 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Commercial AI Chatbots as News Intermediaries
May 21, 2026AI chatbots are rapidly shaping how people encounter the news, yet no prior study has systematically measured how accurately these systems, with their proprietary search integrations and retrieval-synthesis pipelines, handle emerging facts across languages and regions. We present a 14-day (February 9-22, 2026) evaluation of six AI chatbots (Gemini 3 Flash and Pro, Grok 4, Claude 4.5 Sonnet, GPT-5 and GPT-4o mini) on 2,100 factual questions derived from same-day BBC News reporting across six regional services (US & Canada, Arabic, Afrique, Hindi, Russian, Turkish). The best systems achieve over 90% multiple-choice accuracy on questions about events reported hours earlier. The same systems, however, lose 11-13% under free-response evaluation, and 16-17% across the cohort. We further characterize three failure patterns. First, every model achieves its lowest accuracy on Hindi (79% vs. 89-91% elsewhere) and citations indicate an Anglophone retrieval bias (e.g., models answering Hindi queries cite English Wikipedia more than any Hindi outlet). Second, retrieval, not reasoning, failures drive over 70% of all errors. When models retrieve a correct source, they often extract the correct answer; the problem is to land on the right source in the first place. Third, models achieving 88-96% accuracy on well-formed questions drop to 19-70% when questions contain subtle false premises, with the most vulnerable model accepting fabricated facts 64% of the time. We also identify a detection-accuracy paradox: the best false-premise detector ranks second in adversarial accuracy (abstention rate), while a weaker detector ranks first, showing that premise detection and answer recovery are partially independent capabilities. Overall, these suggest that high accuracy can mask systematic regional inequity, near-total dependence on retrieval infrastructure, and vulnerability to imperfect queries real users pose.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Cost-of-Pass: An Economic Framework for Evaluating Language Models
Apr 17, 2025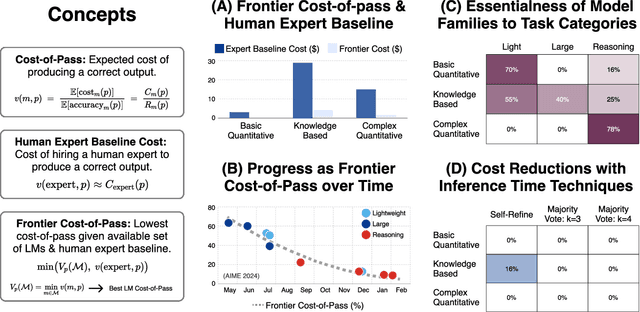
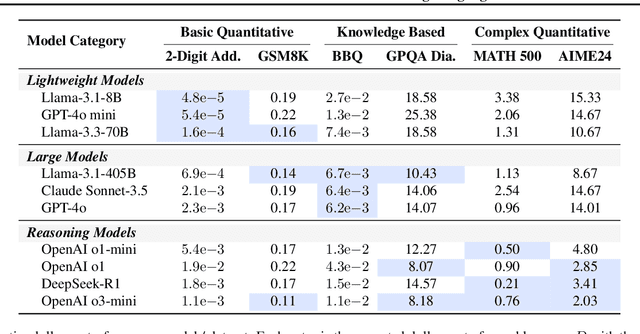
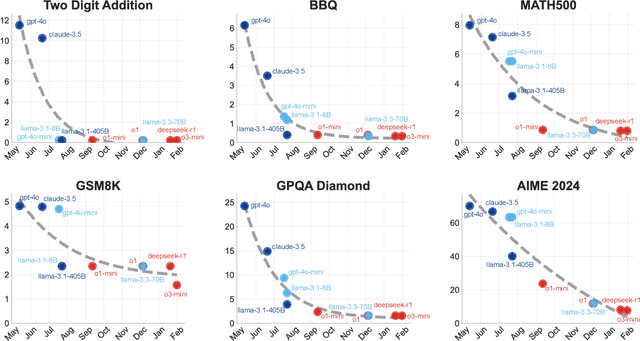

The widespread adoption of AI systems in the economy hinges on their ability to generate economic value that outweighs their inference costs. Evaluating this tradeoff requires metrics that account for both performance and costs. We propose a framework grounded in production theory for evaluating language models by combining accuracy and inference cost. We introduce "cost-of-pass", the expected monetary cost of generating a correct solution. We then define the "frontier cost-of-pass" as the minimum cost-of-pass achievable across available models or the "human-expert, using the approximate cost of hiring an expert. Our analysis reveals distinct economic insights. First, lightweight models are most cost-effective for basic quantitative tasks, large models for knowledge-intensive ones, and reasoning models for complex quantitative problems, despite higher per-token costs. Second, tracking this frontier cost-of-pass over the past year reveals significant progress, particularly for complex quantitative tasks where the cost has roughly halved every few months. Third, to trace key innovations driving this progress, we examine counterfactual frontiers: estimates of cost-efficiency without specific model classes. We find that innovations in lightweight, large, and reasoning models have been essential for pushing the frontier in basic quantitative, knowledge-intensive, and complex quantitative tasks, respectively. Finally, we assess the cost-reductions afforded by common inference-time techniques like majority voting and self-refinement, finding that their marginal accuracy gains rarely justify their costs. Our findings underscore that complementary model-level innovations are the primary drivers of cost-efficiency, and our economic framework provides a principled tool for measuring this progress and guiding deployment.
Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory
Apr 10, 2025Despite their impressive performance on complex tasks, current language models (LMs) typically operate in a vacuum: Each input query is processed separately, without retaining insights from previous attempts. Here, we present Dynamic Cheatsheet (DC), a lightweight framework that endows a black-box LM with a persistent, evolving memory. Rather than repeatedly re-discovering or re-committing the same solutions and mistakes, DC enables models to store and reuse accumulated strategies, code snippets, and general problem-solving insights at inference time. This test-time learning enhances performance substantially across a range of tasks without needing explicit ground-truth labels or human feedback. Leveraging DC, Claude 3.5 Sonnet's accuracy more than doubled on AIME math exams once it began retaining algebraic insights across questions. Similarly, GPT-4o's success rate on Game of 24 increased from 10% to 99% after the model discovered and reused a Python-based solution. In tasks prone to arithmetic mistakes, such as balancing equations, DC enabled GPT-4o and Claude to reach near-perfect accuracy by recalling previously validated code, whereas their baselines stagnated around 50%. Beyond arithmetic challenges, DC yields notable accuracy gains on knowledge-demanding tasks. Claude achieved a 9% improvement in GPQA-Diamond and an 8% boost on MMLU-Pro problems. Crucially, DC's memory is self-curated, focusing on concise, transferable snippets rather than entire transcript. Unlike finetuning or static retrieval methods, DC adapts LMs' problem-solving skills on the fly, without modifying their underlying parameters. Overall, our findings present DC as a promising approach for augmenting LMs with persistent memory, bridging the divide between isolated inference events and the cumulative, experience-driven learning characteristic of human cognition.
Belief in the Machine: Investigating Epistemological Blind Spots of Language Models
Oct 28, 2024As language models (LMs) become integral to fields like healthcare, law, and journalism, their ability to differentiate between fact, belief, and knowledge is essential for reliable decision-making. Failure to grasp these distinctions can lead to significant consequences in areas such as medical diagnosis, legal judgments, and dissemination of fake news. Despite this, current literature has largely focused on more complex issues such as theory of mind, overlooking more fundamental epistemic challenges. This study systematically evaluates the epistemic reasoning capabilities of modern LMs, including GPT-4, Claude-3, and Llama-3, using a new dataset, KaBLE, consisting of 13,000 questions across 13 tasks. Our results reveal key limitations. First, while LMs achieve 86% accuracy on factual scenarios, their performance drops significantly with false scenarios, particularly in belief-related tasks. Second, LMs struggle with recognizing and affirming personal beliefs, especially when those beliefs contradict factual data, which raises concerns for applications in healthcare and counseling, where engaging with a person's beliefs is critical. Third, we identify a salient bias in how LMs process first-person versus third-person beliefs, performing better on third-person tasks (80.7%) compared to first-person tasks (54.4%). Fourth, LMs lack a robust understanding of the factive nature of knowledge, namely, that knowledge inherently requires truth. Fifth, LMs rely on linguistic cues for fact-checking and sometimes bypass the deeper reasoning. These findings highlight significant concerns about current LMs' ability to reason about truth, belief, and knowledge while emphasizing the need for advancements in these areas before broad deployment in critical sectors.
Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
May 30, 2024



Legal practice has witnessed a sharp rise in products incorporating artificial intelligence (AI). Such tools are designed to assist with a wide range of core legal tasks, from search and summarization of caselaw to document drafting. But the large language models used in these tools are prone to "hallucinate," or make up false information, making their use risky in high-stakes domains. Recently, certain legal research providers have touted methods such as retrieval-augmented generation (RAG) as "eliminating" (Casetext, 2023) or "avoid[ing]" hallucinations (Thomson Reuters, 2023), or guaranteeing "hallucination-free" legal citations (LexisNexis, 2023). Because of the closed nature of these systems, systematically assessing these claims is challenging. In this article, we design and report on the first preregistered empirical evaluation of AI-driven legal research tools. We demonstrate that the providers' claims are overstated. While hallucinations are reduced relative to general-purpose chatbots (GPT-4), we find that the AI research tools made by LexisNexis (Lexis+ AI) and Thomson Reuters (Westlaw AI-Assisted Research and Ask Practical Law AI) each hallucinate between 17% and 33% of the time. We also document substantial differences between systems in responsiveness and accuracy. Our article makes four key contributions. It is the first to assess and report the performance of RAG-based proprietary legal AI tools. Second, it introduces a comprehensive, preregistered dataset for identifying and understanding vulnerabilities in these systems. Third, it proposes a clear typology for differentiating between hallucinations and accurate legal responses. Last, it provides evidence to inform the responsibilities of legal professionals in supervising and verifying AI outputs, which remains a central open question for the responsible integration of AI into law.
Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
Jan 23, 2024We introduce meta-prompting, an effective scaffolding technique designed to enhance the functionality of language models (LMs). This approach transforms a single LM into a multi-faceted conductor, adept at managing and integrating multiple independent LM queries. By employing high-level instructions, meta-prompting guides the LM to break down complex tasks into smaller, more manageable subtasks. These subtasks are then handled by distinct "expert" instances of the same LM, each operating under specific, tailored instructions. Central to this process is the LM itself, in its role as the conductor, which ensures seamless communication and effective integration of the outputs from these expert models. It additionally employs its inherent critical thinking and robust verification processes to refine and authenticate the end result. This collaborative prompting approach empowers a single LM to simultaneously act as a comprehensive orchestrator and a panel of diverse experts, significantly enhancing its performance across a wide array of tasks. The zero-shot, task-agnostic nature of meta-prompting greatly simplifies user interaction by obviating the need for detailed, task-specific instructions. Furthermore, our research demonstrates the seamless integration of external tools, such as a Python interpreter, into the meta-prompting framework, thereby broadening its applicability and utility. Through rigorous experimentation with GPT-4, we establish the superiority of meta-prompting over conventional scaffolding methods: When averaged across all tasks, including the Game of 24, Checkmate-in-One, and Python Programming Puzzles, meta-prompting, augmented with a Python interpreter functionality, surpasses standard prompting by 17.1%, expert (dynamic) prompting by 17.3%, and multipersona prompting by 15.2%.
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
Jan 02, 2024



Large language models (LLMs) have the potential to transform the practice of law, but this potential is threatened by the presence of legal hallucinations -- responses from these models that are not consistent with legal facts. We investigate the extent of these hallucinations using an original suite of legal queries, comparing LLMs' responses to structured legal metadata and examining their consistency. Our work makes four key contributions: (1) We develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. (2) We find that legal hallucinations are alarmingly prevalent, occurring between 69% of the time with ChatGPT 3.5 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. (3) We illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. (4) We provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, these findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
A Benchmark for Learning to Translate a New Language from One Grammar Book
Sep 28, 2023



Large language models (LLMs) can perform impressive feats with in-context learning or lightweight finetuning. It is natural to wonder how well these models adapt to genuinely new tasks, but how does one find tasks that are unseen in internet-scale training sets? We turn to a field that is explicitly motivated and bottlenecked by a scarcity of web data: low-resource languages. In this paper, we introduce MTOB (Machine Translation from One Book), a benchmark for learning to translate between English and Kalamang -- a language with less than 200 speakers and therefore virtually no presence on the web -- using several hundred pages of field linguistics reference materials. This task framing is novel in that it asks a model to learn a language from a single human-readable book of grammar explanations, rather than a large mined corpus of in-domain data, more akin to L2 learning than L1 acquisition. We demonstrate that baselines using current LLMs are promising but fall short of human performance, achieving 44.7 chrF on Kalamang to English translation and 45.8 chrF on English to Kalamang translation, compared to 51.6 and 57.0 chrF by a human who learned Kalamang from the same reference materials. We hope that MTOB will help measure LLM capabilities along a new dimension, and that the methods developed to solve it could help expand access to language technology for underserved communities by leveraging qualitatively different kinds of data than traditional machine translation.
Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
Sep 25, 2023Training large language models to follow instructions makes them perform better on a wide range of tasks, generally becoming more helpful. However, a perfectly helpful model will follow even the most malicious instructions and readily generate harmful content. In this paper, we raise concerns over the safety of models that only emphasize helpfulness, not safety, in their instruction-tuning. We show that several popular instruction-tuned models are highly unsafe. Moreover, we show that adding just 3% safety examples (a few hundred demonstrations) in the training set when fine-tuning a model like LLaMA can substantially improve their safety. Our safety-tuning does not make models significantly less capable or helpful as measured by standard benchmarks. However, we do find a behavior of exaggerated safety, where too much safety-tuning makes models refuse to respond to reasonable prompts that superficially resemble unsafe ones. Our study sheds light on trade-offs in training LLMs to follow instructions and exhibit safe behavior.