 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingpath-VL Technical Report
Feb 12, 2026We present Singpath-VL, a vision-language large model, to fill the vacancy of AI assistant in cervical cytology. Recent advances in multi-modal large language models (MLLMs) have significantly propelled the field of computational pathology. However, their application in cytopathology, particularly cervical cytology, remains underexplored, primarily due to the scarcity of large-scale, high-quality annotated datasets. To bridge this gap, we first develop a novel three-stage pipeline to synthesize a million-scale image-description dataset. The pipeline leverages multiple general-purpose MLLMs as weak annotators, refines their outputs through consensus fusion and expert knowledge injection, and produces high-fidelity descriptions of cell morphology. Using this dataset, we then fine-tune the Qwen3-VL-4B model via a multi-stage strategy to create a specialized cytopathology MLLM. The resulting model, named Singpath-VL, demonstrates superior performance in fine-grained morphological perception and cell-level diagnostic classification. To advance the field, we will open-source a portion of the synthetic dataset and benchmark.
PrimitiveAnything: Human-Crafted 3D Primitive Assembly Generation with Auto-Regressive Transformer
May 07, 2025
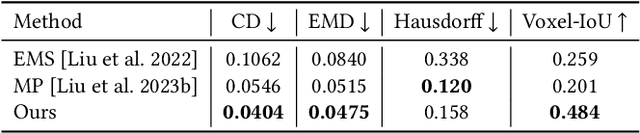
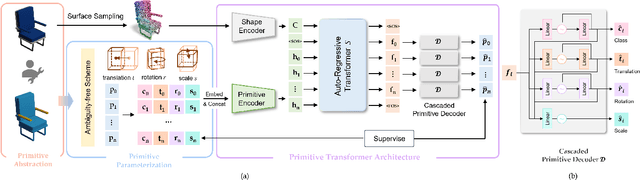
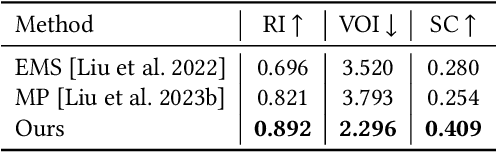
Shape primitive abstraction, which decomposes complex 3D shapes into simple geometric elements, plays a crucial role in human visual cognition and has broad applications in computer vision and graphics. While recent advances in 3D content generation have shown remarkable progress, existing primitive abstraction methods either rely on geometric optimization with limited semantic understanding or learn from small-scale, category-specific datasets, struggling to generalize across diverse shape categories. We present PrimitiveAnything, a novel framework that reformulates shape primitive abstraction as a primitive assembly generation task. PrimitiveAnything includes a shape-conditioned primitive transformer for auto-regressive generation and an ambiguity-free parameterization scheme to represent multiple types of primitives in a unified manner. The proposed framework directly learns the process of primitive assembly from large-scale human-crafted abstractions, enabling it to capture how humans decompose complex shapes into primitive elements. Through extensive experiments, we demonstrate that PrimitiveAnything can generate high-quality primitive assemblies that better align with human perception while maintaining geometric fidelity across diverse shape categories. It benefits various 3D applications and shows potential for enabling primitive-based user-generated content (UGC) in games. Project page: https://primitiveanything.github.io
FlexIP: Dynamic Control of Preservation and Personality for Customized Image Generation
Apr 10, 2025With the rapid advancement of 2D generative models, preserving subject identity while enabling diverse editing has emerged as a critical research focus. Existing methods typically face inherent trade-offs between identity preservation and personalized manipulation. We introduce FlexIP, a novel framework that decouples these objectives through two dedicated components: a Personalization Adapter for stylistic manipulation and a Preservation Adapter for identity maintenance. By explicitly injecting both control mechanisms into the generative model, our framework enables flexible parameterized control during inference through dynamic tuning of the weight adapter. Experimental results demonstrate that our approach breaks through the performance limitations of conventional methods, achieving superior identity preservation while supporting more diverse personalized generation capabilities (Project Page: https://flexip-tech.github.io/flexip/).
