 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliceSemOcc: Vertical Slice Based Multimodal 3D Semantic Occupancy Representation
Sep 04, 2025Driven by autonomous driving's demands for precise 3D perception, 3D semantic occupancy prediction has become a pivotal research topic. Unlike bird's-eye-view (BEV) methods, which restrict scene representation to a 2D plane, occupancy prediction leverages a complete 3D voxel grid to model spatial structures in all dimensions, thereby capturing semantic variations along the vertical axis. However, most existing approaches overlook height-axis information when processing voxel features. And conventional SENet-style channel attention assigns uniform weight across all height layers, limiting their ability to emphasize features at different heights. To address these limitations, we propose SliceSemOcc, a novel vertical slice based multimodal framework for 3D semantic occupancy representation. Specifically, we extract voxel features along the height-axis using both global and local vertical slices. Then, a global local fusion module adaptively reconciles fine-grained spatial details with holistic contextual information. Furthermore, we propose the SEAttention3D module, which preserves height-wise resolution through average pooling and assigns dynamic channel attention weights to each height layer. Extensive experiments on nuScenes-SurroundOcc and nuScenes-OpenOccupancy datasets verify that our method significantly enhances mean IoU, achieving especially pronounced gains on most small-object categories. Detailed ablation studies further validate the effectiveness of the proposed SliceSemOcc framework.
DecoratingFusion: A LiDAR-Camera Fusion Network with the Combination of Point-level and Feature-level Fusion
Dec 31, 2024Lidars and cameras play essential roles in autonomous driving, offering complementary information for 3D detection. The state-of-the-art fusion methods integrate them at the feature level, but they mostly rely on the learned soft association between point clouds and images, which lacks interpretability and neglects the hard association between them. In this paper, we combine feature-level fusion with point-level fusion, using hard association established by the calibration matrices to guide the generation of object queries. Specifically, in the early fusion stage, we use the 2D CNN features of images to decorate the point cloud data, and employ two independent sparse convolutions to extract the decorated point cloud features. In the mid-level fusion stage, we initialize the queries with a center heatmap and embed the predicted class labels as auxiliary information into the queries, making the initial positions closer to the actual centers of the targets. Extensive experiments conducted on two popular datasets, i.e. KITTI, Waymo, demonstrate the superiority of DecoratingFusion.
FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
Sep 21, 2023
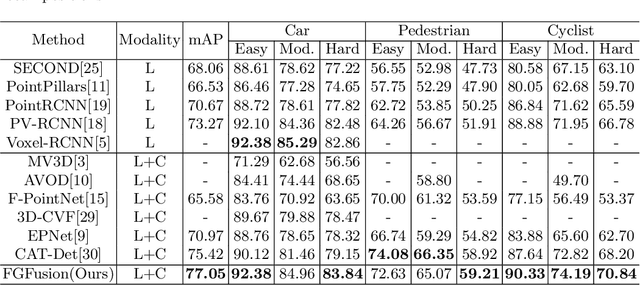

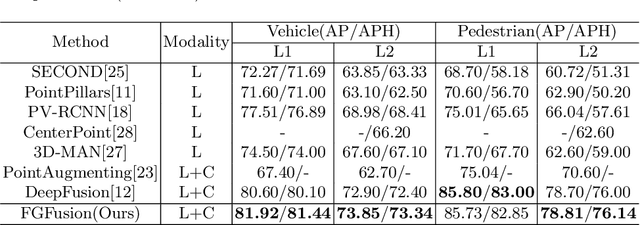
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.