 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering an Efficient Object Tracker for Non-Linear Motion
Jun 30, 2024The goal of multi-object tracking is to detect and track all objects in a scene while maintaining unique identifiers for each, by associating their bounding boxes across video frames. This association relies on matching motion and appearance patterns of detected objects. This task is especially hard in case of scenarios involving dynamic and non-linear motion patterns. In this paper, we introduce DeepMoveSORT, a novel, carefully engineered multi-object tracker designed specifically for such scenarios. In addition to standard methods of appearance-based association, we improve motion-based association by employing deep learnable filters (instead of the most commonly used Kalman filter) and a rich set of newly proposed heuristics. Our improvements to motion-based association methods are severalfold. First, we propose a new transformer-based filter architecture, TransFilter, which uses an object's motion history for both motion prediction and noise filtering. We further enhance the filter's performance by careful handling of its motion history and accounting for camera motion. Second, we propose a set of heuristics that exploit cues from the position, shape, and confidence of detected bounding boxes to improve association performance. Our experimental evaluation demonstrates that DeepMoveSORT outperforms existing trackers in scenarios featuring non-linear motion, surpassing state-of-the-art results on three such datasets. We also perform a thorough ablation study to evaluate the contributions of different tracker components which we proposed. Based on our study, we conclude that using a learnable filter instead of the Kalman filter, along with appearance-based association is key to achieving strong general tracking performance.
Beyond Kalman Filters: Deep Learning-Based Filters for Improved Object Tracking
Feb 15, 2024Traditional tracking-by-detection systems typically employ Kalman filters (KF) for state estimation. However, the KF requires domain-specific design choices and it is ill-suited to handling non-linear motion patterns. To address these limitations, we propose two innovative data-driven filtering methods. Our first method employs a Bayesian filter with a trainable motion model to predict an object's future location and combines its predictions with observations gained from an object detector to enhance bounding box prediction accuracy. Moreover, it dispenses with most domain-specific design choices characteristic of the KF. The second method, an end-to-end trainable filter, goes a step further by learning to correct detector errors, further minimizing the need for domain expertise. Additionally, we introduce a range of motion model architectures based on Recurrent Neural Networks, Neural Ordinary Differential Equations, and Conditional Neural Processes, that are combined with the proposed filtering methods. Our extensive evaluation across multiple datasets demonstrates that our proposed filters outperform the traditional KF in object tracking, especially in the case of non-linear motion patterns -- the use case our filters are best suited to. We also conduct noise robustness analysis of our filters with convincing positive results. We further propose a new cost function for associating observations with tracks. Our tracker, which incorporates this new association cost with our proposed filters, outperforms the conventional SORT method and other motion-based trackers in multi-object tracking according to multiple metrics on motion-rich DanceTrack and SportsMOT datasets.
Intrinsically motivated option learning: a comparative study of recent methods
Jun 13, 2022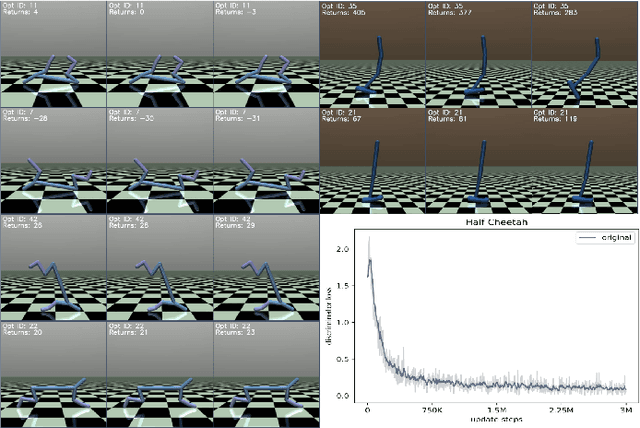

Options represent a framework for reasoning across multiple time scales in reinforcement learning (RL). With the recent active interest in the unsupervised learning paradigm in the RL research community, the option framework was adapted to utilize the concept of empowerment, which corresponds to the amount of influence the agent has on the environment and its ability to perceive this influence, and which can be optimized without any supervision provided by the environment's reward structure. Many recent papers modify this concept in various ways achieving commendable results. Through these various modifications, however, the initial context of empowerment is often lost. In this work we offer a comparative study of such papers through the lens of the original empowerment principle.
