 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
Apr 15, 2026Scientific peer review faces mounting strain as submission volumes surge, making it increasingly difficult to sustain review quality, consistency, and timeliness. Recent advances in AI have led the community to consider its use in peer review, yet a key unresolved question is whether AI can generate technically sound reviews at real-world conference scale. Here we report the first large-scale field deployment of AI-assisted peer review: every main-track submission at AAAI-26 received one clearly identified AI review from a state-of-the-art system. The system combined frontier models, tool use, and safeguards in a multi-stage process to generate reviews for all 22,977 full-review papers in less than a day. A large-scale survey of AAAI-26 authors and program committee members showed that participants not only found AI reviews useful, but actually preferred them to human reviews on key dimensions such as technical accuracy and research suggestions. We also introduce a novel benchmark and find that our system substantially outperforms a simple LLM-generated review baseline at detecting a variety of scientific weaknesses. Together, these results show that state-of-the-art AI methods can already make meaningful contributions to scientific peer review at conference scale, opening a path toward the next generation of synergistic human-AI teaming for evaluating research.
Cosmic Microwave Background Recovery: A Graph-Based Bayesian Convolutional Network Approach
Feb 24, 2023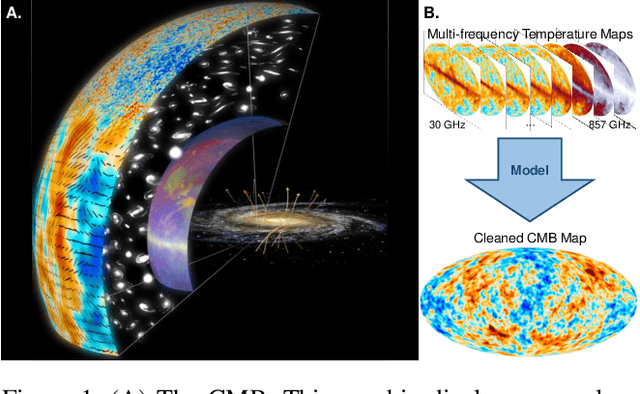
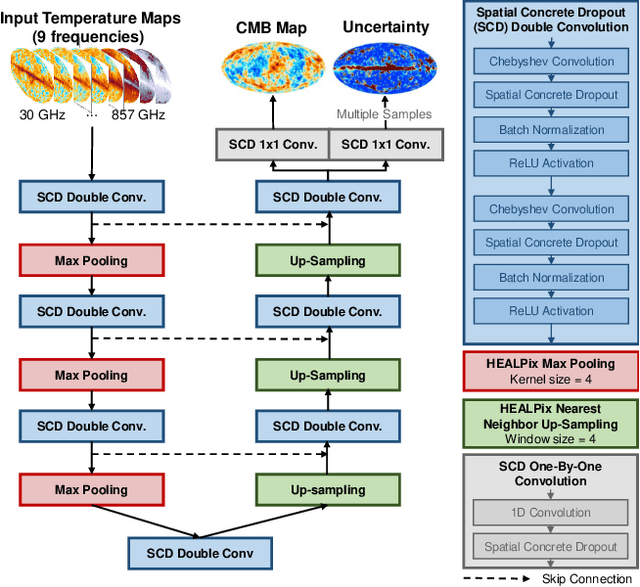
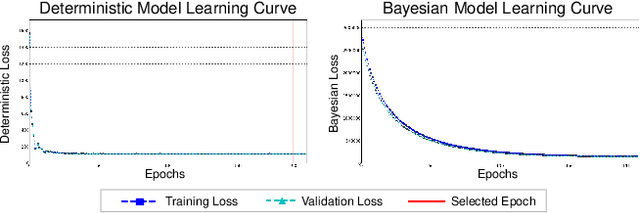

The cosmic microwave background (CMB) is a significant source of knowledge about the origin and evolution of our universe. However, observations of the CMB are contaminated by foreground emissions, obscuring the CMB signal and reducing its efficacy in constraining cosmological parameters. We employ deep learning as a data-driven approach to CMB cleaning from multi-frequency full-sky maps. In particular, we develop a graph-based Bayesian convolutional neural network based on the U-Net architecture that predicts cleaned CMB with pixel-wise uncertainty estimates. We demonstrate the potential of this technique on realistic simulated data based on the Planck mission. We show that our model accurately recovers the cleaned CMB sky map and resulting angular power spectrum while identifying regions of uncertainty. Finally, we discuss the current challenges and the path forward for deploying our model for CMB recovery on real observations.
