 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Advantage Credit Assignment for Cooperative Multi-Agent Reinforcement Learning
Aug 09, 2025Cooperative multi-agent reinforcement learning (MARL) aims to coordinate multiple agents to achieve a common goal. A key challenge in MARL is credit assignment, which involves assessing each agent's contribution to the shared reward. Given the diversity of tasks, agents may perform different types of coordination, with rewards attributed to diverse and often overlapping agent subsets. In this work, we formalize the credit assignment level as the number of agents cooperating to obtain a reward, and address scenarios with multiple coexisting levels. We introduce a multi-level advantage formulation that performs explicit counterfactual reasoning to infer credits across distinct levels. Our method, Multi-level Advantage Credit Assignment (MACA), captures agent contributions at multiple levels by integrating advantage functions that reason about individual, joint, and correlated actions. Utilizing an attention-based framework, MACA identifies correlated agent relationships and constructs multi-level advantages to guide policy learning. Comprehensive experiments on challenging Starcraft v1\&v2 tasks demonstrate MACA's superior performance, underscoring its efficacy in complex credit assignment scenarios.
Boosting LLM Reasoning via Spontaneous Self-Correction
Jun 07, 2025



While large language models (LLMs) have demonstrated remarkable success on a broad range of tasks, math reasoning remains a challenging one. One of the approaches for improving math reasoning is self-correction, which designs self-improving loops to let the model correct its own mistakes. However, existing self-correction approaches treat corrections as standalone post-generation refinements, relying on extra prompt and system designs to elicit self-corrections, instead of performing real-time, spontaneous self-corrections in a single pass. To address this, we propose SPOC, a spontaneous self-correction approach that enables LLMs to generate interleaved solutions and verifications in a single inference pass, with generation dynamically terminated based on verification outcomes, thereby effectively scaling inference time compute. SPOC considers a multi-agent perspective by assigning dual roles -- solution proposer and verifier -- to the same model. We adopt a simple yet effective approach to generate synthetic data for fine-tuning, enabling the model to develop capabilities for self-verification and multi-agent collaboration. We further improve its solution proposal and verification accuracy through online reinforcement learning. Experiments on mathematical reasoning benchmarks show that SPOC significantly improves performance. Notably, SPOC boosts the accuracy of Llama-3.1-8B and 70B Instruct models, achieving gains of 8.8% and 11.6% on MATH500, 10.0% and 20.0% on AMC23, and 3.3% and 6.7% on AIME24, respectively.
Towards Few-shot Coordination: Revisiting Ad-hoc Teamplay Challenge In the Game of Hanabi
Aug 20, 2023



Cooperative Multi-agent Reinforcement Learning (MARL) algorithms with Zero-Shot Coordination (ZSC) have gained significant attention in recent years. ZSC refers to the ability of agents to coordinate zero-shot (without additional interaction experience) with independently trained agents. While ZSC is crucial for cooperative MARL agents, it might not be possible for complex tasks and changing environments. Agents also need to adapt and improve their performance with minimal interaction with other agents. In this work, we show empirically that state-of-the-art ZSC algorithms have poor performance when paired with agents trained with different learning methods, and they require millions of interaction samples to adapt to these new partners. To investigate this issue, we formally defined a framework based on a popular cooperative multi-agent game called Hanabi to evaluate the adaptability of MARL methods. In particular, we created a diverse set of pre-trained agents and defined a new metric called adaptation regret that measures the agent's ability to efficiently adapt and improve its coordination performance when paired with some held-out pool of partners on top of its ZSC performance. After evaluating several SOTA algorithms using our framework, our experiments reveal that naive Independent Q-Learning (IQL) agents in most cases adapt as quickly as the SOTA ZSC algorithm Off-Belief Learning (OBL). This finding raises an interesting research question: How to design MARL algorithms with high ZSC performance and capability of fast adaptation to unseen partners. As a first step, we studied the role of different hyper-parameters and design choices on the adaptability of current MARL algorithms. Our experiments show that two categories of hyper-parameters controlling the training data diversity and optimization process have a significant impact on the adaptability of Hanabi agents.
Conditionally Optimistic Exploration for Cooperative Deep Multi-Agent Reinforcement Learning
Mar 16, 2023



Efficient exploration is critical in cooperative deep Multi-Agent Reinforcement Learning (MARL). In this paper, we propose an exploration method that efficiently encourages cooperative exploration based on the idea of the theoretically justified tree search algorithm UCT (Upper Confidence bounds applied to Trees). The high-level intuition is that to perform optimism-based exploration, agents would achieve cooperative strategies if each agent's optimism estimate captures a structured dependency relationship with other agents. At each node (i.e., action) of the search tree, UCT performs optimism-based exploration using a bonus derived by conditioning on the visitation count of its parent node. We provide a perspective to view MARL as tree search iterations and develop a method called Conditionally Optimistic Exploration (COE). We assume agents take actions following a sequential order, and consider nodes at the same depth of the search tree as actions of one individual agent. COE computes each agent's state-action value estimate with an optimistic bonus derived from the visitation count of the state and joint actions taken by agents up to the current agent. COE is adaptable to any value decomposition method for centralized training with decentralized execution. Experiments across various cooperative MARL benchmarks show that COE outperforms current state-of-the-art exploration methods on hard-exploration tasks.
No More Pesky Hyperparameters: Offline Hyperparameter Tuning for RL
May 18, 2022
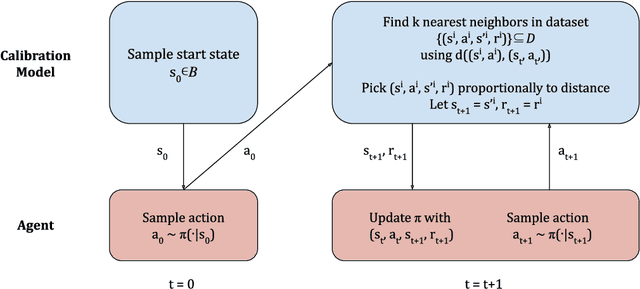
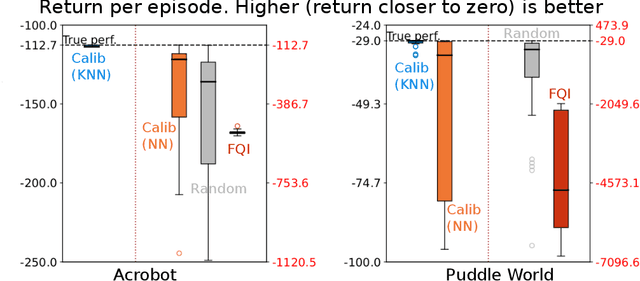
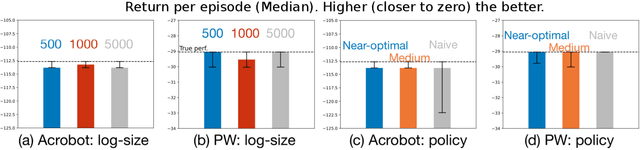
The performance of reinforcement learning (RL) agents is sensitive to the choice of hyperparameters. In real-world settings like robotics or industrial control systems, however, testing different hyperparameter configurations directly on the environment can be financially prohibitive, dangerous, or time consuming. We propose a new approach to tune hyperparameters from offline logs of data, to fully specify the hyperparameters for an RL agent that learns online in the real world. The approach is conceptually simple: we first learn a model of the environment from the offline data, which we call a calibration model, and then simulate learning in the calibration model to identify promising hyperparameters. We identify several criteria to make this strategy effective, and develop an approach that satisfies these criteria. We empirically investigate the method in a variety of settings to identify when it is effective and when it fails.