 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Peer Grading through Bayesian Inference
Sep 02, 2022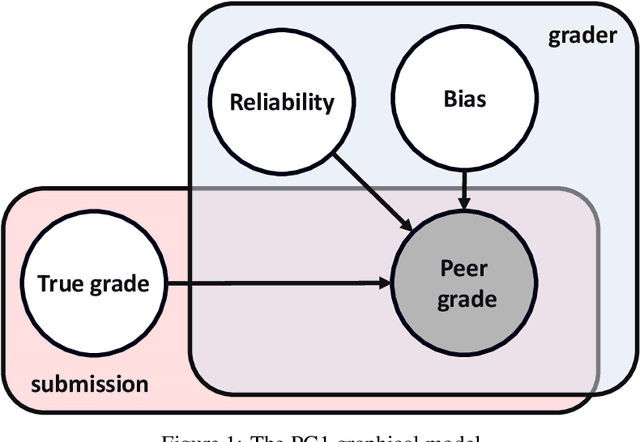
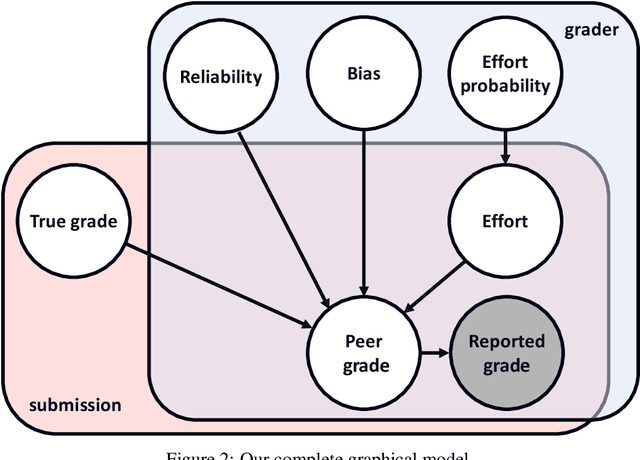
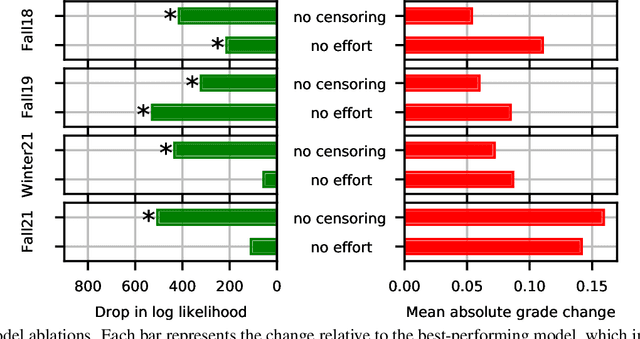
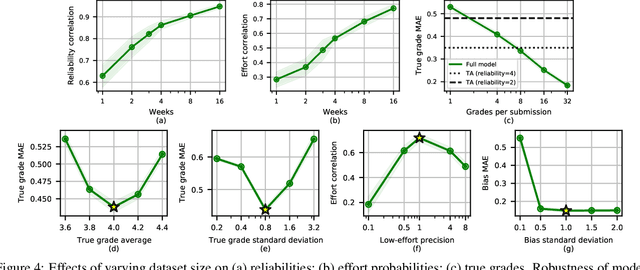
Peer grading systems aggregate noisy reports from multiple students to approximate a true grade as closely as possible. Most current systems either take the mean or median of reported grades; others aim to estimate students' grading accuracy under a probabilistic model. This paper extends the state of the art in the latter approach in three key ways: (1) recognizing that students can behave strategically (e.g., reporting grades close to the class average without doing the work); (2) appropriately handling censored data that arises from discrete-valued grading rubrics; and (3) using mixed integer programming to improve the interpretability of the grades assigned to students. We show how to make Bayesian inference practical in this model and evaluate our approach on both synthetic and real-world data obtained by using our implemented system in four large classes. These extensive experiments show that grade aggregation using our model accurately estimates true grades, students' likelihood of submitting uninformative grades, and the variation in their inherent grading error; we also characterize our models' robustness.
Matching Papers and Reviewers at Large Conferences
Mar 02, 2022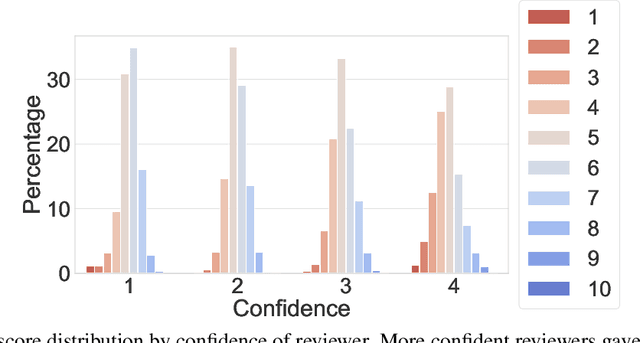

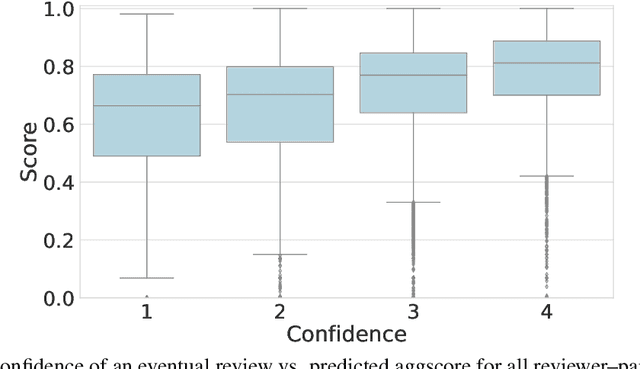

This paper studies a novel reviewer-paper matching approach that was recently deployed in the 35th AAAI Conference on Artificial Intelligence (AAAI 2021), and has since been adopted by other conferences including AAAI 2022 and ICML 2022. This approach has three main elements: (1) collecting and processing input data to identify problematic matches and generate reviewer-paper scores; (2) formulating and solving an optimization problem to find good reviewer-paper matchings; and (3) the introduction of a novel, two-phase reviewing process that shifted reviewing resources away from papers likely to be rejected and towards papers closer to the decision boundary. This paper also describes an evaluation of these innovations based on an extensive post-hoc analysis on real data -- including a comparison with the matching algorithm used in AAAI's previous (2020) iteration -- and supplements this with additional numerical experimentation.
