 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEER-ME: Assessing the Microeconomic Reasoning of Large Language Models
Feb 19, 2025



How should one judge whether a given large language model (LLM) can reliably perform economic reasoning? Most existing LLM benchmarks focus on specific applications and fail to present the model with a rich variety of economic tasks. A notable exception is Raman et al. [2024], who offer an approach for comprehensively benchmarking strategic decision-making; however, this approach fails to address the non-strategic settings prevalent in microeconomics, such as supply-and-demand analysis. We address this gap by taxonomizing microeconomic reasoning into $58$ distinct elements, focusing on the logic of supply and demand, each grounded in up to $10$ distinct domains, $5$ perspectives, and $3$ types. The generation of benchmark data across this combinatorial space is powered by a novel LLM-assisted data generation protocol that we dub auto-STEER, which generates a set of questions by adapting handwritten templates to target new domains and perspectives. Because it offers an automated way of generating fresh questions, auto-STEER mitigates the risk that LLMs will be trained to over-fit evaluation benchmarks; we thus hope that it will serve as a useful tool both for evaluating and fine-tuning models for years to come. We demonstrate the usefulness of our benchmark via a case study on $27$ LLMs, ranging from small open-source models to the current state of the art. We examined each model's ability to solve microeconomic problems across our whole taxonomy and present the results across a range of prompting strategies and scoring metrics.
Rationality Report Cards: Assessing the Economic Rationality of Large Language Models
Feb 14, 2024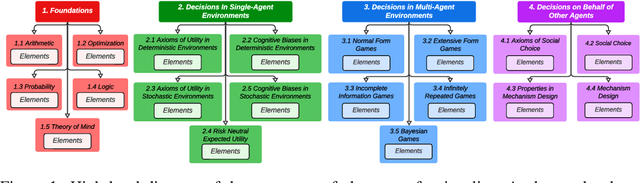
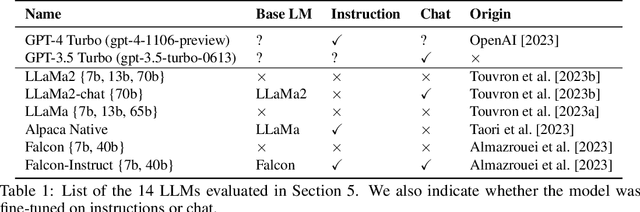

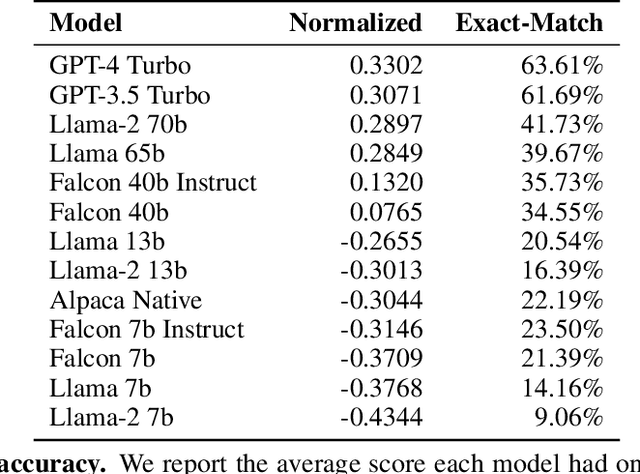
There is increasing interest in using LLMs as decision-making "agents." Doing so includes many degrees of freedom: which model should be used; how should it be prompted; should it be asked to introspect, conduct chain-of-thought reasoning, etc? Settling these questions -- and more broadly, determining whether an LLM agent is reliable enough to be trusted -- requires a methodology for assessing such an agent's economic rationality. In this paper, we provide one. We begin by surveying the economic literature on rational decision making, taxonomizing a large set of fine-grained "elements" that an agent should exhibit, along with dependencies between them. We then propose a benchmark distribution that quantitatively scores an LLMs performance on these elements and, combined with a user-provided rubric, produces a "rationality report card." Finally, we describe the results of a large-scale empirical experiment with 14 different LLMs, characterizing the both current state of the art and the impact of different model sizes on models' ability to exhibit rational behavior.