Neural Algorithmic Reasoners are Implicit Planners
Oct 11, 2021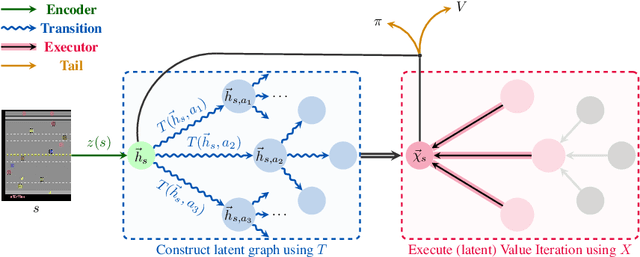
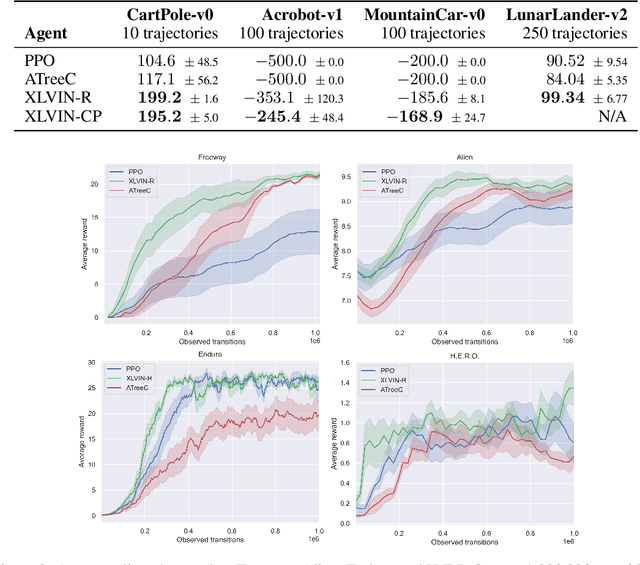

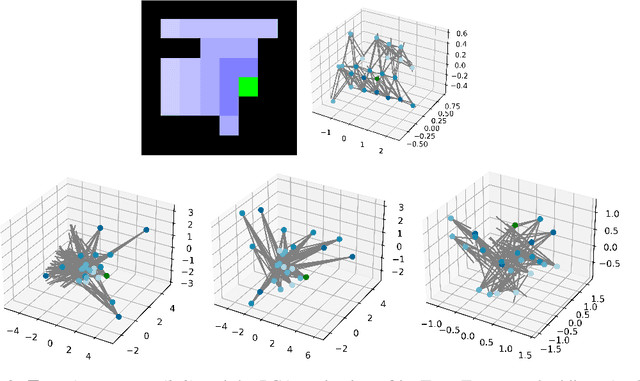
Implicit planning has emerged as an elegant technique for combining learned models of the world with end-to-end model-free reinforcement learning. We study the class of implicit planners inspired by value iteration, an algorithm that is guaranteed to yield perfect policies in fully-specified tabular environments. We find that prior approaches either assume that the environment is provided in such a tabular form -- which is highly restrictive -- or infer "local neighbourhoods" of states to run value iteration over -- for which we discover an algorithmic bottleneck effect. This effect is caused by explicitly running the planning algorithm based on scalar predictions in every state, which can be harmful to data efficiency if such scalars are improperly predicted. We propose eXecuted Latent Value Iteration Networks (XLVINs), which alleviate the above limitations. Our method performs all planning computations in a high-dimensional latent space, breaking the algorithmic bottleneck. It maintains alignment with value iteration by carefully leveraging neural graph-algorithmic reasoning and contrastive self-supervised learning. Across eight low-data settings -- including classical control, navigation and Atari -- XLVINs provide significant improvements to data efficiency against value iteration-based implicit planners, as well as relevant model-free baselines. Lastly, we empirically verify that XLVINs can closely align with value iteration.