Using Machine Learning to Reduce Observational Biases When Detecting New Impacts on Mars
Jul 12, 2022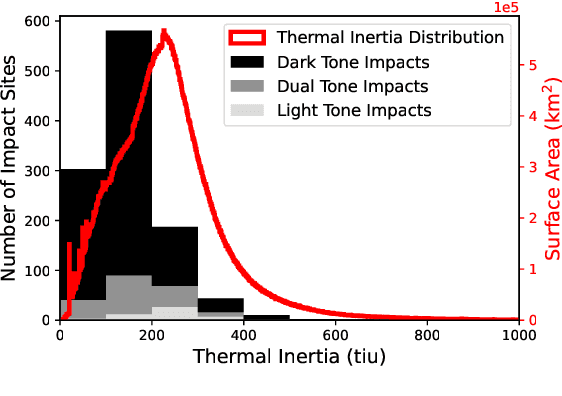
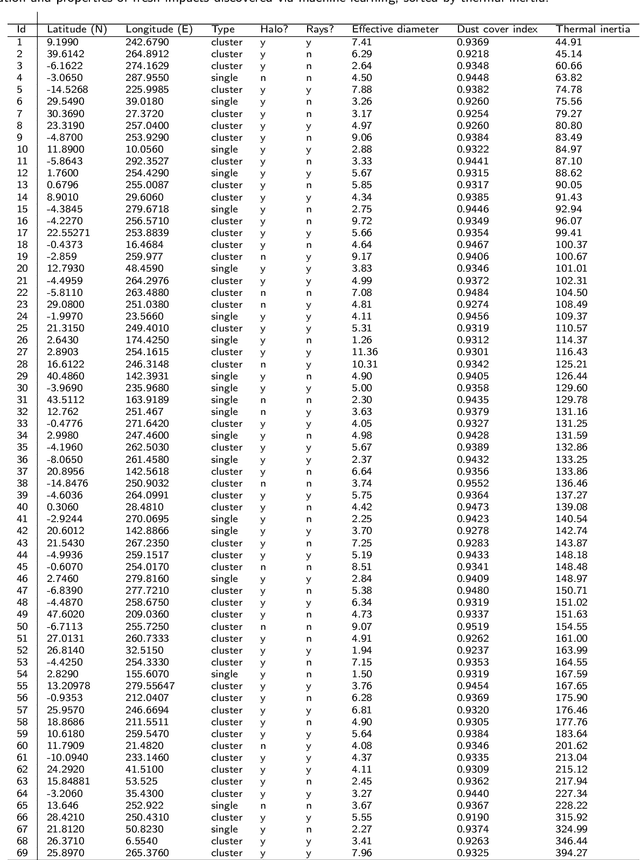
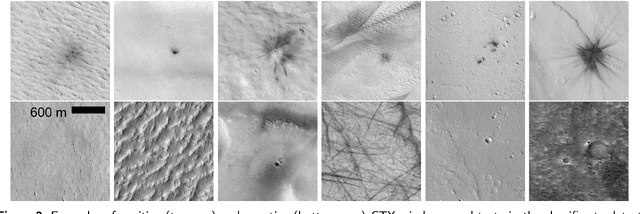
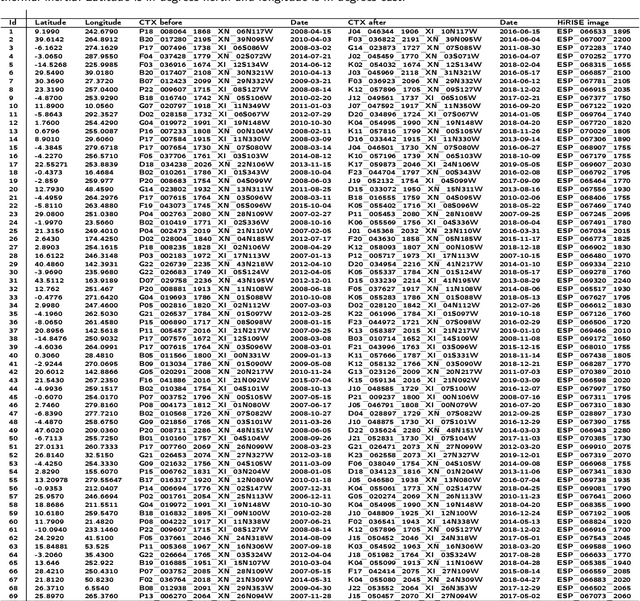
The current inventory of recent (fresh) impacts on Mars shows a strong bias towards areas of low thermal inertia. These areas are generally visually bright, and impacts create dark scours and rays that make them easier to detect. It is expected that impacts occur at a similar rate in areas of higher thermal inertia, but those impacts are under-detected. This study investigates the use of a trained machine learning classifier to increase the detection of fresh impacts on Mars using CTX data. This approach discovered 69 new fresh impacts that have been confirmed with follow-up HiRISE images. We found that examining candidates partitioned by thermal inertia (TI) values, which is only possible due to the large number of machine learning candidates, helps reduce the observational bias and increase the number of known high-TI impacts.
