 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering an Efficient Object Tracker for Non-Linear Motion
Jun 30, 2024The goal of multi-object tracking is to detect and track all objects in a scene while maintaining unique identifiers for each, by associating their bounding boxes across video frames. This association relies on matching motion and appearance patterns of detected objects. This task is especially hard in case of scenarios involving dynamic and non-linear motion patterns. In this paper, we introduce DeepMoveSORT, a novel, carefully engineered multi-object tracker designed specifically for such scenarios. In addition to standard methods of appearance-based association, we improve motion-based association by employing deep learnable filters (instead of the most commonly used Kalman filter) and a rich set of newly proposed heuristics. Our improvements to motion-based association methods are severalfold. First, we propose a new transformer-based filter architecture, TransFilter, which uses an object's motion history for both motion prediction and noise filtering. We further enhance the filter's performance by careful handling of its motion history and accounting for camera motion. Second, we propose a set of heuristics that exploit cues from the position, shape, and confidence of detected bounding boxes to improve association performance. Our experimental evaluation demonstrates that DeepMoveSORT outperforms existing trackers in scenarios featuring non-linear motion, surpassing state-of-the-art results on three such datasets. We also perform a thorough ablation study to evaluate the contributions of different tracker components which we proposed. Based on our study, we conclude that using a learnable filter instead of the Kalman filter, along with appearance-based association is key to achieving strong general tracking performance.
Synthetic Dataset Creation and Fine-Tuning of Transformer Models for Question Answering in Serbian
Apr 12, 2024In this paper, we focus on generating a synthetic question answering (QA) dataset using an adapted Translate-Align-Retrieve method. Using this method, we created the largest Serbian QA dataset of more than 87K samples, which we name SQuAD-sr. To acknowledge the script duality in Serbian, we generated both Cyrillic and Latin versions of the dataset. We investigate the dataset quality and use it to fine-tune several pre-trained QA models. Best results were obtained by fine-tuning the BERTi\'c model on our Latin SQuAD-sr dataset, achieving 73.91% Exact Match and 82.97% F1 score on the benchmark XQuAD dataset, which we translated into Serbian for the purpose of evaluation. The results show that our model exceeds zero-shot baselines, but fails to go beyond human performance. We note the advantage of using a monolingual pre-trained model over multilingual, as well as the performance increase gained by using Latin over Cyrillic. By performing additional analysis, we show that questions about numeric values or dates are more likely to be answered correctly than other types of questions. Finally, we conclude that SQuAD-sr is of sufficient quality for fine-tuning a Serbian QA model, in the absence of a manually crafted and annotated dataset.
Beyond Kalman Filters: Deep Learning-Based Filters for Improved Object Tracking
Feb 15, 2024Traditional tracking-by-detection systems typically employ Kalman filters (KF) for state estimation. However, the KF requires domain-specific design choices and it is ill-suited to handling non-linear motion patterns. To address these limitations, we propose two innovative data-driven filtering methods. Our first method employs a Bayesian filter with a trainable motion model to predict an object's future location and combines its predictions with observations gained from an object detector to enhance bounding box prediction accuracy. Moreover, it dispenses with most domain-specific design choices characteristic of the KF. The second method, an end-to-end trainable filter, goes a step further by learning to correct detector errors, further minimizing the need for domain expertise. Additionally, we introduce a range of motion model architectures based on Recurrent Neural Networks, Neural Ordinary Differential Equations, and Conditional Neural Processes, that are combined with the proposed filtering methods. Our extensive evaluation across multiple datasets demonstrates that our proposed filters outperform the traditional KF in object tracking, especially in the case of non-linear motion patterns -- the use case our filters are best suited to. We also conduct noise robustness analysis of our filters with convincing positive results. We further propose a new cost function for associating observations with tracks. Our tracker, which incorporates this new association cost with our proposed filters, outperforms the conventional SORT method and other motion-based trackers in multi-object tracking according to multiple metrics on motion-rich DanceTrack and SportsMOT datasets.
Object Location Prediction in Real-time using LSTM Neural Network and Polynomial Regression
Nov 23, 2023This paper details the design and implementation of a system for predicting and interpolating object location coordinates. Our solution is based on processing inertial measurements and global positioning system data through a Long Short-Term Memory (LSTM) neural network and polynomial regression. LSTM is a type of recurrent neural network (RNN) particularly suited for processing data sequences and avoiding the long-term dependency problem. We employed data from real-world vehicles and the global positioning system (GPS) sensors. A critical pre-processing step was developed to address varying sensor frequencies and inconsistent GPS time steps and dropouts. The LSTM-based system's performance was compared with the Kalman Filter. The system was tuned to work in real-time with low latency and high precision. We tested our system on roads under various driving conditions, including acceleration, turns, deceleration, and straight paths. We tested our proposed solution's accuracy and inference time and showed that it could perform in real-time. Our LSTM-based system yielded an average error of 0.11 meters with an inference time of 2 ms. This represents a 76\% reduction in error compared to the traditional Kalman filter method, which has an average error of 0.46 meters with a similar inference time to the LSTM-based system.
Intrinsically motivated option learning: a comparative study of recent methods
Jun 13, 2022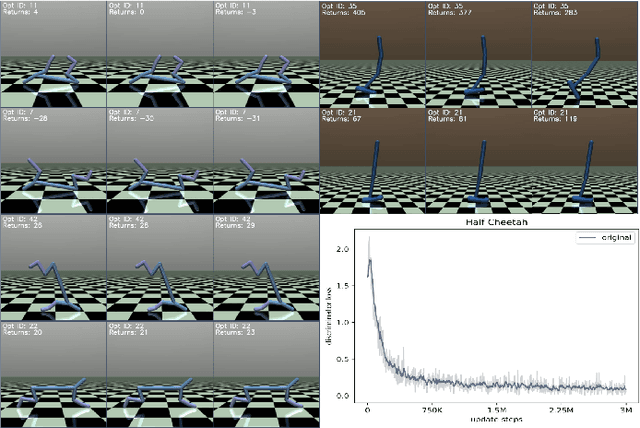

Options represent a framework for reasoning across multiple time scales in reinforcement learning (RL). With the recent active interest in the unsupervised learning paradigm in the RL research community, the option framework was adapted to utilize the concept of empowerment, which corresponds to the amount of influence the agent has on the environment and its ability to perceive this influence, and which can be optimized without any supervision provided by the environment's reward structure. Many recent papers modify this concept in various ways achieving commendable results. Through these various modifications, however, the initial context of empowerment is often lost. In this work we offer a comparative study of such papers through the lens of the original empowerment principle.