 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinisic Gradient Compression for Federated Learning
Paper and Code
Dec 05, 2021
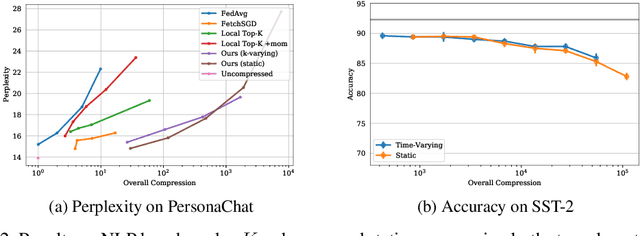

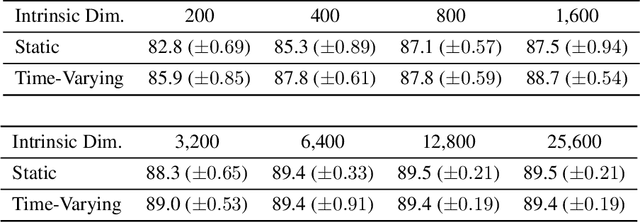
Federated learning is a rapidly-growing area of research which enables a large number of clients to jointly train a machine learning model on privately-held data. One of the largest barriers to wider adoption of federated learning is the communication cost of sending model updates from and to the clients, which is accentuated by the fact that many of these devices are bandwidth-constrained. In this paper, we aim to address this issue by optimizing networks within a subspace of their full parameter space, an idea known as intrinsic dimension in the machine learning theory community. We use a correspondence between the notion of intrinsic dimension and gradient compressibility to derive a family of low-bandwidth optimization algorithms, which we call intrinsic gradient compression algorithms. Specifically, we present three algorithms in this family with different levels of upload and download bandwidth for use in various federated settings, along with theoretical guarantees on their performance. Finally, in large-scale federated learning experiments with models containing up to 100M parameters, we show that our algorithms perform extremely well compared to current state-of-the-art gradient compression methods.