the performance of a parameterized heuristic algorithm on a given distribution of problem instances. Recent work introduced an algorithm configuration procedure ('Structured Procrastination') that provably achieves near optimal performance with high probability and with nearly minimal runtime in the worst case. It also offers an $\textit{anytime}$ property: it keeps tightening its optimality guarantees the longer it is run. Unfortunately, Structured Procrastination is not $\textit{adaptive}$ to characteristics of the parameterized algorithm: it treats every input like the worst case. Follow-up work ('Leaps and Bounds') achieves adaptivity but trades away the anytime property. This paper introduces a new algorithm configuration method, 'Structured Procrastination with Confidence', that preserves the near-optimality and anytime properties of Structured Procrastination while adding adaptivity. In particular, the new algorithm will perform dramatically faster in settings where many algorithm configurations perform poorly; we show empirically that such settings arise frequently in practice.