 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Scaling Laws in Deep Neural Networks via Feature Learning Dynamics
Dec 24, 2025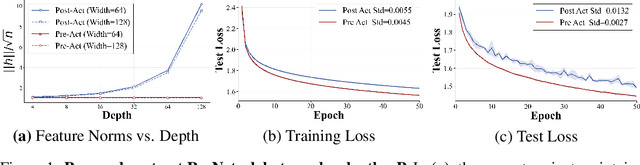


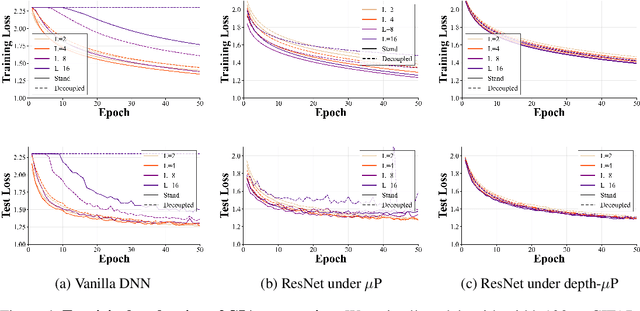
The empirical success of deep learning is often attributed to scaling laws that predict consistent gains as model, data, and compute grow; however, large models can exhibit training instability and diminishing returns, suggesting that scaling laws describe what success looks like but not when and why scaling succeeds or fails. A central obstacle is the lack of a rigorous understanding of feature learning at large depth. While muP characterizes feature-learning dynamics in the infinite-width limit and enables hyperparameter transfer across width, its depth extension (depth-muP) breaks down for residual blocks with more than one internal layer. We derive Neural Feature Dynamics (NFD) for ResNets with single-layer residual blocks, characterizing feature learning via a coupled forward-backward stochastic system in the joint infinite-width and infinite-depth limit. In this regime, NFD identifies when scaling-law trends persist and explains diminishing returns. It also reveals a vanishing mechanism induced by the 1/sqrt(depth) residual scaling under which the gradient-independence assumption (GIA), known to fail during training at finite depth, becomes provably valid again at infinite depth, yielding an analytically tractable regime for end-to-end feature learning. Motivated by this insight, we study two-layer residual blocks and show that the same mechanism causes feature-learning collapse in the first internal layer at large depth, providing a structural explanation for the empirical failure of depth-muP. Based on this diagnosis, we propose a depth-aware learning-rate correction that counteracts the collapse and empirically restores depth-wise hyperparameter transfer, yielding stronger performance in deeper ResNets.
LMCD: Language Models are Zeroshot Cognitive Diagnosis Learners
May 27, 2025Cognitive Diagnosis (CD) has become a critical task in AI-empowered education, supporting personalized learning by accurately assessing students' cognitive states. However, traditional CD models often struggle in cold-start scenarios due to the lack of student-exercise interaction data. Recent NLP-based approaches leveraging pre-trained language models (PLMs) have shown promise by utilizing textual features but fail to fully bridge the gap between semantic understanding and cognitive profiling. In this work, we propose Language Models as Zeroshot Cognitive Diagnosis Learners (LMCD), a novel framework designed to handle cold-start challenges by harnessing large language models (LLMs). LMCD operates via two primary phases: (1) Knowledge Diffusion, where LLMs generate enriched contents of exercises and knowledge concepts (KCs), establishing stronger semantic links; and (2) Semantic-Cognitive Fusion, where LLMs employ causal attention mechanisms to integrate textual information and student cognitive states, creating comprehensive profiles for both students and exercises. These representations are efficiently trained with off-the-shelf CD models. Experiments on two real-world datasets demonstrate that LMCD significantly outperforms state-of-the-art methods in both exercise-cold and domain-cold settings. The code is publicly available at https://github.com/TAL-auroraX/LMCD
ResoFilter: Fine-grained Synthetic Data Filtering for Large Language Models through Data-Parameter Resonance Analysis
Dec 20, 2024



Large language models (LLMs) have shown remarkable effectiveness across various domains, with data augmentation methods utilizing GPT for synthetic data generation becoming prevalent. However, the quality and utility of augmented data remain questionable, and current methods lack clear metrics for evaluating data characteristics. To address these challenges, we propose ResoFilter, a novel method that integrates models, data, and tasks to refine datasets. ResoFilter leverages the fine-tuning process to obtain Data-Parameter features for data selection, offering improved interpretability by representing data characteristics through model weights. Our experiments demonstrate that ResoFilter achieves comparable results to full-scale fine-tuning using only half the data in mathematical tasks and exhibits strong generalization across different models and domains. This method provides valuable insights for constructing synthetic datasets and evaluating high-quality data, offering a promising solution for enhancing data augmentation techniques and improving training dataset quality for LLMs. For reproducibility, we will release our code and data upon acceptance.
ResoFilter: Rine-grained Synthetic Data Filtering for Large Language Models through Data-Parameter Resonance Analysis
Dec 19, 2024Large language models (LLMs) have shown remarkable effectiveness across various domains, with data augmentation methods utilizing GPT for synthetic data generation becoming prevalent. However, the quality and utility of augmented data remain questionable, and current methods lack clear metrics for evaluating data characteristics. To address these challenges, we propose ResoFilter, a novel method that integrates models, data, and tasks to refine datasets. ResoFilter leverages the fine-tuning process to obtain Data-Parameter features for data selection, offering improved interpretability by representing data characteristics through model weights. Our experiments demonstrate that ResoFilter achieves comparable results to full-scale fine-tuning using only half the data in mathematical tasks and exhibits strong generalization across different models and domains. This method provides valuable insights for constructing synthetic datasets and evaluating high-quality data, offering a promising solution for enhancing data augmentation techniques and improving training dataset quality for LLMs. For reproducibility, we will release our code and data upon acceptance.
Scalable Model Editing via Customized Expert Networks
Apr 03, 2024Addressing the issue of hallucinations and outdated knowledge in large language models is critical for their reliable application. Model Editing presents a promising avenue for mitigating these challenges in a cost-effective manner. However, existing methods often suffer from unsatisfactory generalization and unintended effects on unrelated samples. To overcome these limitations, we introduce a novel approach: Scalable Model Editing via Customized Expert Networks (SCEN), which is a two-stage continuous training paradigm. Specifically, in the first stage, we train lightweight expert networks individually for each piece of knowledge that needs to be updated. Subsequently, we train a corresponding neuron for each expert to control the activation state of that expert. Our experiments on two different sizes of open-source large language models, the Llama2 7B and 13B, achieve state-of-the-art results compared to existing mainstream Model Editing methods. Our code is available at https: //github.com/TAL-auroraX/SCEN