 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Children Texts Hold The Key To Commonsense Knowledge?
Paper and Code
Oct 10, 2022

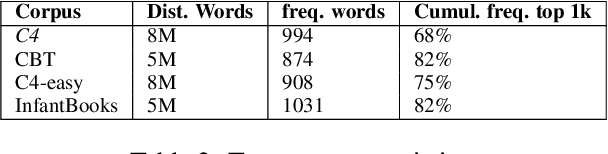

Compiling comprehensive repositories of commonsense knowledge is a long-standing problem in AI. Many concerns revolve around the issue of reporting bias, i.e., that frequency in text sources is not a good proxy for relevance or truth. This paper explores whether children's texts hold the key to commonsense knowledge compilation, based on the hypothesis that such content makes fewer assumptions on the reader's knowledge, and therefore spells out commonsense more explicitly. An analysis with several corpora shows that children's texts indeed contain much more, and more typical commonsense assertions. Moreover, experiments show that this advantage can be leveraged in popular language-model-based commonsense knowledge extraction settings, where task-unspecific fine-tuning on small amounts of children texts (childBERT) already yields significant improvements. This provides a refreshing perspective different from the common trend of deriving progress from ever larger models and corpora.