 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Teams Hold Experts Back
Feb 03, 2026Multi-agent LLM systems are increasingly deployed as autonomous collaborators, where agents interact freely rather than execute fixed, pre-specified workflows. In such settings, effective coordination cannot be fully designed in advance and must instead emerge through interaction. However, most prior work enforces coordination through fixed roles, workflows, or aggregation rules, leaving open the question of how well self-organizing teams perform when coordination is unconstrained. Drawing on organizational psychology, we study whether self-organizing LLM teams achieve strong synergy, where team performance matches or exceeds the best individual member. Across human-inspired and frontier ML benchmarks, we find that -- unlike human teams -- LLM teams consistently fail to match their expert agent's performance, even when explicitly told who the expert is, incurring performance losses of up to 37.6%. Decomposing this failure, we show that expert leveraging, rather than identification, is the primary bottleneck. Conversational analysis reveals a tendency toward integrative compromise -- averaging expert and non-expert views rather than appropriately weighting expertise -- which increases with team size and correlates negatively with performance. Interestingly, this consensus-seeking behavior improves robustness to adversarial agents, suggesting a trade-off between alignment and effective expertise utilization. Our findings reveal a significant gap in the ability of self-organizing multi-agent teams to harness the collective expertise of their members.
Cost-of-Pass: An Economic Framework for Evaluating Language Models
Apr 17, 2025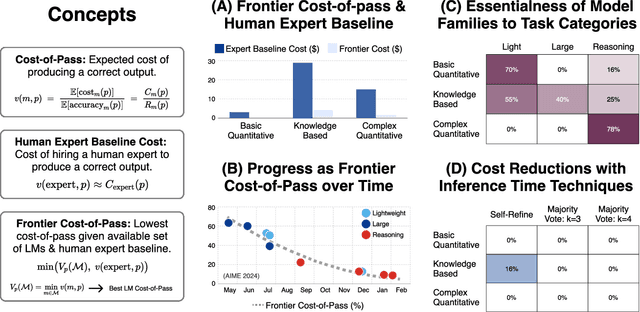
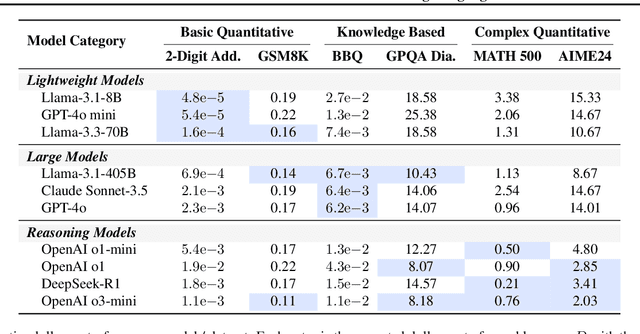
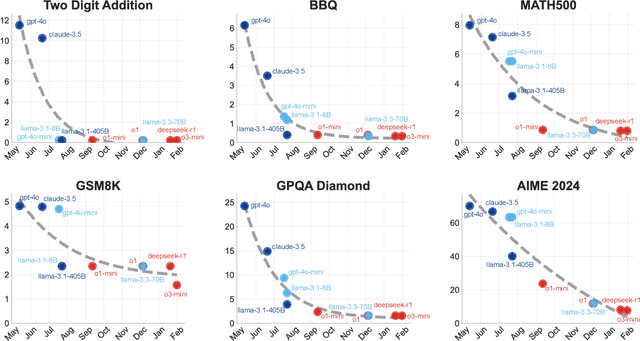

The widespread adoption of AI systems in the economy hinges on their ability to generate economic value that outweighs their inference costs. Evaluating this tradeoff requires metrics that account for both performance and costs. We propose a framework grounded in production theory for evaluating language models by combining accuracy and inference cost. We introduce "cost-of-pass", the expected monetary cost of generating a correct solution. We then define the "frontier cost-of-pass" as the minimum cost-of-pass achievable across available models or the "human-expert, using the approximate cost of hiring an expert. Our analysis reveals distinct economic insights. First, lightweight models are most cost-effective for basic quantitative tasks, large models for knowledge-intensive ones, and reasoning models for complex quantitative problems, despite higher per-token costs. Second, tracking this frontier cost-of-pass over the past year reveals significant progress, particularly for complex quantitative tasks where the cost has roughly halved every few months. Third, to trace key innovations driving this progress, we examine counterfactual frontiers: estimates of cost-efficiency without specific model classes. We find that innovations in lightweight, large, and reasoning models have been essential for pushing the frontier in basic quantitative, knowledge-intensive, and complex quantitative tasks, respectively. Finally, we assess the cost-reductions afforded by common inference-time techniques like majority voting and self-refinement, finding that their marginal accuracy gains rarely justify their costs. Our findings underscore that complementary model-level innovations are the primary drivers of cost-efficiency, and our economic framework provides a principled tool for measuring this progress and guiding deployment.
Towards Mechanistic Interpretability of Graph Transformers via Attention Graphs
Feb 17, 2025We introduce Attention Graphs, a new tool for mechanistic interpretability of Graph Neural Networks (GNNs) and Graph Transformers based on the mathematical equivalence between message passing in GNNs and the self-attention mechanism in Transformers. Attention Graphs aggregate attention matrices across Transformer layers and heads to describe how information flows among input nodes. Through experiments on homophilous and heterophilous node classification tasks, we analyze Attention Graphs from a network science perspective and find that: (1) When Graph Transformers are allowed to learn the optimal graph structure using all-to-all attention among input nodes, the Attention Graphs learned by the model do not tend to correlate with the input/original graph structure; and (2) For heterophilous graphs, different Graph Transformer variants can achieve similar performance while utilising distinct information flow patterns. Open source code: https://github.com/batu-el/understanding-inductive-biases-of-gnns