FAIR: Fair Adversarial Instance Re-weighting
Nov 15, 2020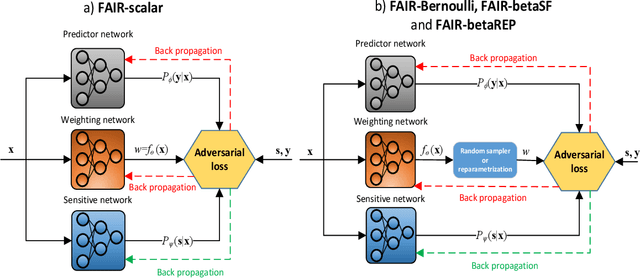
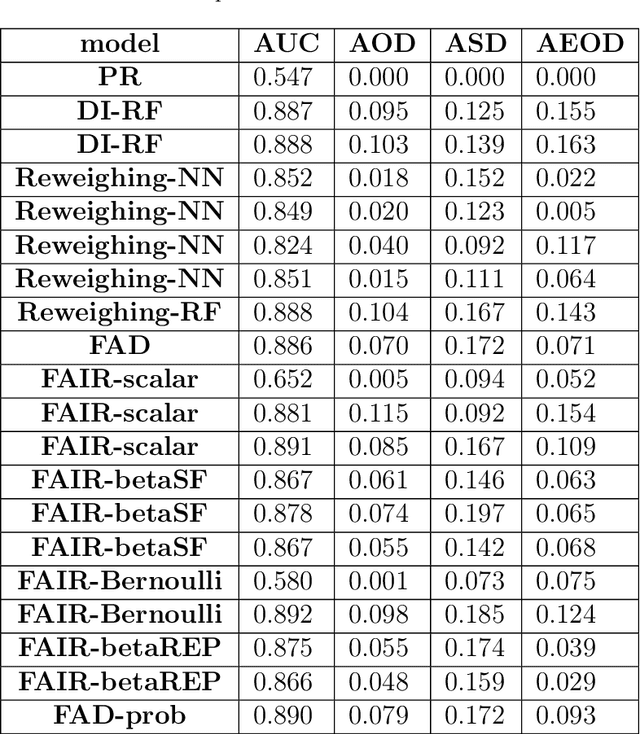
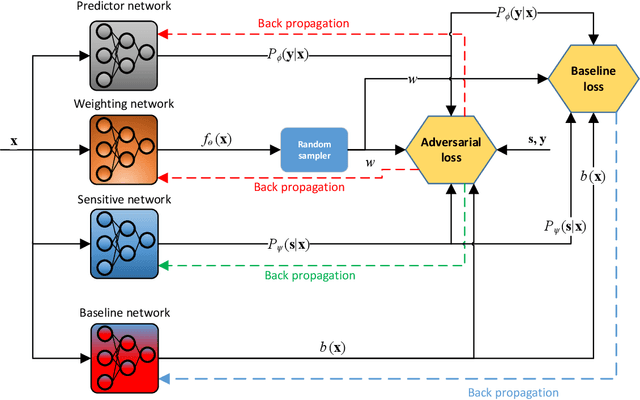
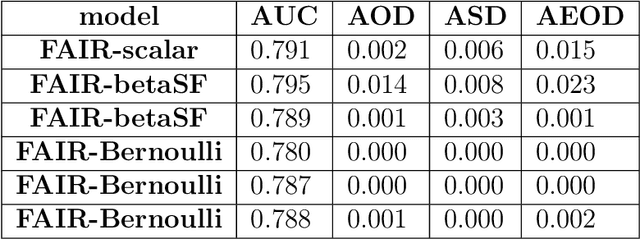
With growing awareness of societal impact of artificial intelligence, fairness has become an important aspect of machine learning algorithms. The issue is that human biases towards certain groups of population, defined by sensitive features like race and gender, are introduced to the training data through data collection and labeling. Two important directions of fairness ensuring research have focused on (i) instance weighting in order to decrease the impact of more biased instances and (ii) adversarial training in order to construct data representations informative of the target variable, but uninformative of the sensitive attributes. In this paper we propose a Fair Adversarial Instance Re-weighting (FAIR) method, which uses adversarial training to learn instance weighting function that ensures fair predictions. Merging the two paradigms, it inherits desirable properties from both -- interpretability of reweighting and end-to-end trainability of adversarial training. We propose four different variants of the method and, among other things, demonstrate how the method can be cast in a fully probabilistic framework. Additionally, theoretical analysis of FAIR models' properties have been studied extensively. We compare FAIR models to 7 other related and state-of-the-art models