 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hashing via Householder Quantization
Nov 07, 2023Hashing is at the heart of large-scale image similarity search, and recent methods have been substantially improved through deep learning techniques. Such algorithms typically learn continuous embeddings of the data. To avoid a subsequent costly binarization step, a common solution is to employ loss functions that combine a similarity learning term (to ensure similar images are grouped to nearby embeddings) and a quantization penalty term (to ensure that the embedding entries are close to binarized entries, e.g., -1 or 1). Still, the interaction between these two terms can make learning harder and the embeddings worse. We propose an alternative quantization strategy that decomposes the learning problem in two stages: first, perform similarity learning over the embedding space with no quantization; second, find an optimal orthogonal transformation of the embeddings so each coordinate of the embedding is close to its sign, and then quantize the transformed embedding through the sign function. In the second step, we parametrize orthogonal transformations using Householder matrices to efficiently leverage stochastic gradient descent. Since similarity measures are usually invariant under orthogonal transformations, this quantization strategy comes at no cost in terms of performance. The resulting algorithm is unsupervised, fast, hyperparameter-free and can be run on top of any existing deep hashing or metric learning algorithm. We provide extensive experimental results showing that this approach leads to state-of-the-art performance on widely used image datasets, and, unlike other quantization strategies, brings consistent improvements in performance to existing deep hashing algorithms.
A spectral least-squares-type method for heavy-tailed corrupted regression with unknown covariance \& heterogeneous noise
Sep 06, 2022We revisit heavy-tailed corrupted least-squares linear regression assuming to have a corrupted $n$-sized label-feature sample of at most $\epsilon n$ arbitrary outliers. We wish to estimate a $p$-dimensional parameter $b^*$ given such sample of a label-feature pair $(y,x)$ satisfying $y=\langle x,b^*\rangle+\xi$ with heavy-tailed $(x,\xi)$. We only assume $x$ is $L^4-L^2$ hypercontractive with constant $L>0$ and has covariance matrix $\Sigma$ with minimum eigenvalue $1/\mu^2>0$ and bounded condition number $\kappa>0$. The noise $\xi$ can be arbitrarily dependent on $x$ and nonsymmetric as long as $\xi x$ has finite covariance matrix $\Xi$. We propose a near-optimal computationally tractable estimator, based on the power method, assuming no knowledge on $(\Sigma,\Xi)$ nor the operator norm of $\Xi$. With probability at least $1-\delta$, our proposed estimator attains the statistical rate $\mu^2\Vert\Xi\Vert^{1/2}(\frac{p}{n}+\frac{\log(1/\delta)}{n}+\epsilon)^{1/2}$ and breakdown-point $\epsilon\lesssim\frac{1}{L^4\kappa^2}$, both optimal in the $\ell_2$-norm, assuming the near-optimal minimum sample size $L^4\kappa^2(p\log p + \log(1/\delta))\lesssim n$, up to a log factor. To the best of our knowledge, this is the first computationally tractable algorithm satisfying simultaneously all the mentioned properties. Our estimator is based on a two-stage Multiplicative Weight Update algorithm. The first stage estimates a descent direction $\hat v$ with respect to the (unknown) pre-conditioned inner product $\langle\Sigma(\cdot),\cdot\rangle$. The second stage estimate the descent direction $\Sigma\hat v$ with respect to the (known) inner product $\langle\cdot,\cdot\rangle$, without knowing nor estimating $\Sigma$.
