 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDiM: Learning with Noisy Labels via Contrastive Semi-Supervised Learning
Paper and Code
Nov 23, 2021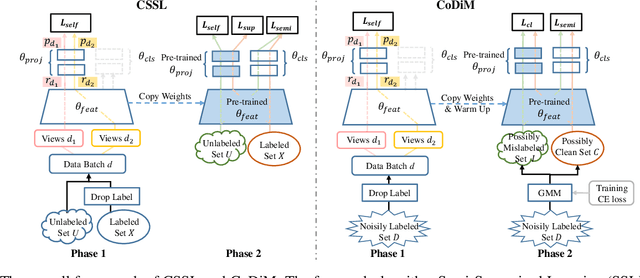
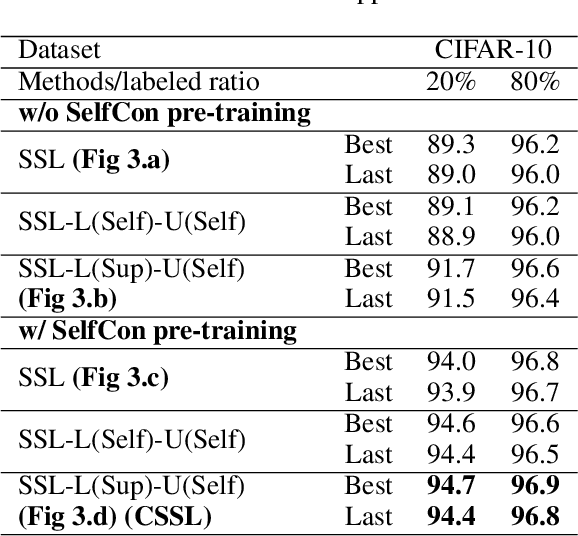
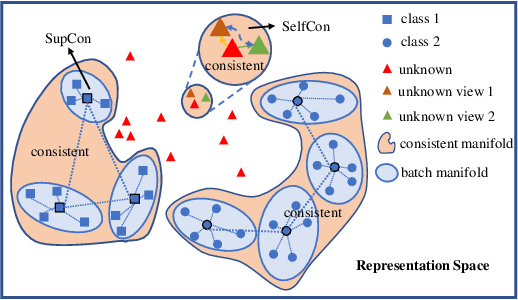
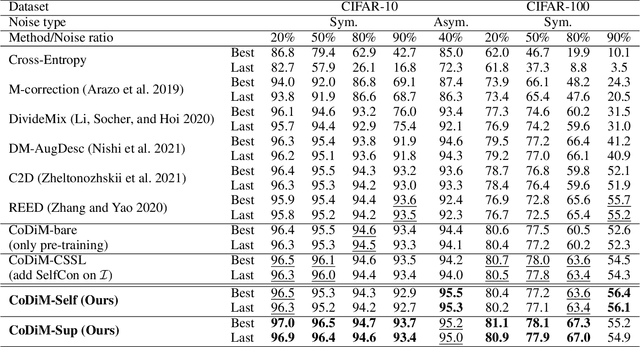
Labels are costly and sometimes unreliable. Noisy label learning, semi-supervised learning, and contrastive learning are three different strategies for designing learning processes requiring less annotation cost. Semi-supervised learning and contrastive learning have been recently demonstrated to improve learning strategies that address datasets with noisy labels. Still, the inner connections between these fields as well as the potential to combine their strengths together have only started to emerge. In this paper, we explore further ways and advantages to fuse them. Specifically, we propose CSSL, a unified Contrastive Semi-Supervised Learning algorithm, and CoDiM (Contrastive DivideMix), a novel algorithm for learning with noisy labels. CSSL leverages the power of classical semi-supervised learning and contrastive learning technologies and is further adapted to CoDiM, which learns robustly from multiple types and levels of label noise. We show that CoDiM brings consistent improvements and achieves state-of-the-art results on multiple benchmarks.