 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Retrieve Passages without Supervision
Paper and Code
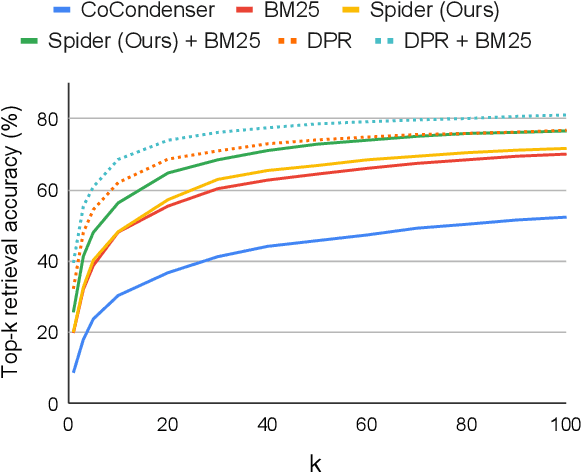
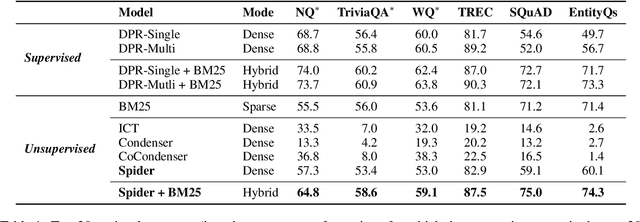
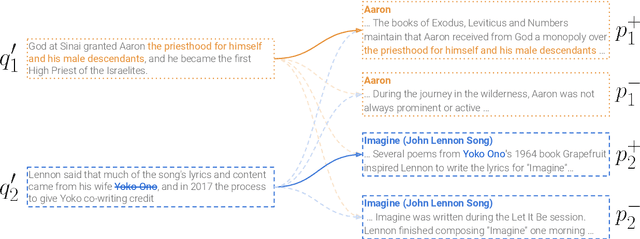
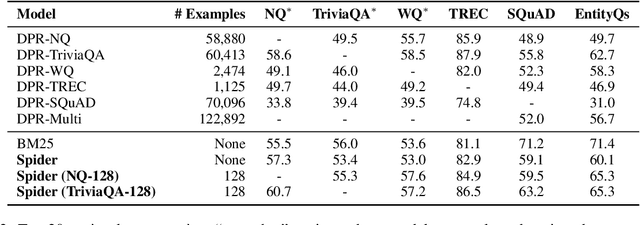
Dense retrievers for open-domain question answering (ODQA) have been shown to achieve impressive performance by training on large datasets of question-passage pairs. We investigate whether dense retrievers can be learned in a self-supervised fashion, and applied effectively without any annotations. We observe that existing pretrained models for retrieval struggle in this scenario, and propose a new pretraining scheme designed for retrieval: recurring span retrieval. We use recurring spans across passages in a document to create pseudo examples for contrastive learning. The resulting model -- Spider -- performs surprisingly well without any examples on a wide range of ODQA datasets, and is competitive with BM25, a strong sparse baseline. In addition, Spider often outperforms strong baselines like DPR trained on Natural Questions, when evaluated on questions from other datasets. Our hybrid retriever, which combines Spider with BM25, improves over its components across all datasets, and is often competitive with in-domain DPR models, which are trained on tens of thousands of examples.