 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecipitation nowcasting of satellite data using physically conditioned neural networks
Nov 07, 2025Accurate short-term precipitation forecasts predominantly rely on dense weather-radar networks, limiting operational value in places most exposed to climate extremes. We present TUPANN (Transferable and Universal Physics-Aligned Nowcasting Network), a satellite-only model trained on GOES-16 RRQPE. Unlike most deep learning models for nowcasting, TUPANN decomposes the forecast into physically meaningful components: a variational encoder-decoder infers motion and intensity fields from recent imagery under optical-flow supervision, a lead-time-conditioned MaxViT evolves the latent state, and a differentiable advection operator reconstructs future frames. We evaluate TUPANN on both GOES-16 and IMERG data, in up to four distinct climates (Rio de Janeiro, Manaus, Miami, La Paz) at 10-180min lead times using the CSI and HSS metrics over 4-64 mm/h thresholds. Comparisons against optical-flow, deep learning and hybrid baselines show that TUPANN achieves the best or second-best skill in most settings, with pronounced gains at higher thresholds. Training on multiple cities further improves performance, while cross-city experiments show modest degradation and occasional gains for rare heavy-rain regimes. The model produces smooth, interpretable motion fields aligned with numerical optical flow and runs in near real time due to the low latency of GOES-16. These results indicate that physically aligned learning can provide nowcasts that are skillful, transferable and global.
Deep Hashing via Householder Quantization
Nov 07, 2023Hashing is at the heart of large-scale image similarity search, and recent methods have been substantially improved through deep learning techniques. Such algorithms typically learn continuous embeddings of the data. To avoid a subsequent costly binarization step, a common solution is to employ loss functions that combine a similarity learning term (to ensure similar images are grouped to nearby embeddings) and a quantization penalty term (to ensure that the embedding entries are close to binarized entries, e.g., -1 or 1). Still, the interaction between these two terms can make learning harder and the embeddings worse. We propose an alternative quantization strategy that decomposes