 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Reasoning in Ambiguous Contexts
Jun 13, 2025We study the ability of language models to reason about appropriate information disclosure - a central aspect of the evolving field of agentic privacy. Whereas previous works have focused on evaluating a model's ability to align with human decisions, we examine the role of ambiguity and missing context on model performance when making information-sharing decisions. We identify context ambiguity as a crucial barrier for high performance in privacy assessments. By designing Camber, a framework for context disambiguation, we show that model-generated decision rationales can reveal ambiguities and that systematically disambiguating context based on these rationales leads to significant accuracy improvements (up to 13.3\% in precision and up to 22.3\% in recall) as well as reductions in prompt sensitivity. Overall, our results indicate that approaches for context disambiguation are a promising way forward to enhance agentic privacy reasoning.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
PrivEdge: From Local to Distributed Private Training and Prediction
Apr 12, 2020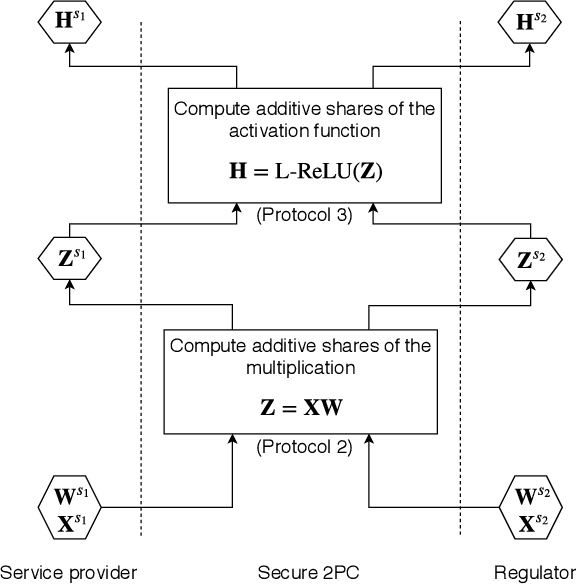
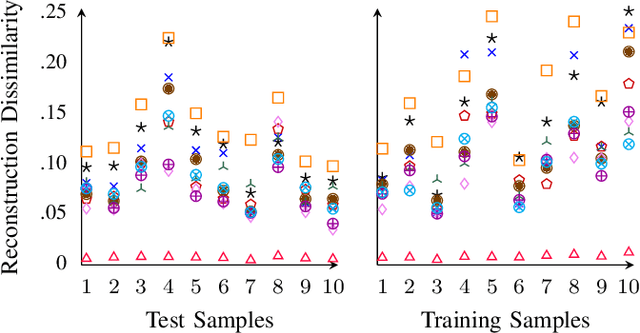


Machine Learning as a Service (MLaaS) operators provide model training and prediction on the cloud. MLaaS applications often rely on centralised collection and aggregation of user data, which could lead to significant privacy concerns when dealing with sensitive personal data. To address this problem, we propose PrivEdge, a technique for privacy-preserving MLaaS that safeguards the privacy of users who provide their data for training, as well as users who use the prediction service. With PrivEdge, each user independently uses their private data to locally train a one-class reconstructive adversarial network that succinctly represents their training data. As sending the model parameters to the service provider in the clear would reveal private information, PrivEdge secret-shares the parameters among two non-colluding MLaaS providers, to then provide cryptographically private prediction services through secure multi-party computation techniques. We quantify the benefits of PrivEdge and compare its performance with state-of-the-art centralised architectures on three privacy-sensitive image-based tasks: individual identification, writer identification, and handwritten letter recognition. Experimental results show that PrivEdge has high precision and recall in preserving privacy, as well as in distinguishing between private and non-private images. Moreover, we show the robustness of PrivEdge to image compression and biased training data. The source code is available at https://github.com/smartcameras/PrivEdge.
Differentially Private Summation with Multi-Message Shuffling
Jun 24, 2019In recent work, Cheu et al. (Eurocrypt 2019) proposed a protocol for $n$-party real summation in the shuffle model of differential privacy with $O_{\epsilon, \delta}(1)$ error and $\Theta(\epsilon\sqrt{n})$ one-bit messages per party. In contrast, every local model protocol for real summation must incur error $\Omega(1/\sqrt{n})$, and there exist protocols matching this lower bound which require just one bit of communication per party. Whether this gap in number of messages is necessary was left open by Cheu et al. In this note we show a protocol with $O(1/\epsilon)$ error and $O(\log(n/\delta))$ messages of size $O(\log(n))$ per party. This protocol is based on the work of Ishai et al.\ (FOCS 2006) showing how to implement distributed summation from secure shuffling, and the observation that this allows simulating the Laplace mechanism in the shuffle model.