Solving SDPs for synchronization and MaxCut problems via the Grothendieck inequality
Mar 29, 2017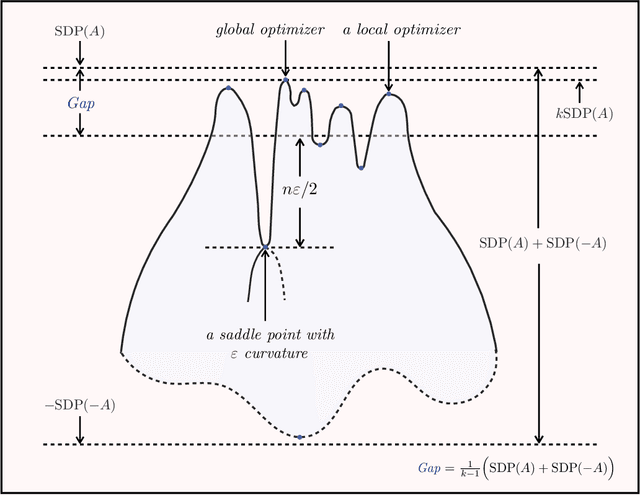
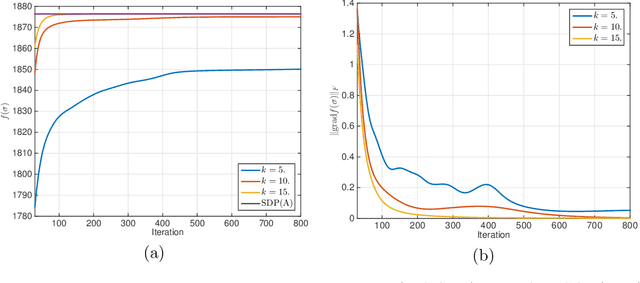
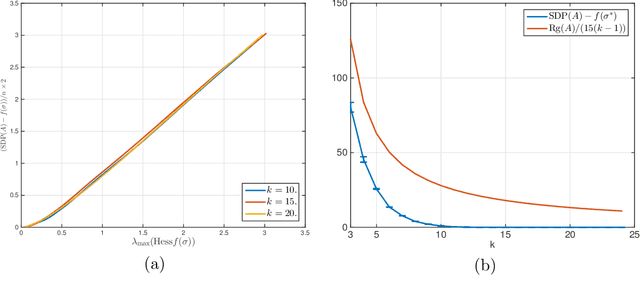
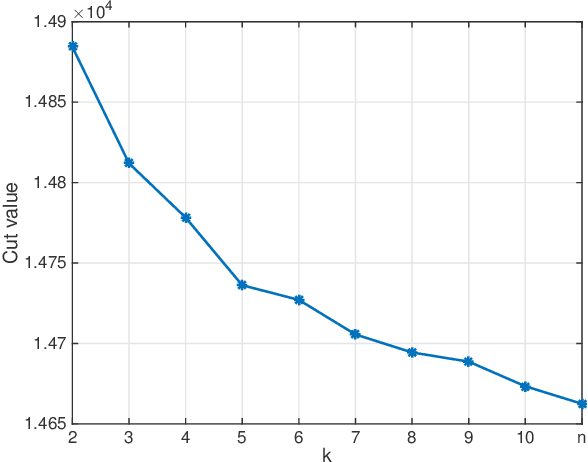
A number of statistical estimation problems can be addressed by semidefinite programs (SDP). While SDPs are solvable in polynomial time using interior point methods, in practice generic SDP solvers do not scale well to high-dimensional problems. In order to cope with this problem, Burer and Monteiro proposed a non-convex rank-constrained formulation, which has good performance in practice but is still poorly understood theoretically. In this paper we study the rank-constrained version of SDPs arising in MaxCut and in synchronization problems. We establish a Grothendieck-type inequality that proves that all the local maxima and dangerous saddle points are within a small multiplicative gap from the global maximum. We use this structural information to prove that SDPs can be solved within a known accuracy, by applying the Riemannian trust-region method to this non-convex problem, while constraining the rank to be of order one. For the MaxCut problem, our inequality implies that any local maximizer of the rank-constrained SDP provides a $ (1 - 1/(k-1)) \times 0.878$ approximation of the MaxCut, when the rank is fixed to $k$. We then apply our results to data matrices generated according to the Gaussian ${\mathbb Z}_2$ synchronization problem, and the two-groups stochastic block model with large bounded degree. We prove that the error achieved by local maximizers undergoes a phase transition at the same threshold as for information-theoretically optimal methods.