StdGEN: Semantic-Decomposed 3D Character Generation from Single Images
Nov 08, 2024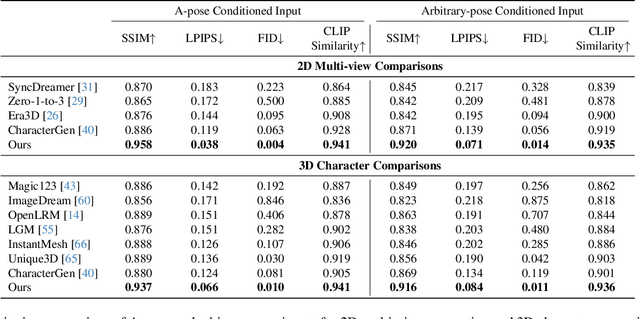
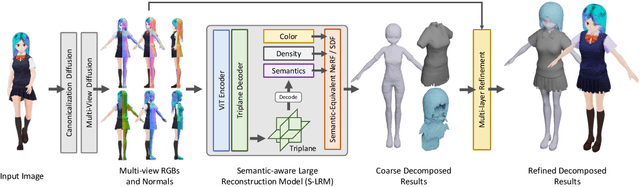
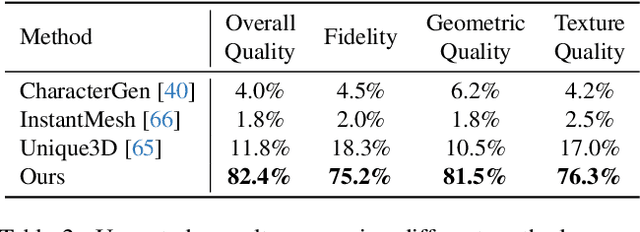
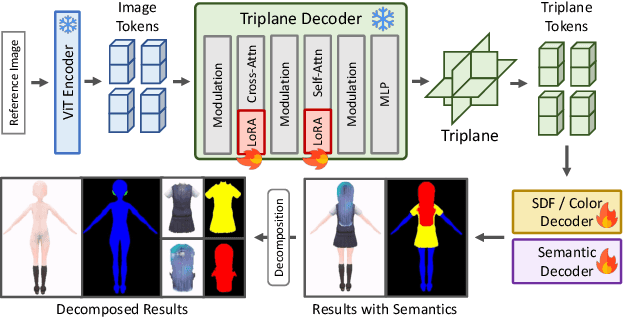
We present StdGEN, an innovative pipeline for generating semantically decomposed high-quality 3D characters from single images, enabling broad applications in virtual reality, gaming, and filmmaking, etc. Unlike previous methods which struggle with limited decomposability, unsatisfactory quality, and long optimization times, StdGEN features decomposability, effectiveness and efficiency; i.e., it generates intricately detailed 3D characters with separated semantic components such as the body, clothes, and hair, in three minutes. At the core of StdGEN is our proposed Semantic-aware Large Reconstruction Model (S-LRM), a transformer-based generalizable model that jointly reconstructs geometry, color and semantics from multi-view images in a feed-forward manner. A differentiable multi-layer semantic surface extraction scheme is introduced to acquire meshes from hybrid implicit fields reconstructed by our S-LRM. Additionally, a specialized efficient multi-view diffusion model and an iterative multi-layer surface refinement module are integrated into the pipeline to facilitate high-quality, decomposable 3D character generation. Extensive experiments demonstrate our state-of-the-art performance in 3D anime character generation, surpassing existing baselines by a significant margin in geometry, texture and decomposability. StdGEN offers ready-to-use semantic-decomposed 3D characters and enables flexible customization for a wide range of applications. Project page: https://stdgen.github.io
RLTF: Reinforcement Learning from Unit Test Feedback
Jul 10, 2023



The goal of program synthesis, or code generation, is to generate executable code based on given descriptions. Recently, there has been an increasing number of studies employing reinforcement learning (RL) to improve the performance of large language models (LLMs) for code. However, these RL methods have only used offline frameworks, limiting their exploration of new sample spaces. Additionally, current approaches that utilize unit test signals are rather simple, not accounting for specific error locations within the code. To address these issues, we proposed RLTF, i.e., Reinforcement Learning from Unit Test Feedback, a novel online RL framework with unit test feedback of multi-granularity for refining code LLMs. Our approach generates data in real-time during training and simultaneously utilizes fine-grained feedback signals to guide the model towards producing higher-quality code. Extensive experiments show that RLTF achieves state-of-the-art performance on the APPS and the MBPP benchmarks. Our code can be found at: https://github.com/Zyq-scut/RLTF.
