 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinisic Gradient Compression for Federated Learning
Dec 05, 2021
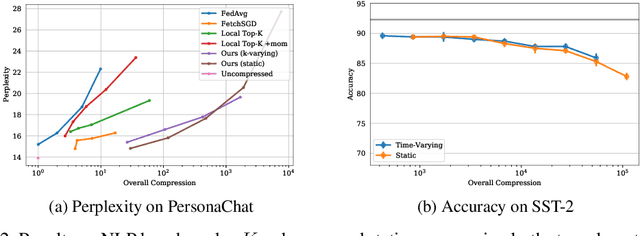

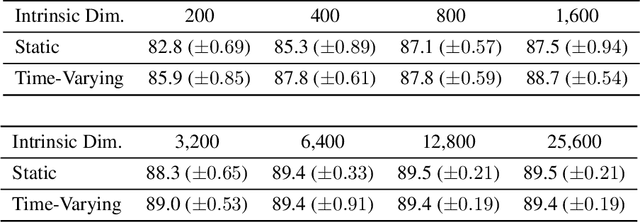
Federated learning is a rapidly-growing area of research which enables a large number of clients to jointly train a machine learning model on privately-held data. One of the largest barriers to wider adoption of federated learning is the communication cost of sending model updates from and to the clients, which is accentuated by the fact that many of these devices are bandwidth-constrained. In this paper, we aim to address this issue by optimizing networks within a subspace of their full parameter space, an idea known as intrinsic dimension in the machine learning theory community. We use a correspondence between the notion of intrinsic dimension and gradient compressibility to derive a family of low-bandwidth optimization algorithms, which we call intrinsic gradient compression algorithms. Specifically, we present three algorithms in this family with different levels of upload and download bandwidth for use in various federated settings, along with theoretical guarantees on their performance. Finally, in large-scale federated learning experiments with models containing up to 100M parameters, we show that our algorithms perform extremely well compared to current state-of-the-art gradient compression methods.
Recommending with Recommendations
Dec 02, 2021Recommendation systems are a key modern application of machine learning, but they have the downside that they often draw upon sensitive user information in making their predictions. We show how to address this deficiency by basing a service's recommendation engine upon recommendations from other existing services, which contain no sensitive information by nature. Specifically, we introduce a contextual multi-armed bandit recommendation framework where the agent has access to recommendations for other services. In our setting, the user's (potentially sensitive) information belongs to a high-dimensional latent space, and the ideal recommendations for the source and target tasks (which are non-sensitive) are given by unknown linear transformations of the user information. So long as the tasks rely on similar segments of the user information, we can decompose the target recommendation problem into systematic components that can be derived from the source recommendations, and idiosyncratic components that are user-specific and cannot be derived from the source, but have significantly lower dimensionality. We propose an explore-then-refine approach to learning and utilizing this decomposition; then using ideas from perturbation theory and statistical concentration of measure, we prove our algorithm achieves regret comparable to a strong skyline that has full knowledge of the source and target transformations. We also consider a generalization of our algorithm to a model with many simultaneous targets and no source. Our methods obtain superior empirical results on synthetic benchmarks.
