 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping and Cleaning Open Commonsense Knowledge Bases with Generative Translation
Jun 22, 2023Structured knowledge bases (KBs) are the backbone of many know\-ledge-intensive applications, and their automated construction has received considerable attention. In particular, open information extraction (OpenIE) is often used to induce structure from a text. However, although it allows high recall, the extracted knowledge tends to inherit noise from the sources and the OpenIE algorithm. Besides, OpenIE tuples contain an open-ended, non-canonicalized set of relations, making the extracted knowledge's downstream exploitation harder. In this paper, we study the problem of mapping an open KB into the fixed schema of an existing KB, specifically for the case of commonsense knowledge. We propose approaching the problem by generative translation, i.e., by training a language model to generate fixed-schema assertions from open ones. Experiments show that this approach occupies a sweet spot between traditional manual, rule-based, or classification-based canonicalization and purely generative KB construction like COMET. Moreover, it produces higher mapping accuracy than the former while avoiding the association-based noise of the latter.
Do Children Texts Hold The Key To Commonsense Knowledge?
Oct 10, 2022

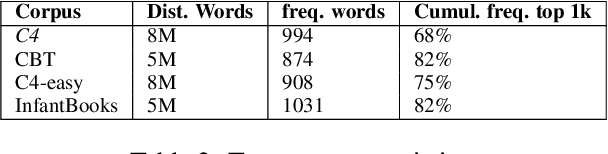

Compiling comprehensive repositories of commonsense knowledge is a long-standing problem in AI. Many concerns revolve around the issue of reporting bias, i.e., that frequency in text sources is not a good proxy for relevance or truth. This paper explores whether children's texts hold the key to commonsense knowledge compilation, based on the hypothesis that such content makes fewer assumptions on the reader's knowledge, and therefore spells out commonsense more explicitly. An analysis with several corpora shows that children's texts indeed contain much more, and more typical commonsense assertions. Moreover, experiments show that this advantage can be leveraged in popular language-model-based commonsense knowledge extraction settings, where task-unspecific fine-tuning on small amounts of children texts (childBERT) already yields significant improvements. This provides a refreshing perspective different from the common trend of deriving progress from ever larger models and corpora.
* 6 pages, 10 tables
Refined Commonsense Knowledge from Large-Scale Web Contents
Nov 30, 2021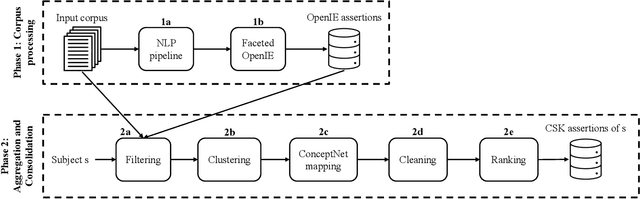

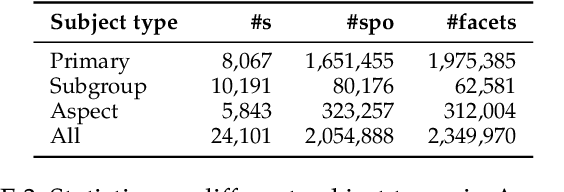

Commonsense knowledge (CSK) about concepts and their properties is useful for AI applications. Prior works like ConceptNet, COMET and others compiled large CSK collections, but are restricted in their expressiveness to subject-predicate-object (SPO) triples with simple concepts for S and strings for P and O. This paper presents a method, called ASCENT++, to automatically build a large-scale knowledge base (KB) of CSK assertions, with refined expressiveness and both better precision and recall than prior works. ASCENT++ goes beyond SPO triples by capturing composite concepts with subgroups and aspects, and by refining assertions with semantic facets. The latter is important to express the temporal and spatial validity of assertions and further qualifiers. ASCENT++ combines open information extraction with judicious cleaning and ranking by typicality and saliency scores. For high coverage, our method taps into the large-scale crawl C4 with broad web contents. The evaluation with human judgements shows the superior quality of the ASCENT++ KB, and an extrinsic evaluation for QA-support tasks underlines the benefits of ASCENT++. A web interface, data and code can be accessed at https://www.mpi-inf.mpg.de/ascentpp.
Commonsense Properties from Query Logs and Question Answering Forums
May 31, 2019



Commonsense knowledge about object properties, human behavior and general concepts is crucial for robust AI applications. However, automatic acquisition of this knowledge is challenging because of sparseness and bias in online sources. This paper presents Quasimodo, a methodology and tool suite for distilling commonsense properties from non-standard web sources. We devise novel ways of tapping into search-engine query logs and QA forums, and combining the resulting candidate assertions with statistical cues from encyclopedias, books and image tags in a corroboration step. Unlike prior work on commonsense knowledge bases, Quasimodo focuses on salient properties that are typically associated with certain objects or concepts. Extensive evaluations, including extrinsic use-case studies, show that Quasimodo provides better coverage than state-of-the-art baselines with comparable quality.