 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
DRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Oct 02, 2023Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Generating Benchmarks for Factuality Evaluation of Language Models
Jul 13, 2023

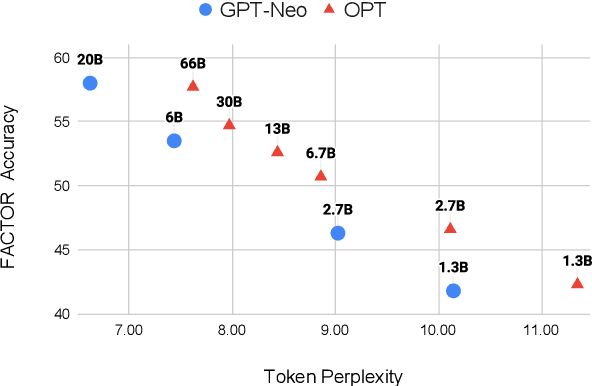
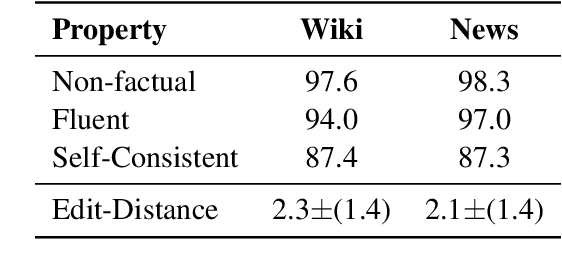
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators. We make our data and code publicly available in https://github.com/AI21Labs/factor.
In-Context Retrieval-Augmented Language Models
Jan 31, 2023Retrieval-Augmented Language Modeling (RALM) methods, that condition a language model (LM) on relevant documents from a grounding corpus during generation, have been shown to significantly improve language modeling while also providing a natural source attribution mechanism. Existing RALM approaches focus on modifying the LM architecture in order to facilitate the incorporation of external information, significantly complicating deployment. This paper proposes an under-explored alternative, which we dub In-Context RALM: leaving the LM architecture unchanged and prepending grounding documents to the input. We show that in-context RALM which uses off-the-shelf general purpose retrievers provides surprisingly large LM gains across model sizes and diverse corpora. We also demonstrate that the document retrieval and ranking mechanism can be specialized to the RALM setting to further boost performance. We conclude that in-context RALM has considerable potential to increase the prevalence of LM grounding, particularly in settings where a pretrained LM must be used without modification or even via API access. To that end, we make our code publicly available.
Parallel Context Windows Improve In-Context Learning of Large Language Models
Dec 21, 2022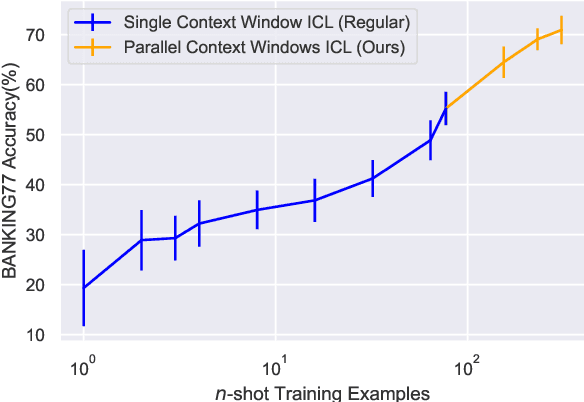
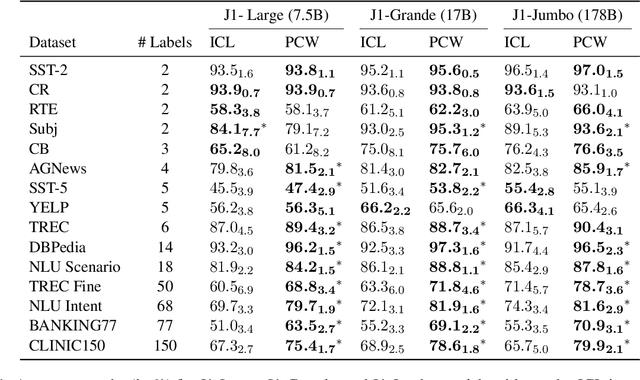
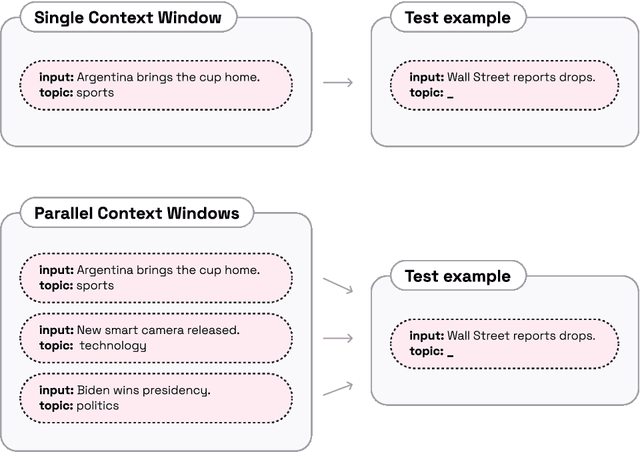
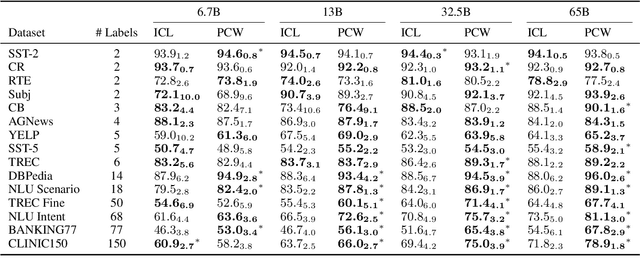
For applications that require processing large amounts of text at inference time, Large Language Models (LLMs) are handicapped by their limited context windows, which are typically 2048 tokens. In-context learning, an emergent phenomenon in LLMs in sizes above a certain parameter threshold, constitutes one significant example because it can only leverage training examples that fit into the context window. Existing efforts to address the context window limitation involve