 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifetime policy reuse and the importance of task capacity
Paper and Code
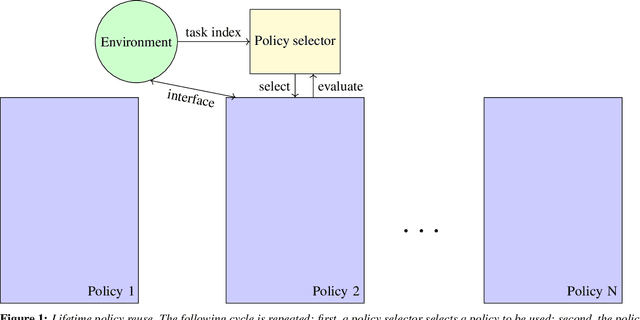
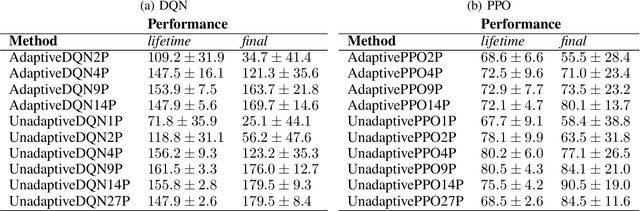
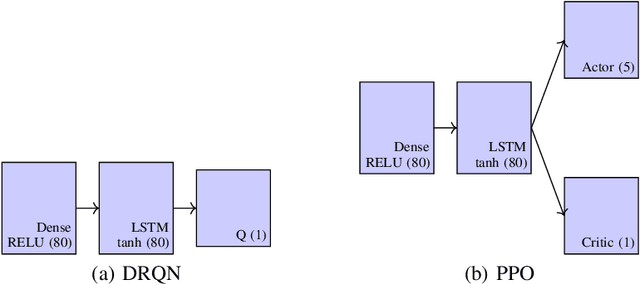
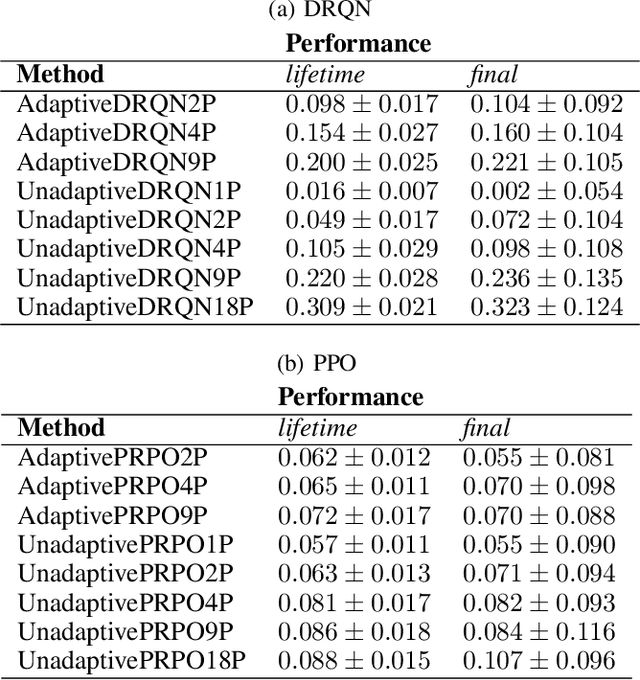
A long-standing challenge in artificial intelligence is lifelong learning. In lifelong learning, many tasks are presented in sequence and learners must efficiently transfer knowledge between tasks while avoiding catastrophic forgetting over long lifetimes. On these problems, policy reuse and other multi-policy reinforcement learning techniques can learn many tasks. However, they can generate many temporary or permanent policies, resulting in memory issues. Consequently, there is a need for lifetime-scalable methods that continually refine a policy library of a pre-defined size. This paper presents a first approach to lifetime-scalable policy reuse. To pre-select the number of policies, a notion of task capacity, the maximal number of tasks that a policy can accurately solve, is proposed. To evaluate lifetime policy reuse using this method, two state-of-the-art single-actor base-learners are compared: 1) a value-based reinforcement learner, Deep Q-Network (DQN) or Deep Recurrent Q-Network (DRQN); and 2) an actor-critic reinforcement learner, Proximal Policy Optimisation (PPO) with or without Long Short-Term Memory layer. By selecting the number of policies based on task capacity, D(R)QN achieves near-optimal performance with 6 policies in a 27-task MDP domain and 9 policies in an 18-task POMDP domain; with fewer policies, catastrophic forgetting and negative transfer are observed. Due to slow, monotonic improvement, PPO requires fewer policies, 1 policy for the 27-task domain and 4 policies for the 18-task domain, but it learns the tasks with lower accuracy than D(R)QN. These findings validate lifetime-scalable policy reuse and suggest using D(R)QN for larger and PPO for smaller library sizes.