and demonstrate that FAIR is able to achieve a better trade-off between accuracy and unfairness. To the best of our knowledge, this is the first model that merges reweighting and adversarial approaches by means of a weighting function that can provide interpretable information about fairness of individual instances.
XLVIN: eXecuted Latent Value Iteration Nets
Oct 25, 2020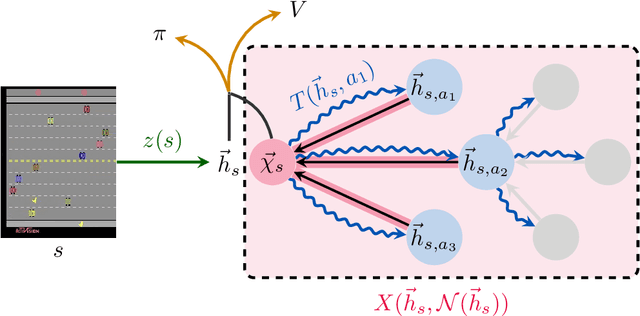

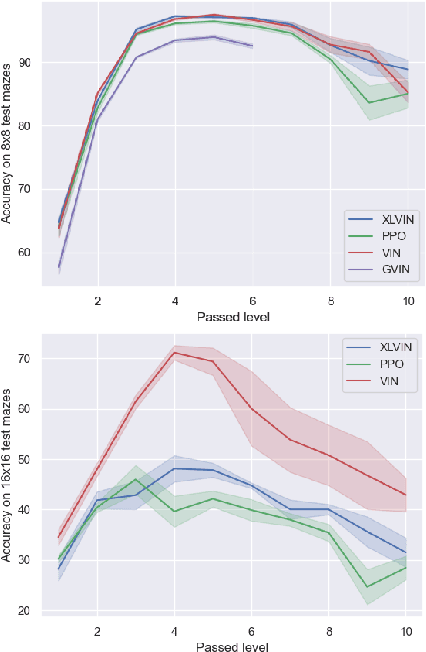
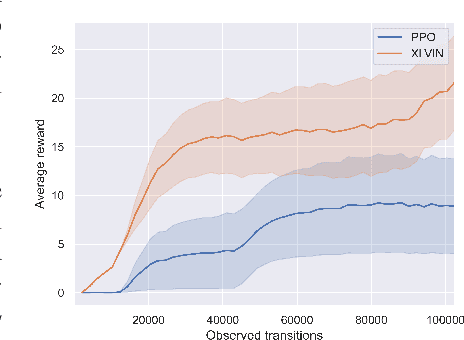
Value Iteration Networks (VINs) have emerged as a popular method to incorporate planning algorithms within deep reinforcement learning, enabling performance improvements on tasks requiring long-range reasoning and understanding of environment dynamics. This came with several limitations, however: the model is not incentivised in any way to perform meaningful planning computations, the underlying state space is assumed to be discrete, and the Markov decision process (MDP) is assumed fixed and known. We propose eXecuted Latent Value Iteration Networks (XLVINs), which combine recent developments across contrastive self-supervised learning, graph representation learning and neural algorithmic reasoning to alleviate all of the above limitations, successfully deploying VIN-style models on generic environments. XLVINs match the performance of VIN-like models when the underlying MDP is discrete, fixed and known, and provides significant improvements to model-free baselines across three general MDP setups.