training specialized architectures, which tend to be smaller than the sizes in which in-context learning manifests due to the memory footprint of processing long texts. We present Parallel Context Windows (PCW), a method that alleviates the context window restriction for any off-the-shelf LLM without further training. The key to the approach is to carve a long context into chunks (``windows'') that fit within the architecture, restrict the attention mechanism to apply only within each window, and re-use the positional embeddings among the windows. We test the PCW approach on in-context learning with models that range in size between 750 million and 178 billion parameters, and show substantial improvements for tasks with diverse input and output spaces. Our results motivate further investigation of Parallel Context Windows as a method for applying off-the-shelf LLMs in other settings that require long text sequences.
What Are You Token About? Dense Retrieval as Distributions Over the Vocabulary
Dec 20, 2022



Dual encoders are now the dominant architecture for dense retrieval. Yet, we have little understanding of how they represent text, and why this leads to good performance. In this work, we shed light on this question via distributions over the vocabulary. We propose to interpret the vector representations produced by dual encoders by projecting them into the model's vocabulary space. We show that the resulting distributions over vocabulary tokens are intuitive and contain rich semantic information. We find that this view can explain some of the failure cases of dense retrievers. For example, the inability of models to handle tail entities can be explained via a tendency of the token distributions to forget some of the tokens of those entities. We leverage this insight and propose a simple way to enrich query and passage representations with lexical information at inference time, and show that this significantly improves performance compared to the original model in out-of-domain settings.
Standing on the Shoulders of Giant Frozen Language Models
Apr 21, 2022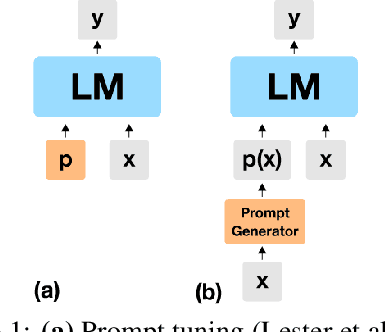
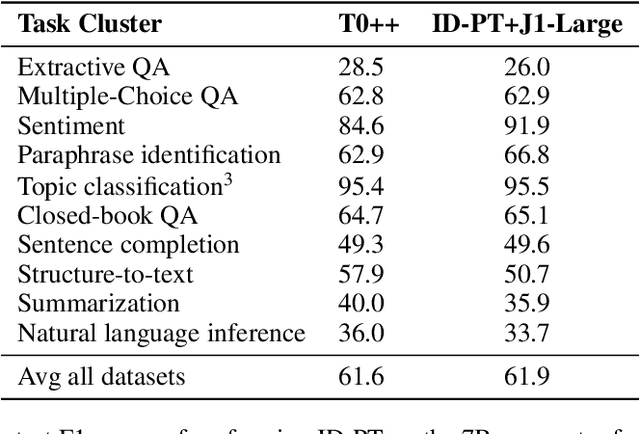
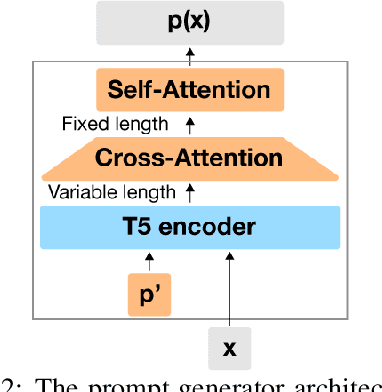

