 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale graph representation learning with very deep GNNs and self-supervision
Jul 20, 2021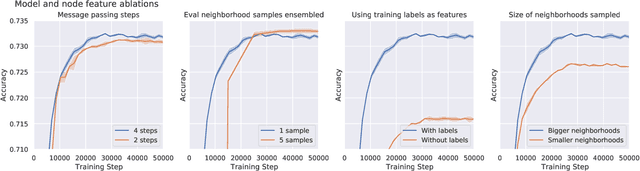
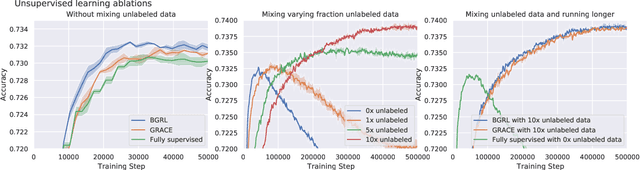
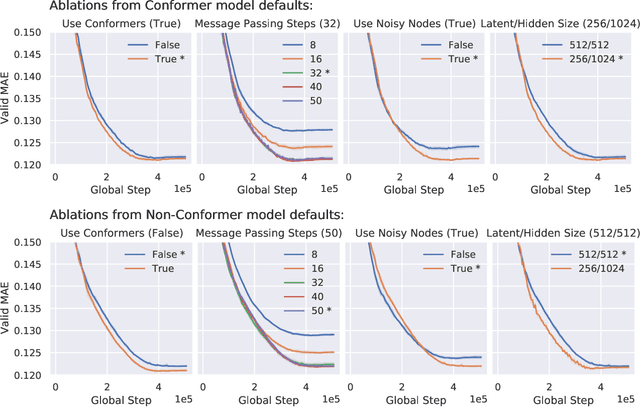
Effectively and efficiently deploying graph neural networks (GNNs) at scale remains one of the most challenging aspects of graph representation learning. Many powerful solutions have only ever been validated on comparatively small datasets, often with counter-intuitive outcomes -- a barrier which has been broken by the Open Graph Benchmark Large-Scale Challenge (OGB-LSC). We entered the OGB-LSC with two large-scale GNNs: a deep transductive node classifier powered by bootstrapping, and a very deep (up to 50-layer) inductive graph regressor regularised by denoising objectives. Our models achieved an award-level (top-3) performance on both the MAG240M and PCQM4M benchmarks. In doing so, we demonstrate evidence of scalable self-supervised graph representation learning, and utility of very deep GNNs -- both very important open issues. Our code is publicly available at: https://github.com/deepmind/deepmind-research/tree/master/ogb_lsc.
Data Efficient Training for Reinforcement Learning with Adaptive Behavior Policy Sharing
Feb 12, 2020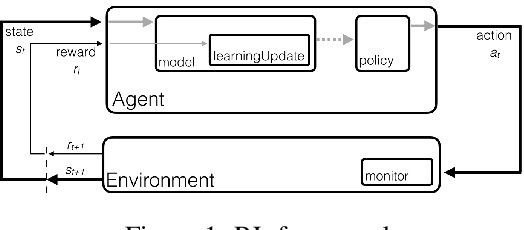
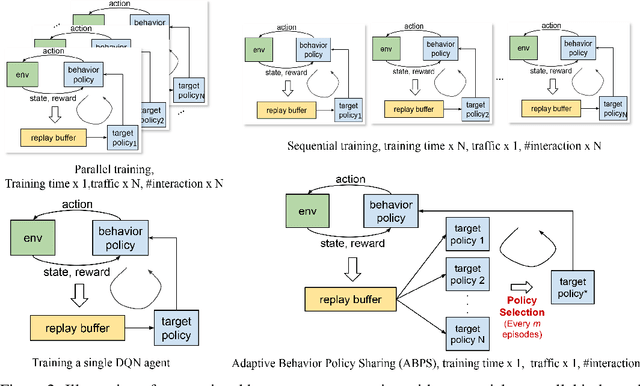
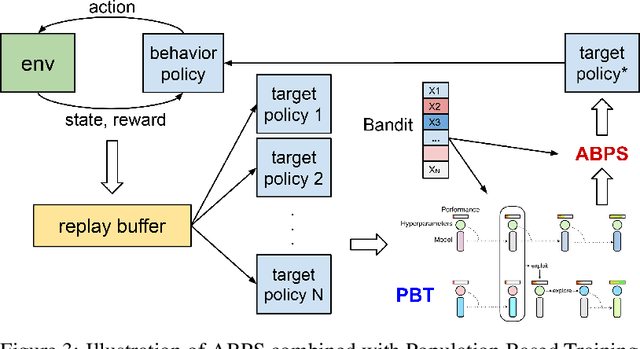
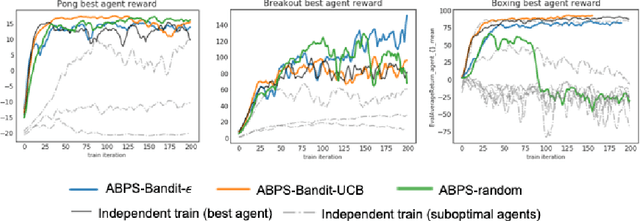
Deep Reinforcement Learning (RL) is proven powerful for decision making in simulated environments. However, training deep RL model is challenging in real world applications such as production-scale health-care or recommender systems because of the expensiveness of interaction and limitation of budget at deployment. One aspect of the data inefficiency comes from the expensive hyper-parameter tuning when optimizing deep neural networks. We propose Adaptive Behavior Policy Sharing (ABPS), a data-efficient training algorithm that allows sharing of experience collected by behavior policy that is adaptively selected from a pool of agents trained with an ensemble of hyper-parameters. We further extend ABPS to evolve hyper-parameters during training by hybridizing ABPS with an adapted version of Population Based Training (ABPS-PBT). We conduct experiments with multiple Atari games with up to 16 hyper-parameter/architecture setups. ABPS achieves superior overall performance, reduced variance on top 25% agents, and equivalent performance on the best agent compared to conventional hyper-parameter tuning with independent training, even though ABPS only requires the same number of environmental interactions as training a single agent. We also show that ABPS-PBT further improves the convergence speed and reduces the variance.