 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to transfer algorithmic reasoning knowledge to learn new algorithms?
Oct 26, 2021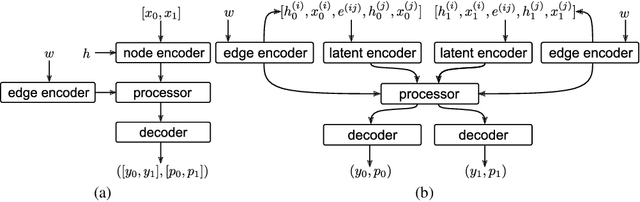

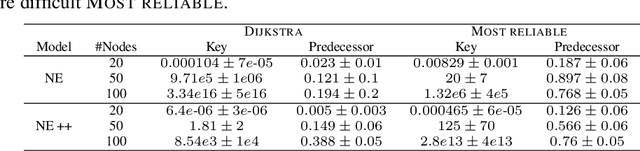
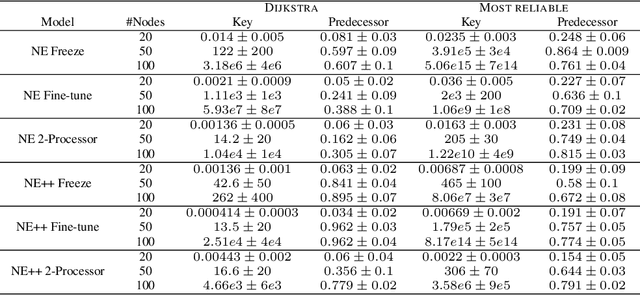
Learning to execute algorithms is a fundamental problem that has been widely studied. Prior work~\cite{veli19neural} has shown that to enable systematic generalisation on graph algorithms it is critical to have access to the intermediate steps of the program/algorithm. In many reasoning tasks, where algorithmic-style reasoning is important, we only have access to the input and output examples. Thus, inspired by the success of pre-training on similar tasks or data in Natural Language Processing (NLP) and Computer Vision, we set out to study how we can transfer algorithmic reasoning knowledge. Specifically, we investigate how we can use algorithms for which we have access to the execution trace to learn to solve similar tasks for which we do not. We investigate two major classes of graph algorithms, parallel algorithms such as breadth-first search and Bellman-Ford and sequential greedy algorithms such as Prim and Dijkstra. Due to the fundamental differences between algorithmic reasoning knowledge and feature extractors such as used in Computer Vision or NLP, we hypothesise that standard transfer techniques will not be sufficient to achieve systematic generalisation. To investigate this empirically we create a dataset including 9 algorithms and 3 different graph types. We validate this empirically and show how instead multi-task learning can be used to achieve the transfer of algorithmic reasoning knowledge.
Few-shot Relation Extraction via Bayesian Meta-learning on Relation Graphs
Jul 05, 2020


This paper studies few-shot relation extraction, which aims at predicting the relation for a pair of entities in a sentence by training with a few labeled examples in each relation. To more effectively generalize to new relations, in this paper we study the relationships between different relations and propose to leverage a global relation graph. We propose a novel Bayesian meta-learning approach to effectively learn the posterior distribution of the prototype vectors of relations, where the initial prior of the prototype vectors is parameterized with a graph neural network on the global relation graph. Moreover, to effectively optimize the posterior distribution of the prototype vectors, we propose to use the stochastic gradient Langevin dynamics, which is related to the MAML algorithm but is able to handle the uncertainty of the prototype vectors. The whole framework can be effectively and efficiently optimized in an end-to-end fashion. Experiments on two benchmark datasets prove the effectiveness of our proposed approach against competitive baselines in both the few-shot and zero-shot settings.
Continuous Graph Neural Networks
Dec 02, 2019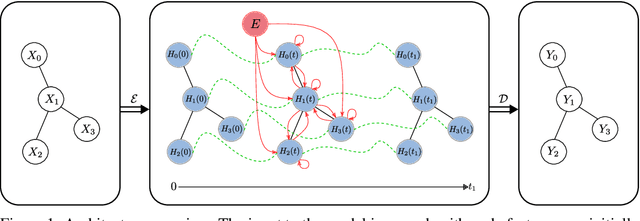



This paper builds the connection between graph neural networks and traditional dynamical systems. Existing graph neural networks essentially define a discrete dynamic on node representations with multiple graph convolution layers. We propose continuous graph neural networks (CGNN), which generalise existing graph neural networks into the continuous-time dynamic setting. The key idea is how to characterise the continuous dynamics of node representations, i.e. the derivatives of node representations w.r.t. time. Inspired by existing diffusion-based methods on graphs (e.g. PageRank and epidemic models on social networks), we define the derivatives as a combination of the current node representations, the representations of neighbors, and the initial values of the nodes. We propose and analyse different possible dynamics on graphs---including each dimension of node representations (a.k.a. the feature channel) change independently or interact with each other---both with theoretical justification. The proposed continuous graph neural networks are robust to over-smoothing and hence capture the long-range dependencies between nodes. Experimental results on the task of node classification prove the effectiveness of our proposed approach over competitive baselines.