the learning problem in two stages: first, perform similarity learning over the embedding space with no quantization; second, find an optimal orthogonal transformation of the embeddings so each coordinate of the embedding is close to its sign, and then quantize the transformed embedding through the sign function. In the second step, we parametrize orthogonal transformations using Householder matrices to efficiently leverage stochastic gradient descent. Since similarity measures are usually invariant under orthogonal transformations, this quantization strategy comes at no cost in terms of performance. The resulting algorithm is unsupervised, fast, hyperparameter-free and can be run on top of any existing deep hashing or metric learning algorithm. We provide extensive experimental results showing that this approach leads to state-of-the-art performance on widely used image datasets, and, unlike other quantization strategies, brings consistent improvements in performance to existing deep hashing algorithms.
Adaptive Bias Correction for Improved Subseasonal Forecasting
Sep 21, 2022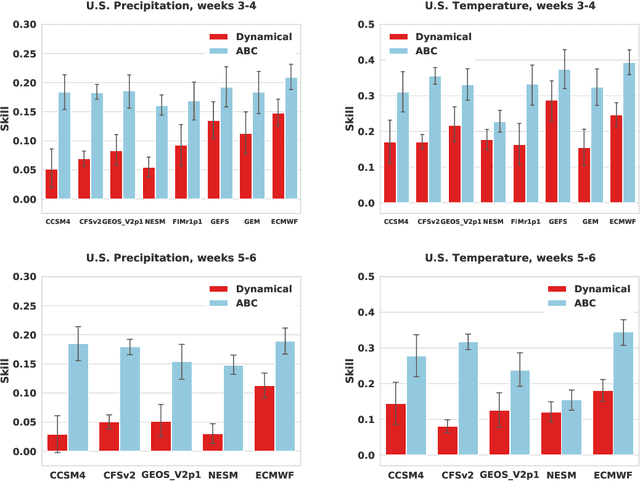
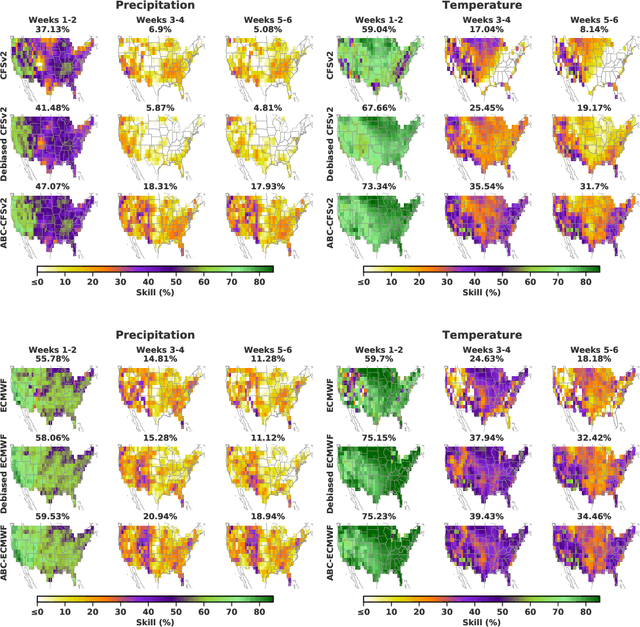
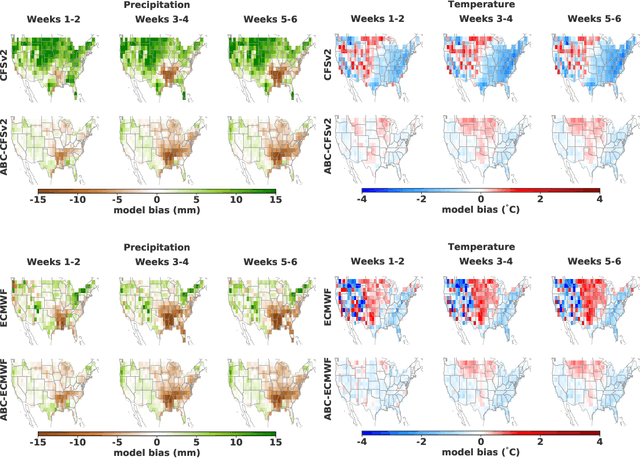
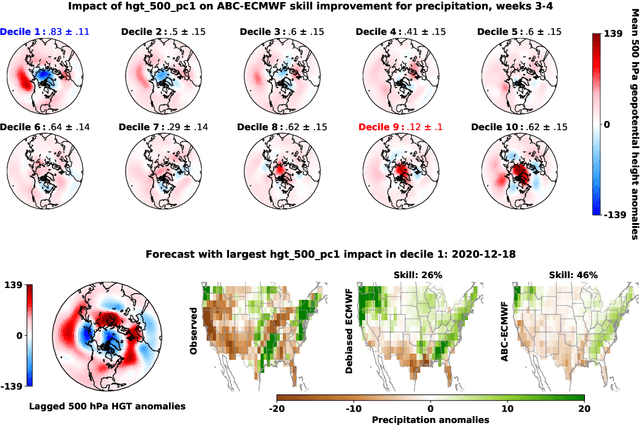
Subseasonal forecasting $\unicode{x2013}$ predicting temperature and precipitation 2 to 6 weeks $\unicode{x2013}$ ahead is critical for effective water allocation, wildfire management, and drought and flood mitigation. Recent international research efforts have advanced the subseasonal capabilities of operational dynamical models, yet temperature and precipitation prediction skills remains poor, partly due to stubborn errors in representing atmospheric dynamics and physics inside dynamical models. To counter these errors, we introduce an adaptive bias correction (ABC) method that combines state-of-the-art dynamical forecasts with observations using machine learning. When applied to the leading subseasonal model from the European Centre for Medium-Range Weather Forecasts (ECMWF), ABC improves temperature forecasting skill by 60-90% and precipitation forecasting skill by 40-69% in the contiguous U.S. We couple these performance improvements with a practical workflow, based on Cohort Shapley, for explaining ABC skill gains and identifying higher-skill windows of opportunity based on specific climate conditions.