Hierachial Protein Function Prediction with Tails-GNNs
Jul 24, 2020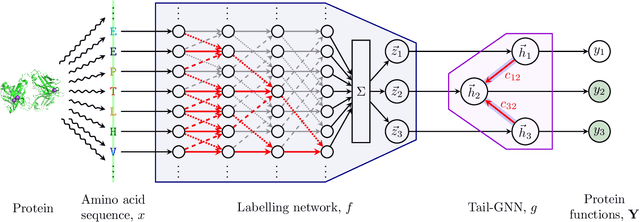
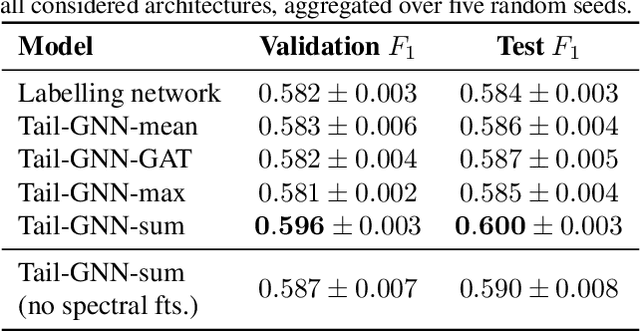

Protein function prediction may be framed as predicting subgraphs (with certain closure properties) of a directed acyclic graph describing the hierarchy of protein functions. Graph neural networks (GNNs), with their built-in inductive bias for relational data, are hence naturally suited for this task. However, in contrast with most GNN applications, the graph is not related to the input, but to the label space. Accordingly, we propose Tail-GNNs, neural networks which naturally compose with the output space of any neural network for multi-task prediction, to provide relationally-reinforced labels. For protein function prediction, we combine a Tail-GNN with a dilated convolutional network which learns representations of the protein sequence, making significant improvement in F_1 score and demonstrating the ability of Tail-GNNs to learn useful representations of labels and exploit them in real-world problem solving.
Gaussian Conditional Random Fields for Classification
Jan 31, 2019
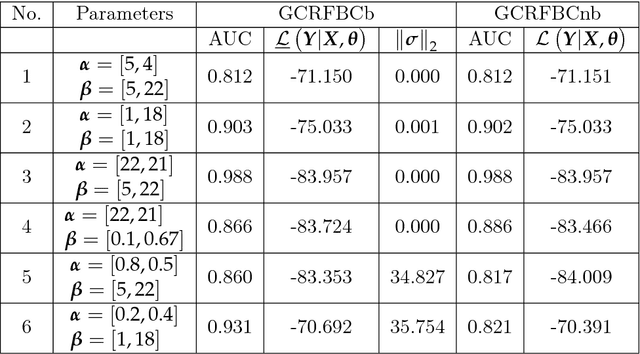
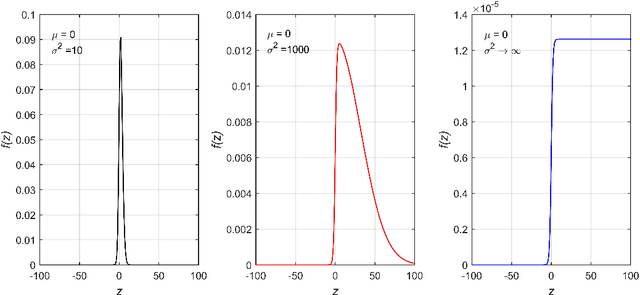
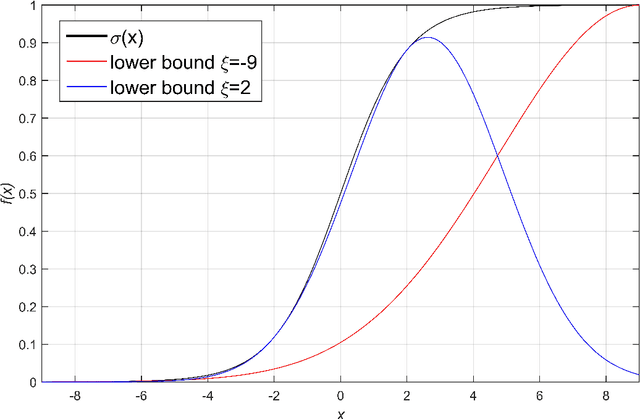
Gaussian conditional random fields (GCRF) are a well-known used structured model for continuous outputs that uses multiple unstructured predictors to form its features and at the same time exploits dependence structure among outputs, which is provided by a similarity measure. In this paper, a Gaussian conditional random fields model for structured binary classification (GCRFBC) is proposed. The model is applicable to classification problems with undirected graphs, intractable for standard classification CRFs. The model representation of GCRFBC is extended by latent variables which yield some appealing properties. Thanks to the GCRF latent structure, the model becomes tractable, efficient and open to improvements previously applied to GCRF regression models. In addition, the model allows for