 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Heterogeneity: When to Choose Similarity-Based Calibration
Paper and Code
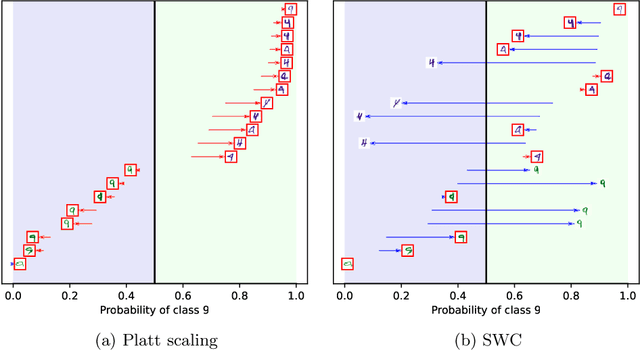

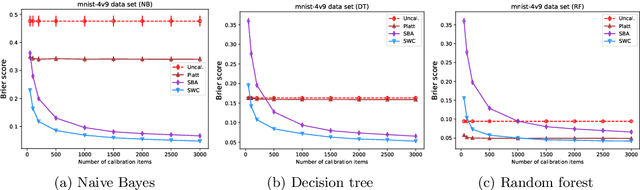
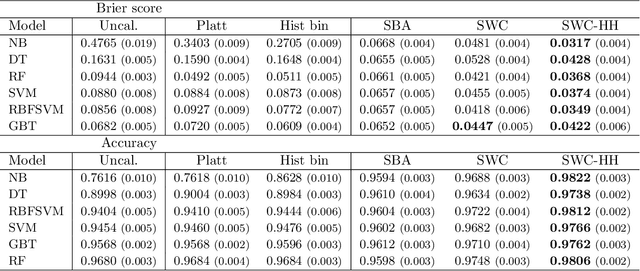
Trustworthy classifiers are essential to the adoption of machine learning predictions in many real-world settings. The predicted probability of possible outcomes can inform high-stakes decision making, particularly when assessing the expected value of alternative decisions or the risk of bad outcomes. These decisions require well calibrated probabilities, not just the correct prediction of the most likely class. Black-box classifier calibration methods can improve the reliability of a classifier's output without requiring retraining. However, these methods are unable to detect subpopulations where calibration could improve prediction accuracy. Such subpopulations are said to exhibit "hidden heterogeneity" (HH), because the original classifier did not detect them. The paper proposes a quantitative measure for HH. It also introduces two similarity-weighted calibration methods that can address HH by adapting locally to each test item: SWC weights the calibration set by similarity to the test item, and SWC-HH explicitly incorporates hidden heterogeneity to filter the calibration set. Experiments show that the improvements in calibration achieved by similarity-based calibration methods correlate with the amount of HH present and, given sufficient calibration data, generally exceed calibration achieved by global methods. HH can therefore serve as a useful diagnostic tool for identifying when local calibration methods are needed.