Learned Benchmarks for Subseasonal Forecasting
Sep 21, 2021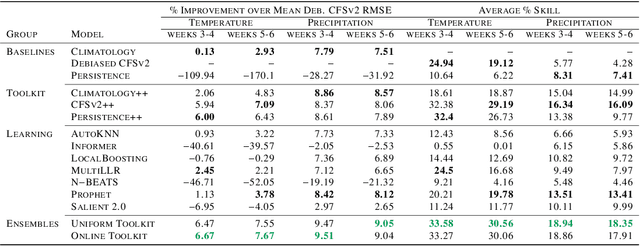
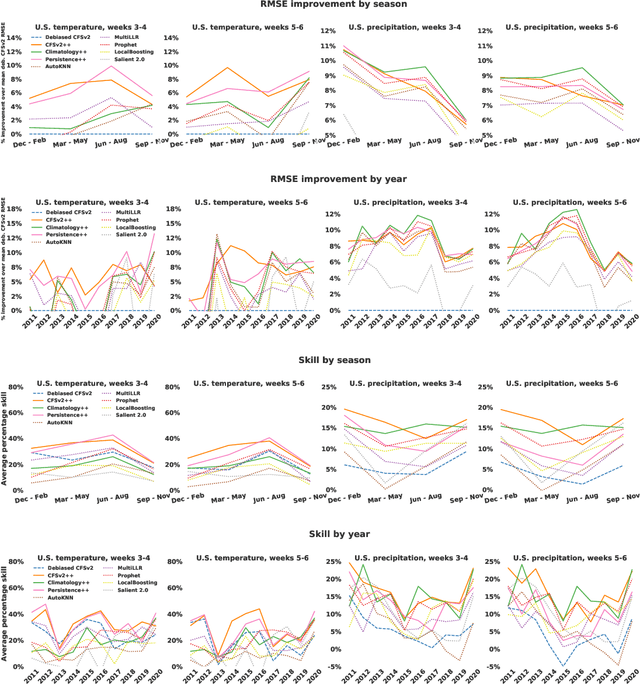
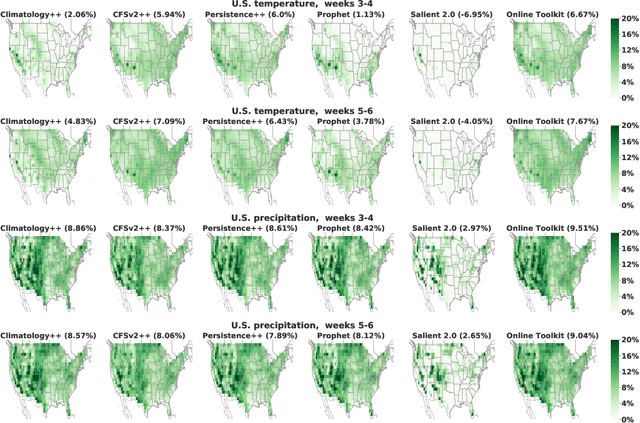
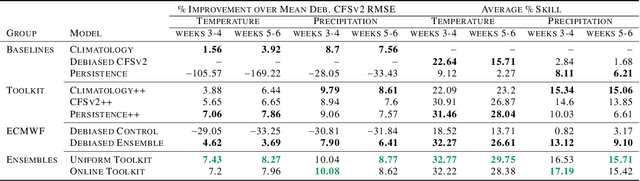
We develop a subseasonal forecasting toolkit of simple learned benchmark models that outperform both operational practice and state-of-the-art machine learning and deep learning methods. Our new models include (a) Climatology++, an adaptive alternative to climatology that, for precipitation, is 9% more accurate and 250% more skillful than the United States operational Climate Forecasting System (CFSv2); (b) CFSv2++, a learned CFSv2 correction that improves temperature and precipitation accuracy by 7-8% and skill by 50-275%; and (c) Persistence++, an augmented persistence model that combines CFSv2 forecasts with lagged measurements to improve temperature and precipitation accuracy by 6-9% and skill by 40-130%. Across the contiguous U.S., our Climatology++, CFSv2++, and Persistence++ toolkit consistently outperforms standard meteorological baselines, state-of-the-art machine and deep learning methods, and the European Centre for Medium-Range Weather Forecasts ensemble. Overall, we find that augmenting traditional forecasting approaches with learned enhancements yields an effective and computationally inexpensive strategy for building the next generation of subseasonal forecasting benchmarks.
Online Learning with Optimism and Delay
Jul 12, 2021
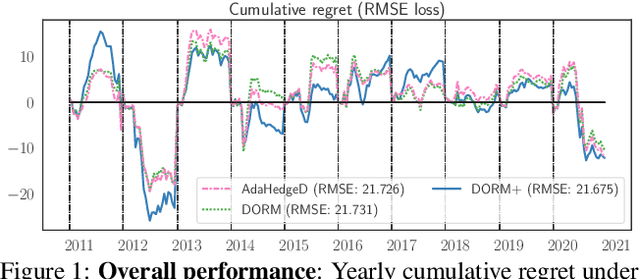
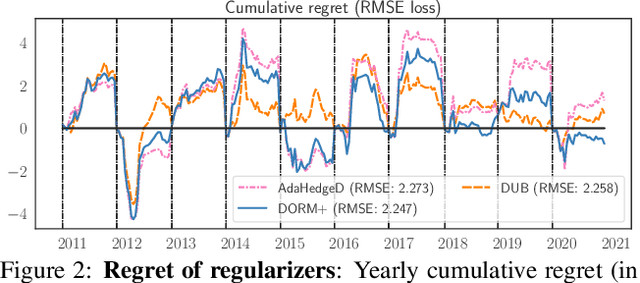

Inspired by the demands of real-time climate and weather forecasting, we develop optimistic online learning algorithms that require no parameter tuning and have optimal regret guarantees under delayed feedback. Our algorithms -- DORM, DORM+, and AdaHedgeD -- arise from a novel reduction of delayed online learning to optimistic online learning that reveals how optimistic hints can mitigate the regret penalty caused by delay. We pair this delay-as-optimism perspective with a new analysis of optimistic learning that exposes its robustness to hinting errors and a new meta-algorithm for learning effective hinting strategies in the presence of delay. We conclude by benchmarking our algorithms on four subseasonal climate forecasting tasks, demonstrating low regret relative to state-of-the-art forecasting models.