Label Hierarchy Transition: Modeling Class Hierarchies to Enhance Deep Classifiers
Dec 04, 2021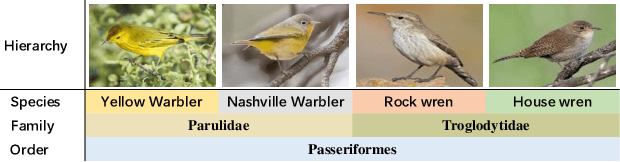
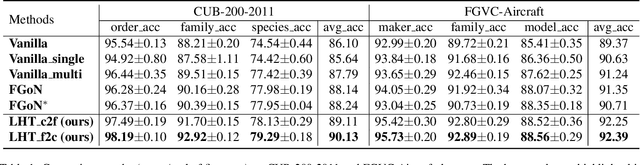
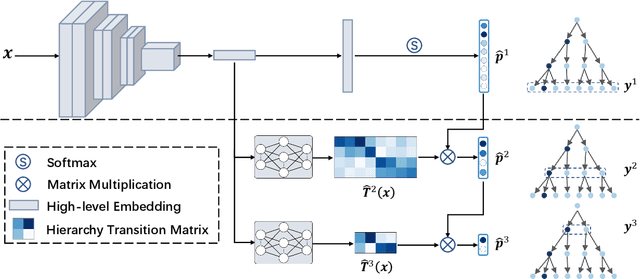
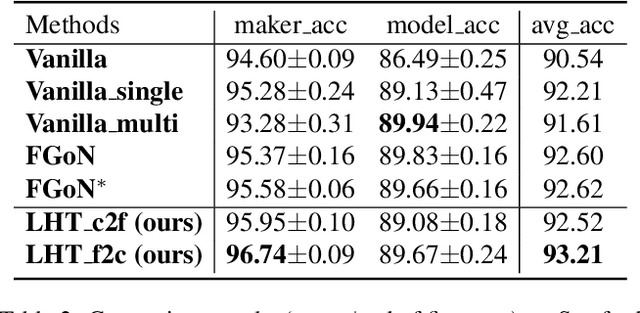
Hierarchical classification aims to sort the object into a hierarchy of categories. For example, a bird can be categorized according to a three-level hierarchy of order, family, and species. Existing methods commonly address hierarchical classification by decoupling it into several multi-class classification tasks. However, such a multi-task learning strategy fails to fully exploit the correlation among various categories across different hierarchies. In this paper, we propose Label Hierarchy Transition, a unified probabilistic framework based on deep learning, to address hierarchical classification. Specifically, we explicitly learn the label hierarchy transition matrices, whose column vectors represent the conditional label distributions of classes between two adjacent hierarchies and could be capable of encoding the correlation embedded in class hierarchies. We further propose a confusion loss, which encourages the classification network to learn the correlation across different label hierarchies during training. The proposed framework can be adapted to any existing deep network with only minor modifications. We experiment with three public benchmark datasets with various class hierarchies, and the results demonstrate the superiority of our approach beyond the prior arts. Source code will be made publicly available.
