 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
ChebMixer: Efficient Graph Representation Learning with MLP Mixer
Mar 25, 2024Graph neural networks have achieved remarkable success in learning graph representations, especially graph Transformer, which has recently shown superior performance on various graph mining tasks. However, graph Transformer generally treats nodes as tokens, which results in quadratic complexity regarding the number of nodes during self-attention computation. The graph MLP Mixer addresses this challenge by using the efficient MLP Mixer technique from computer vision. However, the time-consuming process of extracting graph tokens limits its performance. In this paper, we present a novel architecture named ChebMixer, a newly graph MLP Mixer that uses fast Chebyshev polynomials-based spectral filtering to extract a sequence of tokens. Firstly, we produce multiscale representations of graph nodes via fast Chebyshev polynomial-based spectral filtering. Next, we consider each node's multiscale representations as a sequence of tokens and refine the node representation with an effective MLP Mixer. Finally, we aggregate the multiscale representations of nodes through Chebyshev interpolation. Owing to the powerful representation capabilities and fast computational properties of MLP Mixer, we can quickly extract more informative node representations to improve the performance of downstream tasks. The experimental results prove our significant improvements in a variety of scenarios ranging from graph node classification to medical image segmentation.
PAGE: Equilibrate Personalization and Generalization in Federated Learning
Oct 13, 2023Federated learning (FL) is becoming a major driving force behind machine learning as a service, where customers (clients) collaboratively benefit from shared local updates under the orchestration of the service provider (server). Representing clients' current demands and the server's future demand, local model personalization and global model generalization are separately investigated, as the ill-effects of data heterogeneity enforce the community to focus on one over the other. However, these two seemingly competing goals are of equal importance rather than black and white issues, and should be achieved simultaneously. In this paper, we propose the first algorithm to balance personalization and generalization on top of game theory, dubbed PAGE, which reshapes FL as a co-opetition game between clients and the server. To explore the equilibrium, PAGE further formulates the game as Markov decision processes, and leverages the reinforcement learning algorithm, which simplifies the solving complexity. Extensive experiments on four widespread datasets show that PAGE outperforms state-of-the-art FL baselines in terms of global and local prediction accuracy simultaneously, and the accuracy can be improved by up to 35.20% and 39.91%, respectively. In addition, biased variants of PAGE imply promising adaptiveness to demand shifts in practice.
Class Attention Transfer Based Knowledge Distillation
Apr 25, 2023Previous knowledge distillation methods have shown their impressive performance on model compression tasks, however, it is hard to explain how the knowledge they transferred helps to improve the performance of the student network. In this work, we focus on proposing a knowledge distillation method that has both high interpretability and competitive performance. We first revisit the structure of mainstream CNN models and reveal that possessing the capacity of identifying class discriminative regions of input is critical for CNN to perform classification. Furthermore, we demonstrate that this capacity can be obtained and enhanced by transferring class activation maps. Based on our findings, we propose class attention transfer based knowledge distillation (CAT-KD). Different from previous KD methods, we explore and present several properties of the knowledge transferred by our method, which not only improve the interpretability of CAT-KD but also contribute to a better understanding of CNN. While having high interpretability, CAT-KD achieves state-of-the-art performance on multiple benchmarks. Code is available at: https://github.com/GzyAftermath/CAT-KD.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model
Oct 28, 2021

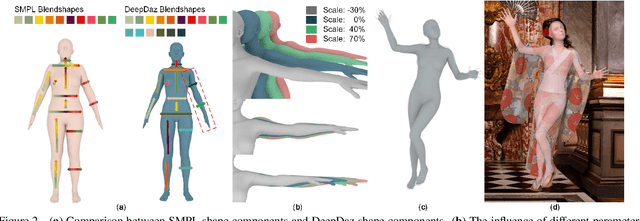
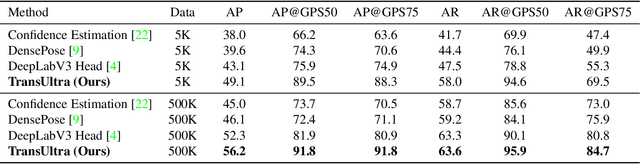
Recovering dense human poses from images plays a critical role in establishing an image-to-surface correspondence between RGB images and the 3D surface of the human body, serving the foundation of rich real-world applications, such as virtual humans, monocular-to-3d reconstruction. However, the popular DensePose-COCO dataset relies on a sophisticated manual annotation system, leading to severe limitations in acquiring the denser and more accurate annotated pose resources. In this work, we introduce a new 3D human-body model with a series of decoupled parameters that could freely control the generation of the body. Furthermore, we build a data generation system based on this decoupling 3D model, and construct an ultra dense synthetic benchmark UltraPose, containing around 1.3 billion corresponding points. Compared to the existing manually annotated DensePose-COCO dataset, the synthetic UltraPose has ultra dense image-to-surface correspondences without annotation cost and error. Our proposed UltraPose provides the largest benchmark and data resources for lifting the model capability in predicting more accurate dense poses. To promote future researches in this field, we also propose a transformer-based method to model the dense correspondence between 2D and 3D worlds. The proposed model trained on synthetic UltraPose can be applied to real-world scenarios, indicating the effectiveness of our benchmark and model.
