 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid training of deep neural networks without skip connections or normalization layers using Deep Kernel Shaping
Oct 05, 2021Using an extended and formalized version of the Q/C map analysis of Poole et al. (2016), along with Neural Tangent Kernel theory, we identify the main pathologies present in deep networks that prevent them from training fast and generalizing to unseen data, and show how these can be avoided by carefully controlling the "shape" of the network's initialization-time kernel function. We then develop a method called Deep Kernel Shaping (DKS), which accomplishes this using a combination of precise parameter initialization, activation function transformations, and small architectural tweaks, all of which preserve the model class. In our experiments we show that DKS enables SGD training of residual networks without normalization layers on Imagenet and CIFAR-10 classification tasks at speeds comparable to standard ResNetV2 and Wide-ResNet models, with only a small decrease in generalization performance. And when using K-FAC as the optimizer, we achieve similar results for networks without skip connections. Our results apply for a large variety of activation functions, including those which traditionally perform very badly, such as the logistic sigmoid. In addition to DKS, we contribute a detailed analysis of skip connections, normalization layers, special activation functions like RELU and SELU, and various initialization schemes, explaining their effectiveness as alternative (and ultimately incomplete) ways of "shaping" the network's initialization-time kernel.
Unsupervised Doodling and Painting with Improved SPIRAL
Oct 02, 2019
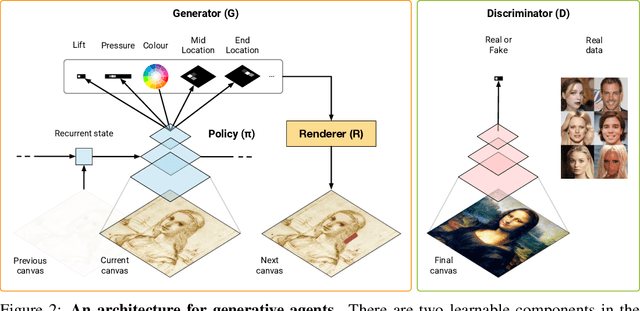


We investigate using reinforcement learning agents as generative models of images (extending arXiv:1804.01118). A generative agent controls a simulated painting environment, and is trained with rewards provided by a discriminator network simultaneously trained to assess the realism of the agent's samples, either unconditional or reconstructions. Compared to prior work, we make a number of improvements to the architectures of the agents and discriminators that lead to intriguing and at times surprising results. We find that when sufficiently constrained, generative agents can learn to produce images with a degree of visual abstraction, despite having only ever seen real photographs (no human brush strokes). And given enough time with the painting environment, they can produce images with considerable realism. These results show that, under the right circumstances, some aspects of human drawing can emerge from simulated embodiment, without the need for external supervision, imitation or social cues. Finally, we note the framework's potential for use in creative applications.