Huge pretrained language models (LMs) have demonstrated surprisingly good zero-shot capabilities on a wide variety of tasks. This gives rise to the appealing vision of a single, versatile model with a wide range of functionalities across disparate applications. However, current leading techniques for leveraging a "frozen" LM -- i.e., leaving its weights untouched -- still often underperform fine-tuning approaches which modify these weights in a task-dependent way. Those, in turn, suffer forgetfulness and compromise versatility, suggesting a tradeoff between performance and versatility. The main message of this paper is that current frozen-model techniques such as prompt tuning are only the tip of the iceberg, and more powerful methods for leveraging frozen LMs can do just as well as fine tuning in challenging domains without sacrificing the underlying model's versatility. To demonstrate this, we introduce three novel methods for leveraging frozen models: input-dependent prompt tuning, frozen readers, and recursive LMs, each of which vastly improves on current frozen-model approaches. Indeed, some of our methods even outperform fine-tuning approaches in domains currently dominated by the latter. The computational cost of each method is higher than that of existing frozen model methods, but still negligible relative to a single pass through a huge frozen LM. Each of these methods constitutes a meaningful contribution in its own right, but by presenting these contributions together we aim to convince the reader of a broader message that goes beyond the details of any given method: that frozen models have untapped potential and that fine-tuning is often unnecessary.
Transformer Language Models without Positional Encodings Still Learn Positional Information
Mar 30, 2022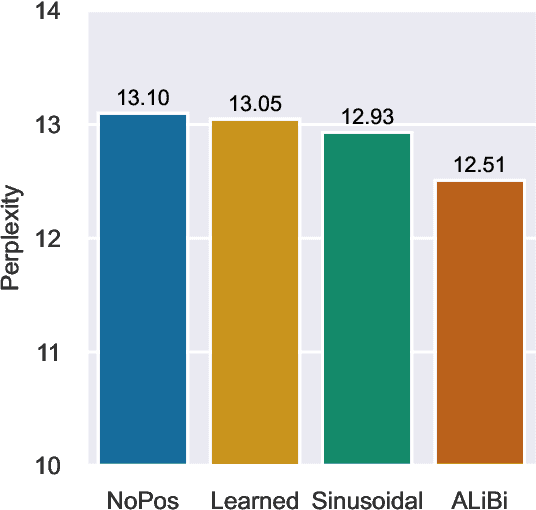
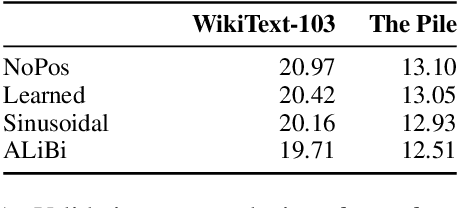
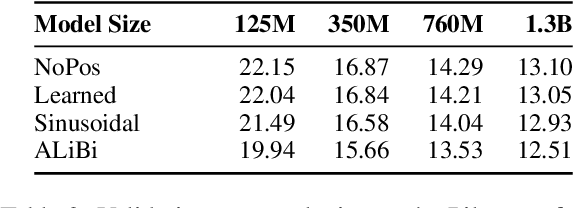
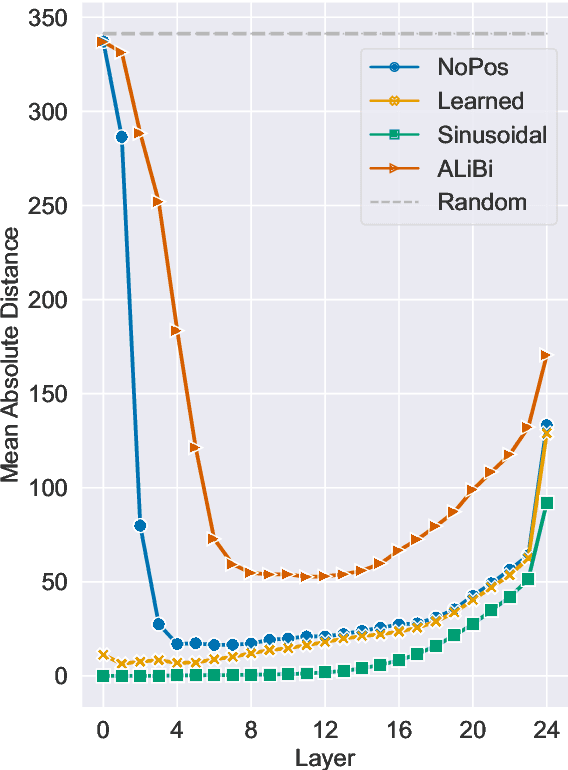
Transformers typically require some form of positional encoding, such as positional embeddings, to process natural language sequences. Surprisingly, we find that transformer language models without any explicit positional encoding are still competitive with standard models, and that this phenomenon is robust across different datasets, model sizes, and sequence lengths. Probing experiments reveal that such models acquire an implicit notion of absolute positions throughout the network, effectively compensating for the missing information. We conjecture that causal attention enables the model to infer the number of predecessors that each token can attend to, thereby approximating its absolute position.