* Accepted to ICCV 2021
WAS-VTON: Warping Architecture Search for Virtual Try-on Network
Aug 01, 2021
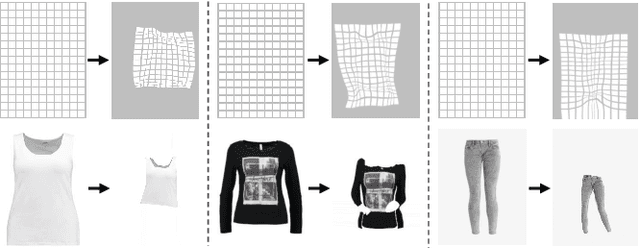

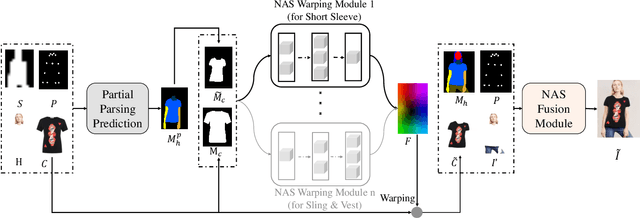
Despite recent progress on image-based virtual try-on, current methods are constraint by shared warping networks and thus fail to synthesize natural try-on results when faced with clothing categories that require different warping operations. In this paper, we address this problem by finding clothing category-specific warping networks for the virtual try-on task via Neural Architecture Search (NAS). We introduce a NAS-Warping Module and elaborately design a bilevel hierarchical search space to identify the optimal network-level and operation-level flow estimation architecture. Given the network-level search space, containing different numbers of warping blocks, and the operation-level search space with different convolution operations, we jointly learn a combination of repeatable warping cells and convolution operations specifically for the clothing-person alignment. Moreover, a NAS-Fusion Module is proposed to synthesize more natural final try-on results, which is realized by leveraging particular skip connections to produce better-fused features that are required for seamlessly fusing the warped clothing and the unchanged person part. We adopt an efficient and stable one-shot searching strategy to search the above two modules. Extensive experiments demonstrate that our WAS-VTON significantly outperforms the previous fixed-architecture try-on methods with more natural warping results and virtual try-on results.
Monitoring-based Differential Privacy Mechanism Against Query-Flooding Parameter Duplication Attack
Nov 01, 2020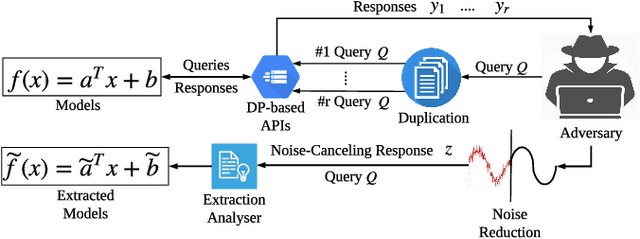

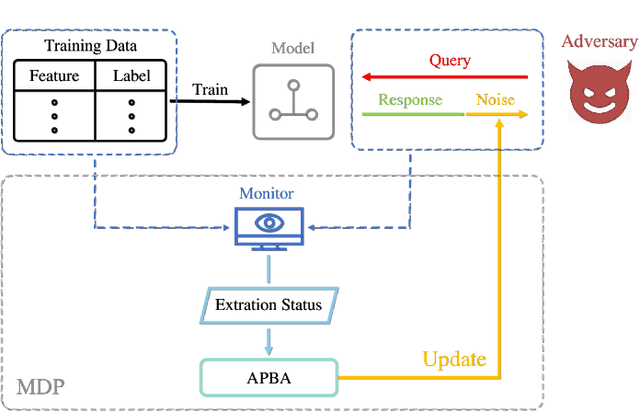
Public intelligent services enabled by machine learning algorithms are vulnerable to model extraction attacks that can steal confidential information of the learning models through public queries. Though there are some protection options such as differential privacy (DP) and monitoring, which are considered promising techniques to mitigate this attack, we still find that the vulnerability persists. In this paper, we propose an adaptive query-flooding parameter duplication (QPD) attack. The adversary can infer the model information with black-box access and no prior knowledge of any model parameters or training data via QPD. We also develop a defense strategy using DP called monitoring-based DP (MDP) against this new attack. In MDP, we first propose a novel real-time model extraction status assessment scheme called Monitor to evaluate the situation of the model. Then, we design a method to guide the differential privacy budget allocation called APBA adaptively. Finally, all DP-based defenses with MDP could dynamically adjust the amount of noise added in the model response according to the result from Monitor and effectively defends the QPD attack. Furthermore, we thoroughly evaluate and compare the QPD attack and MDP defense performance on real-world models with DP and monitoring protection.
