 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Explore, Exploit, or Escape ($E^4$): near-optimal safety-constrained reinforcement learning in polynomial time
Paper and Code
Nov 14, 2021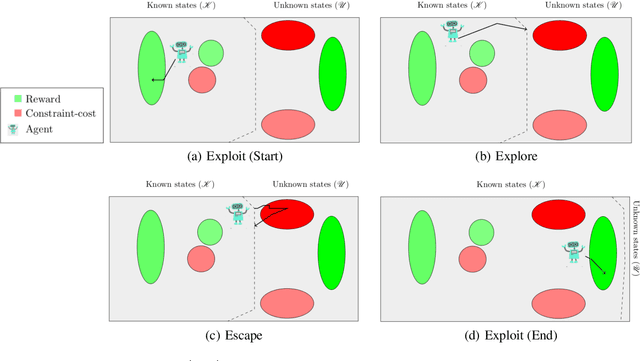
In reinforcement learning (RL), an agent must explore an initially unknown environment in order to learn a desired behaviour. When RL agents are deployed in real world environments, safety is of primary concern. Constrained Markov decision processes (CMDPs) can provide long-term safety constraints; however, the agent may violate the constraints in an effort to explore its environment. This paper proposes a model-based RL algorithm called Explicit Explore, Exploit, or Escape ($E^{4}$), which extends the Explicit Explore or Exploit ($E^{3}$) algorithm to a robust CMDP setting. $E^4$ explicitly separates exploitation, exploration, and escape CMDPs, allowing targeted policies for policy improvement across known states, discovery of unknown states, as well as safe return to known states. $E^4$ robustly optimises these policies on the worst-case CMDP from a set of CMDP models consistent with the empirical observations of the deployment environment. Theoretical results show that $E^4$ finds a near-optimal constraint-satisfying policy in polynomial time whilst satisfying safety constraints throughout the learning process. We discuss robust-constrained offline optimisation algorithms as well as how to incorporate uncertainty in transition dynamics of unknown states based on empirical inference and prior knowledge.