Improving Subseasonal Forecasting in the Western U.S. with Machine Learning
Sep 19, 2018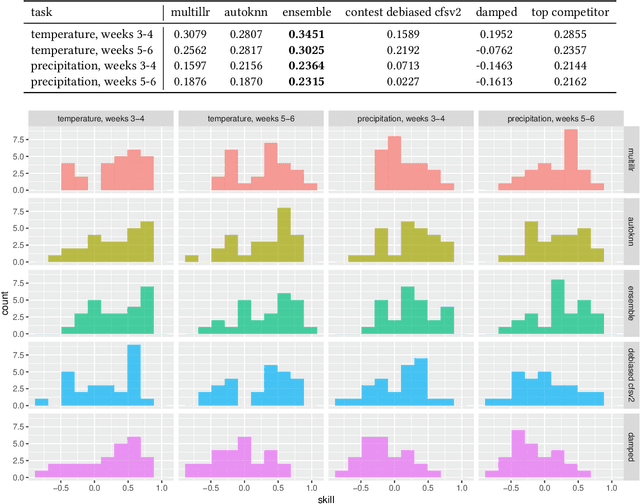
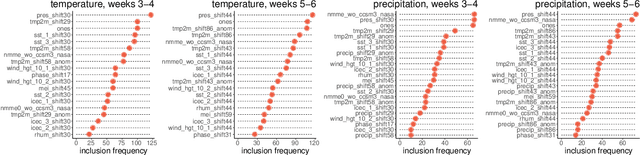
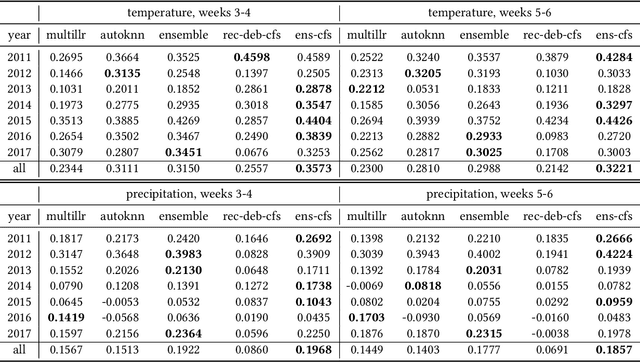
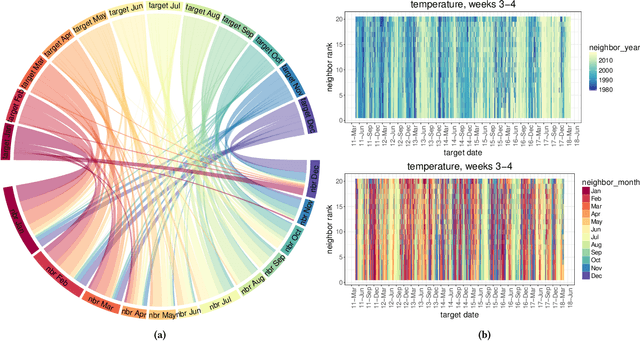
Water managers in the western United States (U.S.) rely on longterm forecasts of temperature and precipitation to prepare for droughts and other wet weather extremes. To improve the accuracy of these longterm forecasts, the Bureau of Reclamation and the National Oceanic and Atmospheric Administration (NOAA) launched the Subseasonal Climate Forecast Rodeo, a year-long real-time forecasting challenge, in which participants aimed to skillfully predict temperature and precipitation in the western U.S. two to four weeks and four to six weeks in advance. Here we present and evaluate our machine learning approach to the Rodeo and release our SubseasonalRodeo dataset, collected to train and evaluate our forecasting system. Our system is an ensemble of two regression models. The first integrates the diverse collection of meteorological measurements and dynamic model forecasts in the SubseasonalRodeo dataset and prunes irrelevant predictors using a customized multitask model selection procedure. The second uses only historical measurements of the target variable (temperature or precipitation) and introduces multitask nearest neighbor features into a weighted local linear regression. Each model alone is significantly more accurate than the operational U.S. Climate Forecasting System (CFSv2), and our ensemble skill exceeds that of the top Rodeo competitor for each target variable and forecast horizon. We hope that both our dataset and our methods will serve as valuable benchmarking tools for the subseasonal forecasting problem.