 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Pesky Hyperparameters: Offline Hyperparameter Tuning for RL
May 18, 2022
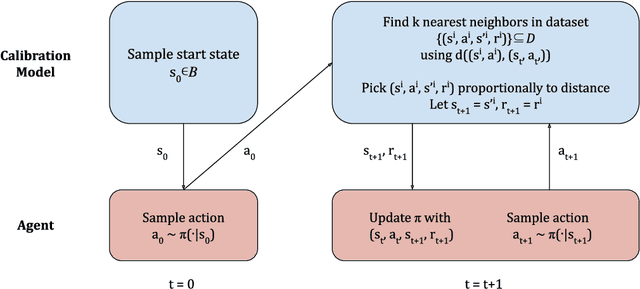
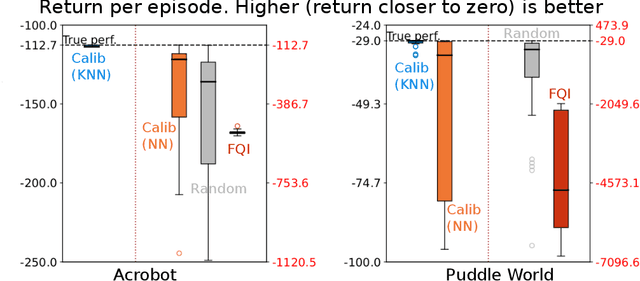
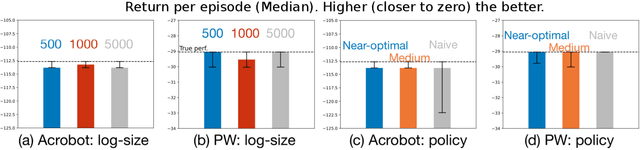
The performance of reinforcement learning (RL) agents is sensitive to the choice of hyperparameters. In real-world settings like robotics or industrial control systems, however, testing different hyperparameter configurations directly on the environment can be financially prohibitive, dangerous, or time consuming. We propose a new approach to tune hyperparameters from offline logs of data, to fully specify the hyperparameters for an RL agent that learns online in the real world. The approach is conceptually simple: we first learn a model of the environment from the offline data, which we call a calibration model, and then simulate learning in the calibration model to identify promising hyperparameters. We identify several criteria to make this strategy effective, and develop an approach that satisfies these criteria. We empirically investigate the method in a variety of settings to identify when it is effective and when it fails.
Commonsense Properties from Query Logs and Question Answering Forums
May 31, 2019



Commonsense knowledge about object properties, human behavior and general concepts is crucial for robust AI applications. However, automatic acquisition of this knowledge is challenging because of sparseness and bias in online sources. This paper presents Quasimodo, a methodology and tool suite for distilling commonsense properties from non-standard web sources. We devise novel ways of tapping into search-engine query logs and QA forums, and combining the resulting candidate assertions with statistical cues from encyclopedias, books and image tags in a corroboration step. Unlike prior work on commonsense knowledge bases, Quasimodo focuses on salient properties that are typically associated with certain objects or concepts. Extensive evaluations, including extrinsic use-case studies, show that Quasimodo provides better coverage than state-of-the-art baselines with comparable quality.
Effective extractive summarization using frequency-filtered entity relationship graphs
Oct 24, 2018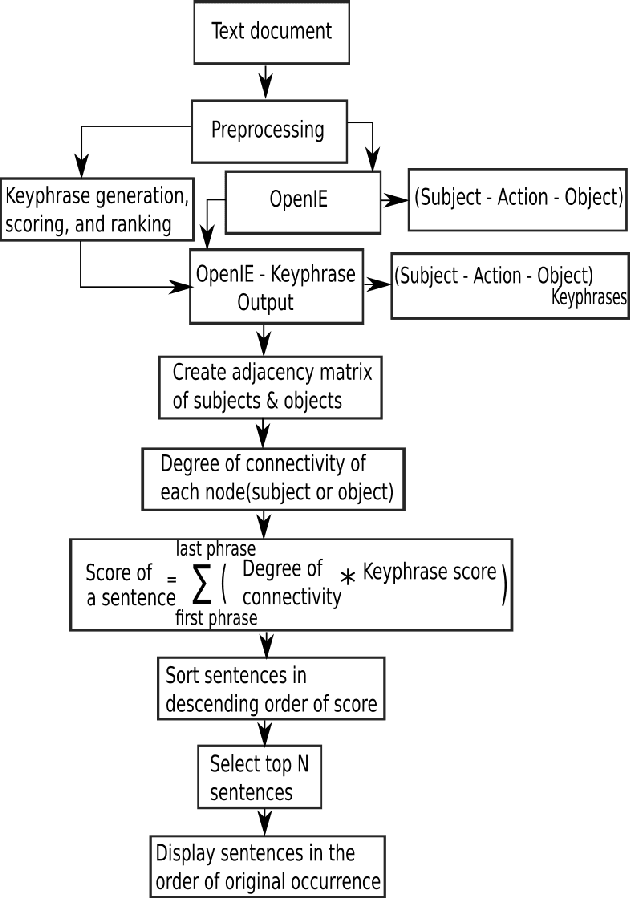
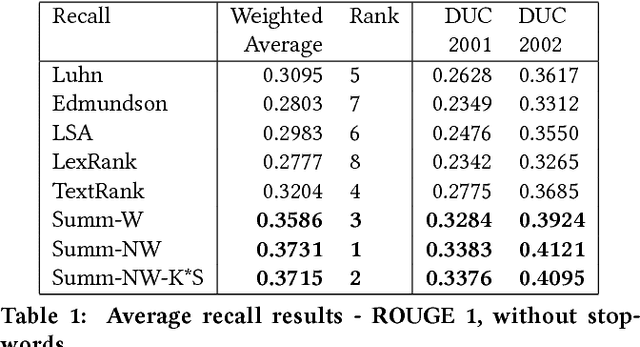
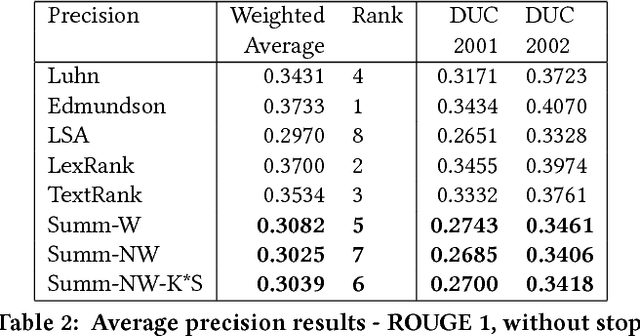
Word frequency-based methods for extractive summarization are easy to implement and yield reasonable results across languages. However, they have significant limitations - they ignore the role of context, they offer uneven coverage of topics in a document, and sometimes are disjointed and hard to read. We use a simple premise from linguistic typology - that English sentences are complete descriptors of potential interactions between entities, usually in the order subject-verb-object - to address a subset of these difficulties. We have developed a hybrid model of extractive summarization that combines word-frequency based keyword identification with information from automatically generated entity relationship graphs to select sentences for summaries. Comparative evaluation with word-frequency and topic word-based methods shows that the proposed method is competitive by conventional ROUGE standards, and yields moderately more informative summaries on average, as assessed by a large panel (N=94) of human raters.