The Privacy Blanket of the Shuffle Model
Mar 07, 2019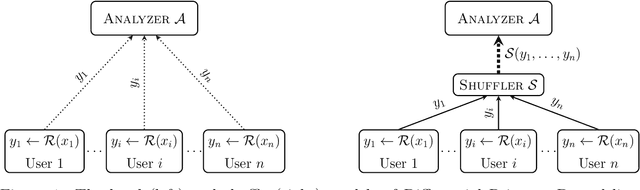
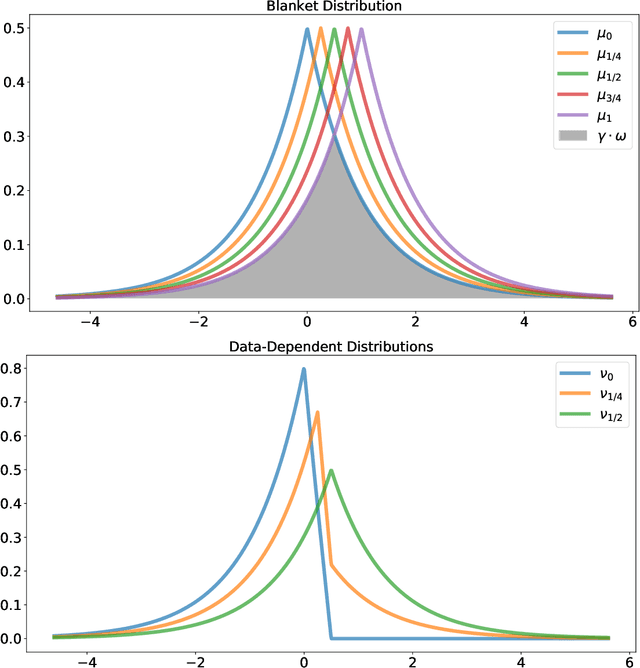
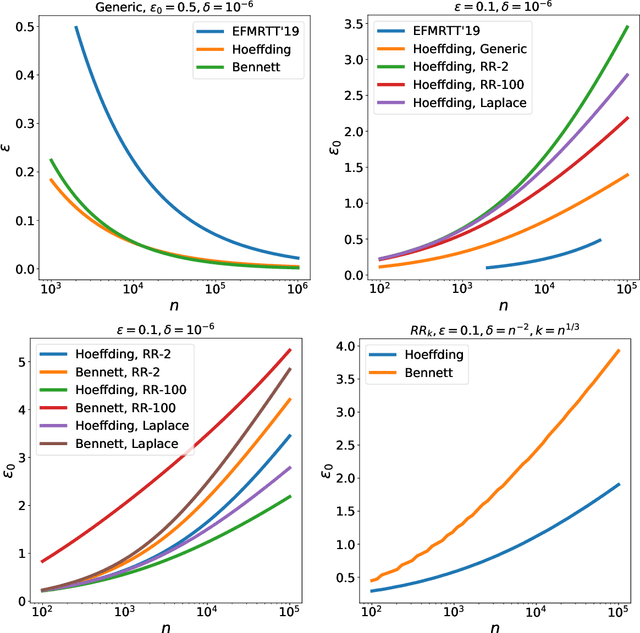
This work studies differential privacy in the context of the recently proposed shuffle model. Unlike in the local model, where the server collecting privatized data from users can track back an input to a specific user, in the shuffle model users submit their privatized inputs to a server anonymously. This setup yields a trust model which sits in between the classical curator and local models for differential privacy. The shuffle model is the core idea in the Encode, Shuffle, Analyze (ESA) model introduced by Bittau et al. (SOPS 2017). Recent work by Cheu et al. (Forthcoming, EUROCRYPT 2019) analyzes the differential privacy properties of the shuffle model and shows that in some cases shuffled protocols provide strictly better accuracy than local protocols. Additionally, Erlignsson et al. (SODA 2019) provide a privacy amplification bound quantifying the level of curator differential privacy achieved by the shuffle model in terms of the local differential privacy of the randomizer used by each user. In this context, we make three contributions. First, we provide an optimal single message protocol for summation of real numbers in the shuffle model. Our protocol is very simple and has better accuracy and communication than the protocols for this same problem proposed by Cheu et al. Optimality of this protocol follows from our second contribution, a new lower bound for the accuracy of private protocols for summation of real numbers in the shuffle model. The third contribution is a new amplification bound for analyzing the privacy of protocols in the shuffle model in terms of the privacy provided by the corresponding local randomizer. Our amplification bound generalizes the results by Erlingsson et al. to a wider range of parameters, and provides a whole family of methods to analyze privacy amplification in the shuffle model.