Learning to Retrieve Passages without Supervision
Dec 14, 2021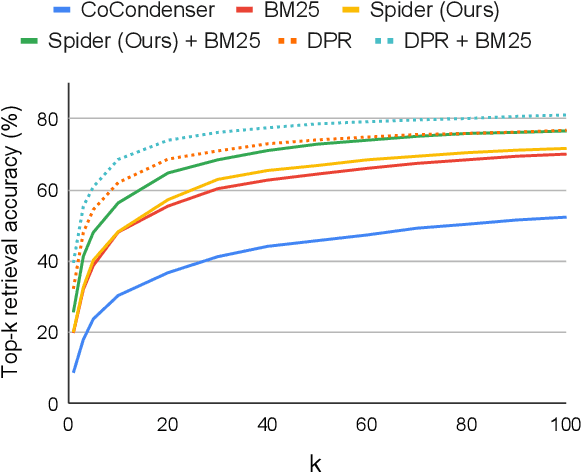
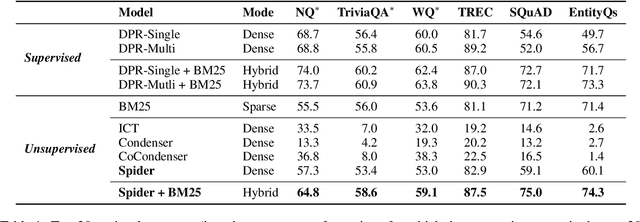
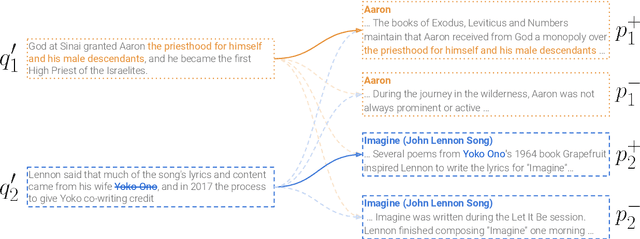
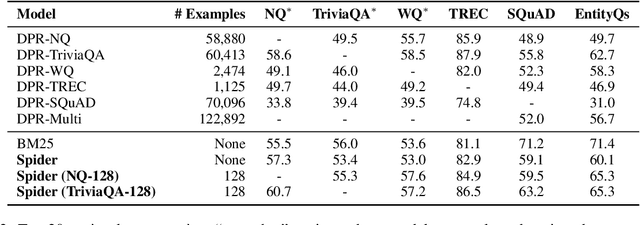
Dense retrievers for open-domain question answering (ODQA) have been shown to achieve impressive performance by training on large datasets of question-passage pairs. We investigate whether dense retrievers can be learned in a self-supervised fashion, and applied effectively without any annotations. We observe that existing pretrained models for retrieval struggle in this scenario, and propose a new pretraining scheme designed for retrieval: recurring span retrieval. We use recurring spans across passages in a document to create pseudo examples for contrastive learning. The resulting model -- Spider -- performs surprisingly well without any examples on a wide range of ODQA datasets, and is competitive with BM25, a strong sparse baseline. In addition, Spider often outperforms strong baselines like DPR trained on Natural Questions, when evaluated on questions from other datasets. Our hybrid retriever, which combines Spider with BM25, improves over its components across all datasets, and is often competitive with in-domain DPR models, which are trained on tens of thousands of examples.