Learned Benchmarks for Subseasonal Forecasting
Sep 21, 2021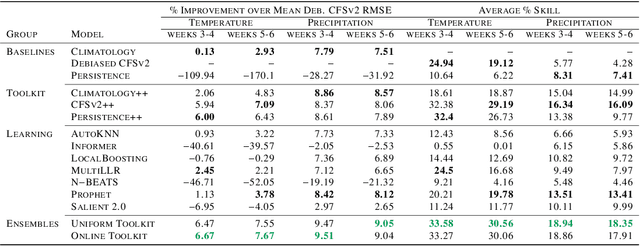
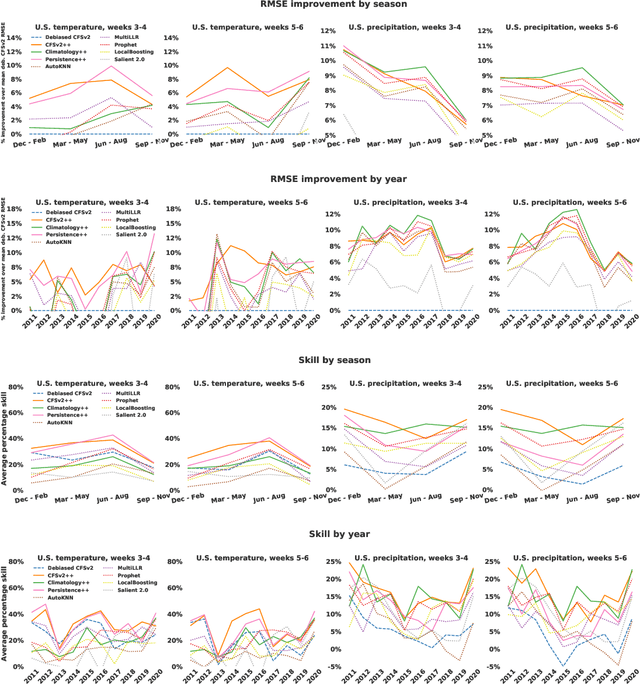
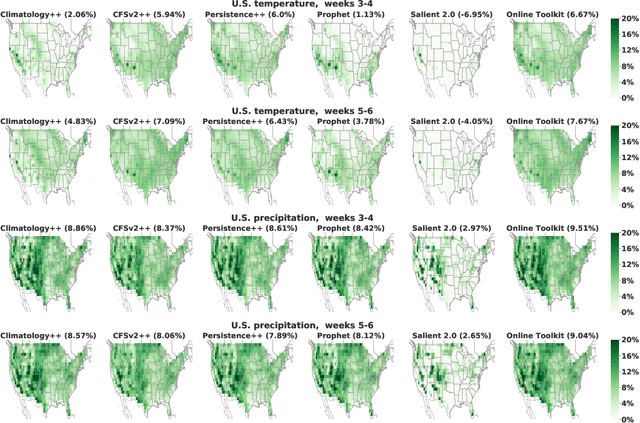
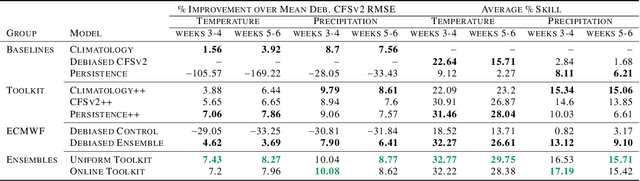
We develop a subseasonal forecasting toolkit of simple learned benchmark models that outperform both operational practice and state-of-the-art machine learning and deep learning methods. Our new models include (a) Climatology++, an adaptive alternative to climatology that, for precipitation, is 9% more accurate and 250% more skillful than the United States operational Climate Forecasting System (CFSv2); (b) CFSv2++, a learned CFSv2 correction that improves temperature and precipitation accuracy by 7-8% and skill by 50-275%; and (c) Persistence++, an augmented persistence model that combines CFSv2 forecasts with lagged measurements to improve temperature and precipitation accuracy by 6-9% and skill by 40-130%. Across the contiguous U.S., our Climatology++, CFSv2++, and Persistence++ toolkit consistently outperforms standard meteorological baselines, state-of-the-art machine and deep learning methods, and the European Centre for Medium-Range Weather Forecasts ensemble. Overall, we find that augmenting traditional forecasting approaches with learned enhancements yields an effective and computationally inexpensive strategy for building the next generation of subseasonal forecasting benchmarks.
Generalization by Recognizing Confusion
Jun 13, 2020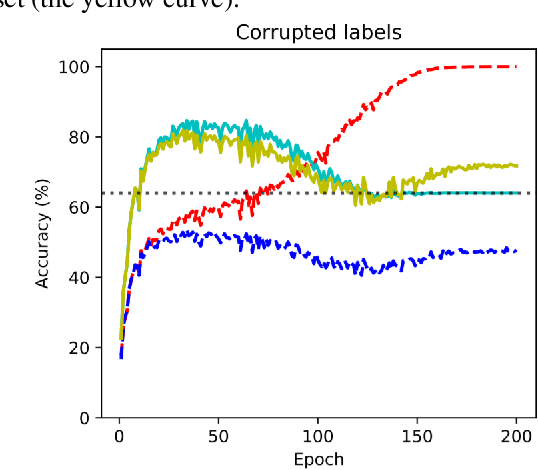
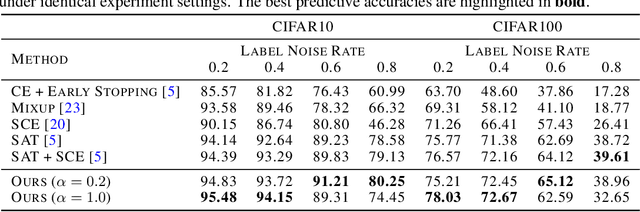
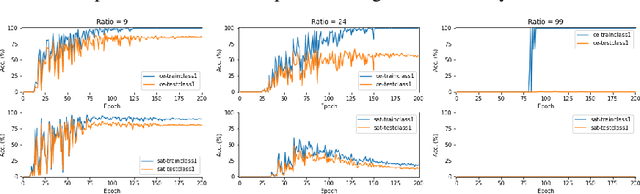

A recently-proposed technique called self-adaptive training augments modern neural networks by allowing them to adjust training labels on the fly, to avoid overfitting to samples that may be mislabeled or otherwise non-representative. By combining the self-adaptive objective with mixup, we further improve the accuracy of self-adaptive models for image recognition; the resulting classifier obtains state-of-the-art accuracies on datasets corrupted with label noise. Robustness to label noise implies a lower generalization gap; thus, our approach also leads to improved generalizability. We find evidence that the Rademacher complexity of these algorithms is low, suggesting a new path towards provable generalization for this type of deep learning model. Last, we highlight a novel connection between difficulties accounting for rare classes and robustness under noise, as rare classes are in a sense indistinguishable from label noise. Our code can be found at https://github.com/Tuxianeer/generalizationconfusion.