CoDiM: Learning with Noisy Labels via Contrastive Semi-Supervised Learning
Nov 23, 2021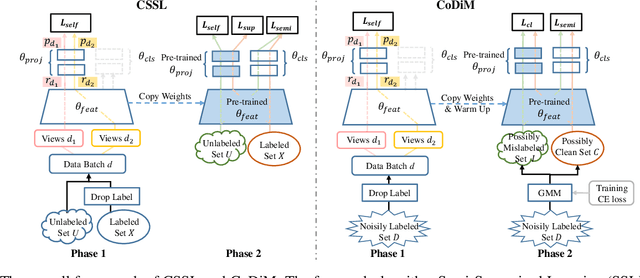
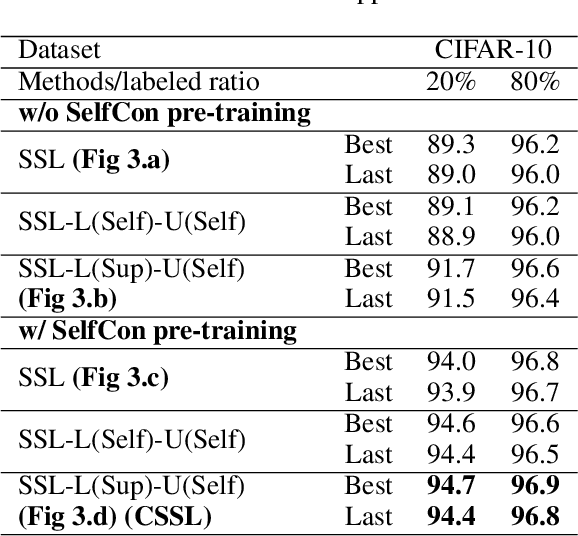
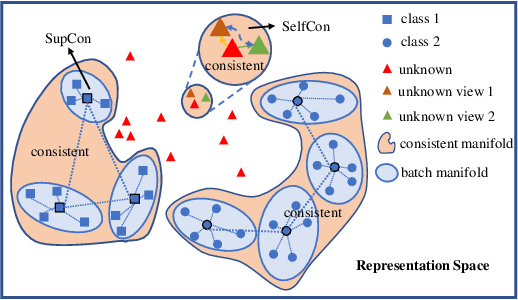
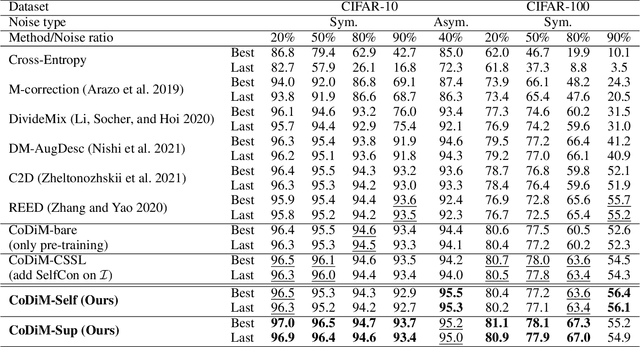
Labels are costly and sometimes unreliable. Noisy label learning, semi-supervised learning, and contrastive learning are three different strategies for designing learning processes requiring less annotation cost. Semi-supervised learning and contrastive learning have been recently demonstrated to improve learning strategies that address datasets with noisy labels. Still, the inner connections between these fields as well as the potential to combine their strengths together have only started to emerge. In this paper, we explore further ways and advantages to fuse them. Specifically, we propose CSSL, a unified Contrastive Semi-Supervised Learning algorithm, and CoDiM (Contrastive DivideMix), a novel algorithm for learning with noisy labels. CSSL leverages the power of classical semi-supervised learning and contrastive learning technologies and is further adapted to CoDiM, which learns robustly from multiple types and levels of label noise. We show that CoDiM brings consistent improvements and achieves state-of-the-art results on multiple benchmarks.