 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexIP: Dynamic Control of Preservation and Personality for Customized Image Generation
Apr 10, 2025With the rapid advancement of 2D generative models, preserving subject identity while enabling diverse editing has emerged as a critical research focus. Existing methods typically face inherent trade-offs between identity preservation and personalized manipulation. We introduce FlexIP, a novel framework that decouples these objectives through two dedicated components: a Personalization Adapter for stylistic manipulation and a Preservation Adapter for identity maintenance. By explicitly injecting both control mechanisms into the generative model, our framework enables flexible parameterized control during inference through dynamic tuning of the weight adapter. Experimental results demonstrate that our approach breaks through the performance limitations of conventional methods, achieving superior identity preservation while supporting more diverse personalized generation capabilities (Project Page: https://flexip-tech.github.io/flexip/).
Embodied Understanding of Driving Scenarios
Mar 07, 2024
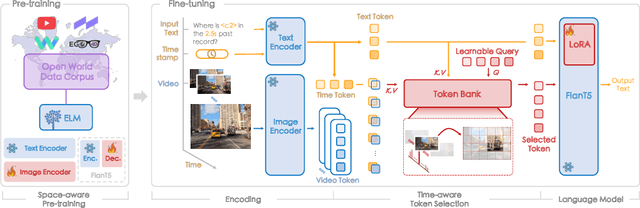
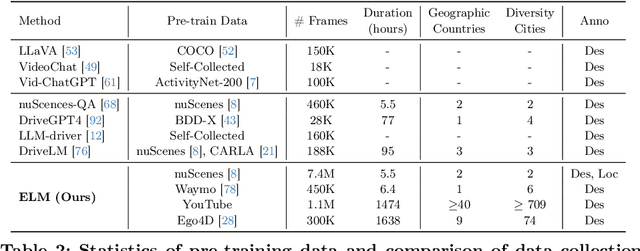
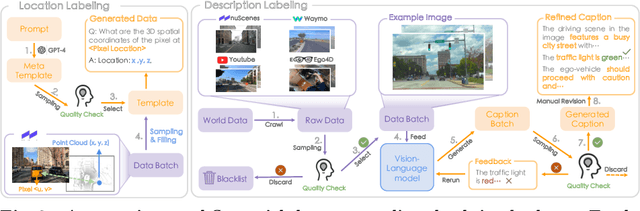
Embodied scene understanding serves as the cornerstone for autonomous agents to perceive, interpret, and respond to open driving scenarios. Such understanding is typically founded upon Vision-Language Models (VLMs). Nevertheless, existing VLMs are restricted to the 2D domain, devoid of spatial awareness and long-horizon extrapolation proficiencies. We revisit the key aspects of autonomous driving and formulate appropriate rubrics. Hereby, we introduce the Embodied Language Model (ELM), a comprehensive framework tailored for agents' understanding of driving scenes with large spatial and temporal spans. ELM incorporates space-aware pre-training to endow the agent with robust spatial localization capabilities. Besides, the model employs time-aware token selection to accurately inquire about temporal cues. We instantiate ELM on the reformulated multi-faced benchmark, and it surpasses previous state-of-the-art approaches in all aspects. All code, data, and models will be publicly shared.
Leveraging Vision-Centric Multi-Modal Expertise for 3D Object Detection
Oct 24, 2023Current research is primarily dedicated to advancing the accuracy of camera-only 3D object detectors (apprentice) through the knowledge transferred from LiDAR- or multi-modal-based counterparts (expert). However, the presence of the domain gap between LiDAR and camera features, coupled with the inherent incompatibility in temporal fusion, significantly hinders the effectiveness of distillation-based enhancements for apprentices. Motivated by the success of uni-modal distillation, an apprentice-friendly expert model would predominantly rely on camera features, while still achieving comparable performance to multi-modal models. To this end, we introduce VCD, a framework to improve the camera-only apprentice model, including an apprentice-friendly multi-modal expert and temporal-fusion-friendly distillation supervision. The multi-modal expert VCD-E adopts an identical structure as that of the camera-only apprentice in order to alleviate the feature disparity, and leverages LiDAR input as a depth prior to reconstruct the 3D scene, achieving the performance on par with other heterogeneous multi-modal experts. Additionally, a fine-grained trajectory-based distillation module is introduced with the purpose of individually rectifying the motion misalignment for each object in the scene. With those improvements, our camera-only apprentice VCD-A sets new state-of-the-art on nuScenes with a score of 63.1% NDS.
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.
VoxelFormer: Bird's-Eye-View Feature Generation based on Dual-view Attention for Multi-view 3D Object Detection
Apr 03, 2023In recent years, transformer-based detectors have demonstrated remarkable performance in 2D visual perception tasks. However, their performance in multi-view 3D object detection remains inferior to the state-of-the-art (SOTA) of convolutional neural network based detectors. In this work, we investigate this issue from the perspective of bird's-eye-view (BEV) feature generation. Specifically, we examine the BEV feature generation method employed by the transformer-based SOTA, BEVFormer, and identify its two limitations: (i) it only generates attention weights from BEV, which precludes the use of lidar points for supervision, and (ii) it aggregates camera view features to the BEV through deformable sampling, which only selects a small subset of features and fails to exploit all information. To overcome these limitations, we propose a novel BEV feature generation method, dual-view attention, which generates attention weights from both the BEV and camera view. This method encodes all camera features into the BEV feature. By combining dual-view attention with the BEVFormer architecture, we build a new detector named VoxelFormer. Extensive experiments are conducted on the nuScenes benchmark to verify the superiority of dual-view attention and VoxelForer. We observe that even only adopting 3 encoders and 1 historical frame during training, VoxelFormer still outperforms BEVFormer significantly. When trained in the same setting, VoxelFormer can surpass BEVFormer by 4.9% NDS point. Code is available at: https://github.com/Lizhuoling/VoxelFormer-public.git.
You Only Segment Once: Towards Real-Time Panoptic Segmentation
Mar 26, 2023



In this paper, we propose YOSO, a real-time panoptic segmentation framework. YOSO predicts masks via dynamic convolutions between panoptic kernels and image feature maps, in which you only need to segment once for both instance and semantic segmentation tasks. To reduce the computational overhead, we design a feature pyramid aggregator for the feature map extraction, and a separable dynamic decoder for the panoptic kernel generation. The aggregator re-parameterizes interpolation-first modules in a convolution-first way, which significantly speeds up the pipeline without any additional costs. The decoder performs multi-head cross-attention via separable dynamic convolution for better efficiency and accuracy. To the best of our knowledge, YOSO is the first real-time panoptic segmentation framework that delivers competitive performance compared to state-of-the-art models. Specifically, YOSO achieves 46.4 PQ, 45.6 FPS on COCO; 52.5 PQ, 22.6 FPS on Cityscapes; 38.0 PQ, 35.4 FPS on ADE20K; and 34.1 PQ, 7.1 FPS on Mapillary Vistas. Code is available at https://github.com/hujiecpp/YOSO.