* 17 pages, 10 figures, 2 tables (Author's preprint, accepted version)
Hidden Heterogeneity: When to Choose Similarity-Based Calibration
Feb 03, 2022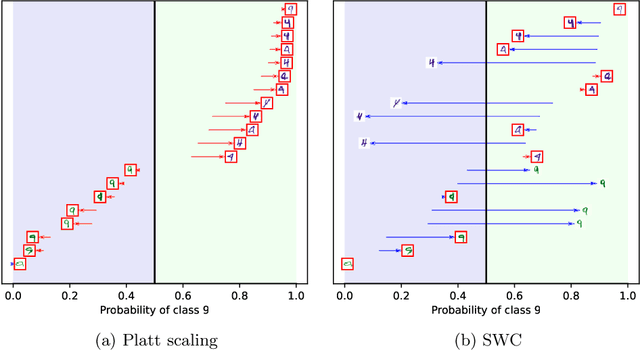

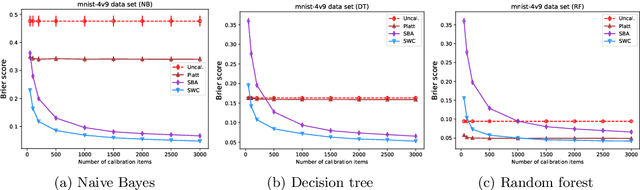
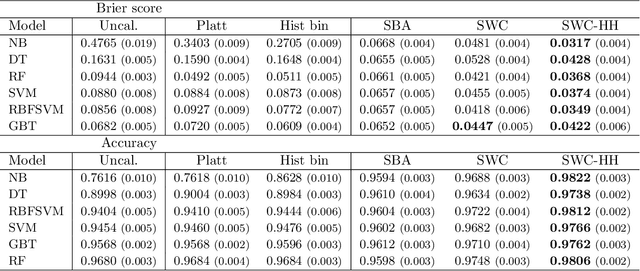
Trustworthy classifiers are essential to the adoption of machine learning predictions in many real-world settings. The predicted probability of possible outcomes can inform high-stakes decision making, particularly when assessing the expected value of alternative decisions or the risk of bad outcomes. These decisions require well calibrated probabilities, not just the correct prediction of the most likely class. Black-box classifier calibration methods can improve the reliability of a classifier's output without requiring retraining. However, these methods are unable to detect subpopulations where calibration could improve prediction accuracy. Such subpopulations are said to exhibit "hidden heterogeneity" (HH), because the original classifier did not detect them. The paper proposes a quantitative measure for HH. It also introduces two similarity-weighted calibration methods that can address HH by adapting locally to each test item: SWC weights the calibration set by similarity to the test item, and SWC-HH explicitly incorporates hidden heterogeneity to filter the calibration set. Experiments show that the improvements in calibration achieved by similarity-based calibration methods correlate with the amount of HH present and, given sufficient calibration data, generally exceed calibration achieved by global methods. HH can therefore serve as a useful diagnostic tool for identifying when local calibration methods are needed.
Integrating Novelty Detection Capabilities with MSL Mastcam Operations to Enhance Data Analysis
Mar 23, 2021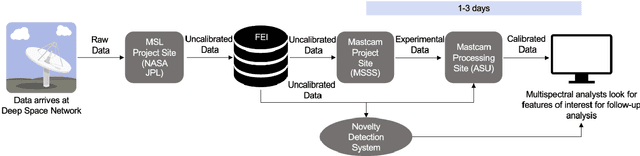



While innovations in scientific instrumentation have pushed the boundaries of Mars rover mission capabilities, the increase in data complexity has pressured Mars Science Laboratory (MSL) and future Mars rover operations staff to quickly analyze complex data sets to meet progressively shorter tactical and strategic planning timelines. MSLWEB is an internal data tracking tool used by operations staff to perform first pass analysis on MSL image sequences, a series of products taken by the Mast camera, Mastcam. Mastcam's multiband multispectral image sequences require more complex analysis compared to standard 3-band RGB images. Typically, these are analyzed using traditional methods to identify unique features within the sequence. Given the short time frame of tactical planning in which downlinked images might need to be analyzed (within 5-10 hours before the next uplink), there exists a need to triage analysis time to focus on the most important sequences and parts of a sequence. We address this need by creating products for MSLWEB that use novelty detection to help operations staff identify unusual data that might be diagnostic of new or atypical compositions or mineralogies detected within an imaging scene. This was achieved in two ways: 1) by creating products for each sequence to identify novel regions in the image, and 2) by assigning multispectral sequences a sortable novelty score. These new products provide colorized heat maps of inferred novelty that operations staff can use to rapidly review downlinked data and focus their efforts on analyzing potentially new kinds of diagnostic multispectral signatures. This approach has the potential to guide scientists to new discoveries by quickly drawing their attention to often subtle variations not detectable with simple color composites.