Smarter Parking: Using AI to Identify Parking Inefficiencies in Vancouver
Mar 21, 2020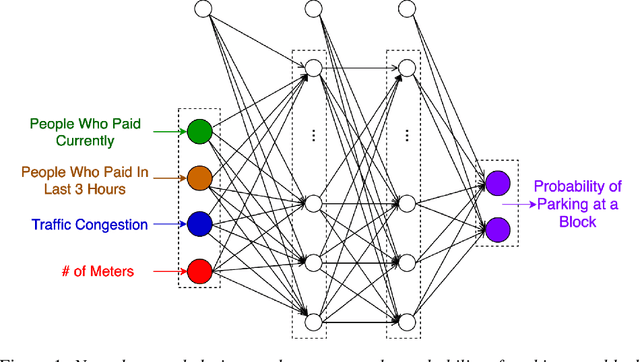
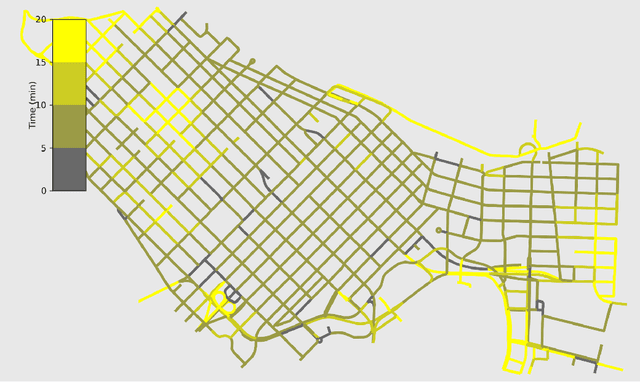
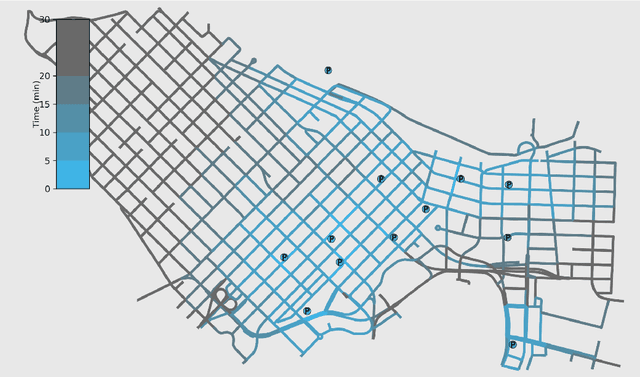
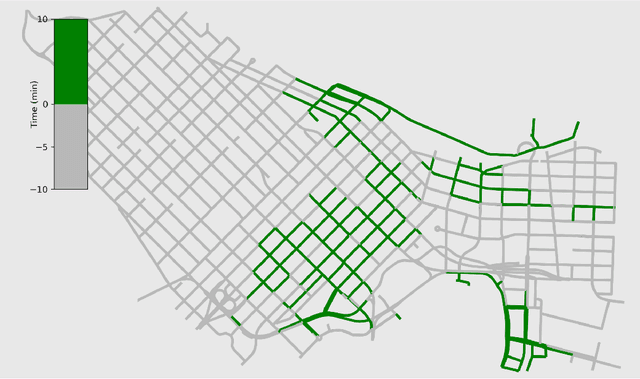
On-street parking is convenient, but has many disadvantages: on-street spots come at the expense of other road uses such as traffic lanes, transit lanes, bike lanes, or parklets; drivers looking for parking contribute substantially to traffic congestion and hence to greenhouse gas emissions; safety is reduced both due to the fact that drivers looking for spots are more distracted than other road users and that people exiting parked cars pose a risk to cyclists. These social costs may not be worth paying when off-street parking lots are nearby and have surplus capacity. To see where this might be true in downtown Vancouver, we used artificial intelligence techniques to estimate the amount of time it would take drivers to both park on and off street for destinations throughout the city. For on-street parking, we developed (1) a deep-learning model of block-by-block parking availability based on data from parking meters and audits and (2) a computational simulation of drivers searching for an on-street spot. For off-street parking, we developed a computational simulation of the time it would take drivers drive from their original destination to the nearest city-owned off-street lot and then to queue for a spot based on traffic and lot occupancy data. Finally, in both cases we also computed the time it would take the driver to walk from their parking spot to their original destination. We compared these time estimates for destinations in each block of Vancouver's downtown core and each hour of the day. We found many areas where off street would actually save drivers time over searching the streets for a spot, and many more where the time cost for parking off street was small. The identification of such areas provides an opportunity for the city to repurpose valuable curbside space for community-friendly uses more in line with its transportation goals.