Mitigating Query-Flooding Parameter Duplication Attack on Regression Models with High-Dimensional Gaussian Mechanism
Feb 06, 2020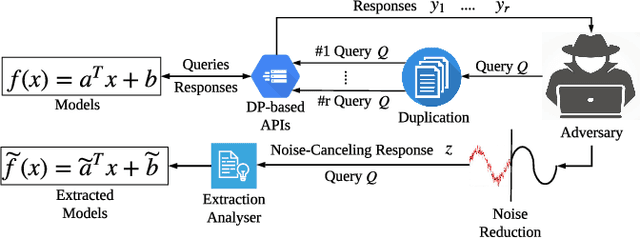
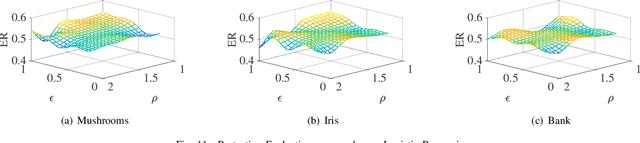
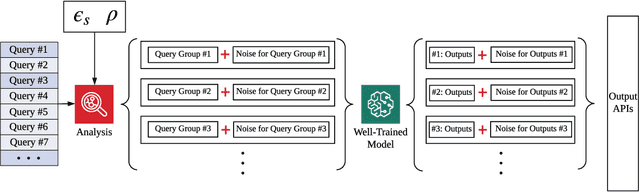
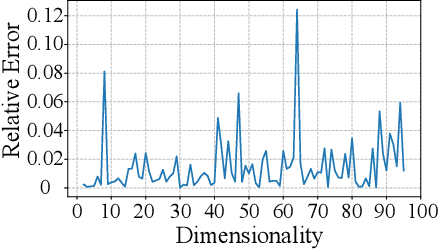
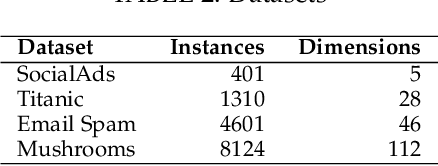
Public intelligent services enabled by machine learning algorithms are vulnerable to model extraction attacks that can steal confidential information of the learning models through public queries. Differential privacy (DP) has been considered a promising technique to mitigate this attack. However, we find that the vulnerability persists when regression models are being protected by current DP solutions. We show that the adversary can launch a query-flooding parameter duplication (QPD) attack to infer the model information by repeated queries. To defend against the QPD attack on logistic and linear regression models, we propose a novel High-Dimensional Gaussian (HDG) mechanism to prevent unauthorized information disclosure without interrupting the intended services. In contrast to prior work, the proposed HDG mechanism will dynamically generate the privacy budget and random noise for different queries and their results to enhance the obfuscation. Besides, for the first time, HDG enables an optimal privacy budget allocation that automatically determines the minimum amount of noise to be added per user-desired privacy level on each dimension. We comprehensively evaluate the performance of HDG using real-world datasets and shows that HDG effectively mitigates the QPD attack while satisfying the privacy requirements. We also prepare to open-source the relevant codes to the community for further research.