Visualizing Image Content to Explain Novel Image Discovery
Aug 14, 2019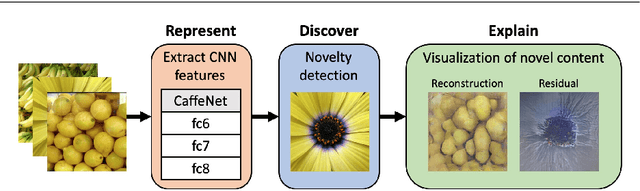
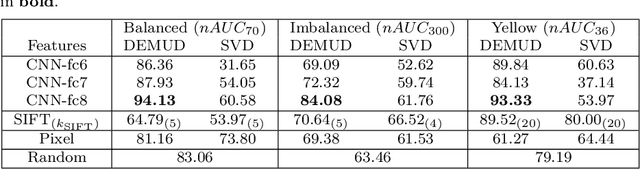

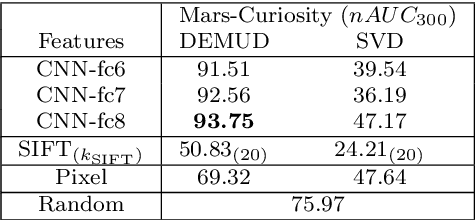
The initial analysis of any large data set can be divided into two phases: (1) the identification of common trends or patterns and (2) the identification of anomalies or outliers that deviate from those trends. We focus on the goal of detecting observations with novel content, which can alert us to artifacts in the data set or, potentially, the discovery of previously unknown phenomena. To aid in interpreting and diagnosing the novel aspect of these selected observations, we recommend the use of novelty detection methods that generate explanations. In the context of large image data sets, these explanations should highlight what aspect of a given image is new (color, shape, texture, content) in a human-comprehensible form. We propose DEMUD-VIS, the first method for providing visual explanations of novel image content by employing a convolutional neural network (CNN) to extract image features, a method that uses reconstruction error to detect novel content, and an up-convolutional network to convert CNN feature representations back into image space. We demonstrate this approach on diverse images from ImageNet, freshwater streams, and the surface of Mars.
Interpretable Discovery in Large Image Data Sets
Jun 21, 2018
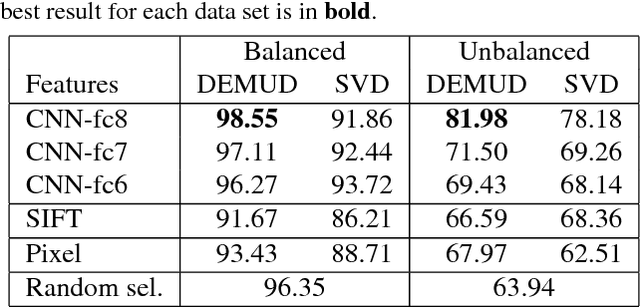
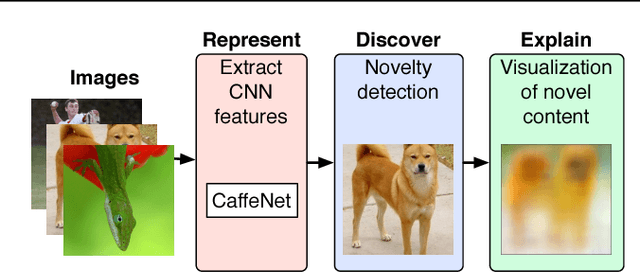
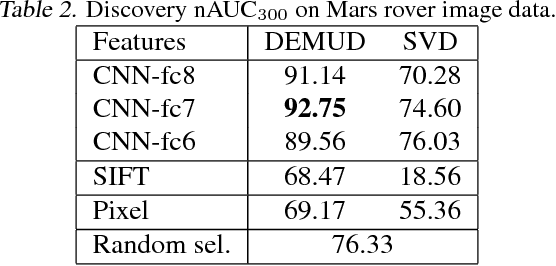
Automated detection of new, interesting, unusual, or anomalous images within large data sets has great value for applications from surveillance (e.g., airport security) to science (observations that don't fit a given theory can lead to new discoveries). Many image data analysis systems are turning to convolutional neural networks (CNNs) to represent image content due to their success in achieving high classification accuracy rates. However, CNN representations are notoriously difficult for humans to interpret. We describe a new strategy that combines novelty detection with CNN image features to achieve rapid discovery with interpretable explanations of novel image content. We applied this technique to familiar images from ImageNet as well as to a scientific image collection from planetary science.