reduction of noise, that might appear if structures were defined directly between discrete outputs. Additionally, two different forms of the algorithm are presented: GCRFBCb (GCRGBC - Bayesian) and GCRFBCnb (GCRFBC - non Bayesian). The extended method of local variational approximation of sigmoid function is used for solving empirical Bayes in Bayesian GCRFBCb variant, whereas MAP value of latent variables is the basis for learning and inference in the GCRFBCnb variant. The inference in GCRFBCb is solved by Newton-Cotes formulas for one-dimensional integration. Both models are evaluated on synthetic data and real-world data. It was shown that both models achieve better prediction performance than unstructured predictors. Furthermore, computational and memory complexity is evaluated. Advantages and disadvantages of the proposed GCRFBCb and GCRFBCnb are discussed in detail.
Short Portfolio Training for CSP Solving
May 08, 2015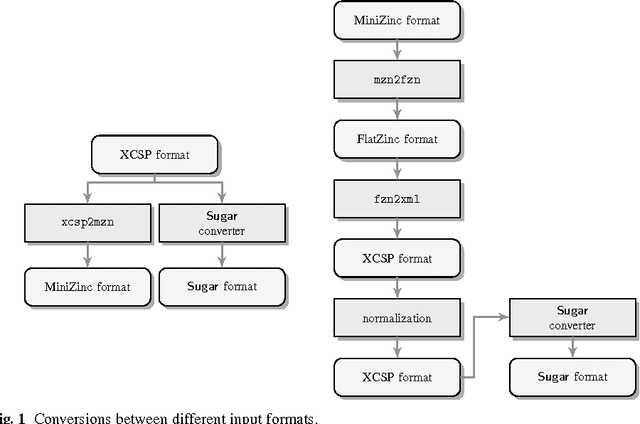



Many different approaches for solving Constraint Satisfaction Problems (CSPs) and related Constraint Optimization Problems (COPs) exist. However, there is no single solver (nor approach) that performs well on all classes of problems and many portfolio approaches for selecting a suitable solver based on simple syntactic features of the input CSP instance have been developed. In this paper we first present a simple portfolio method for CSP based on k-nearest neighbors method. Then, we propose a new way of using portfolio systems --- training them shortly in the exploitation time, specifically for the set of instances to be solved and using them on that set. Thorough evaluation has been performed and has shown that the approach yields good results. We evaluated several machine learning techniques for our portfolio. Due to its simplicity and efficiency, the selected k-nearest neighbors method is especially suited for our short training approach and it also yields the best results among the tested methods. We also confirm that our approach yields good results on SAT domain.