 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Based Pseudo-Label Refining for Source-free Domain Adaptation
Apr 23, 2025
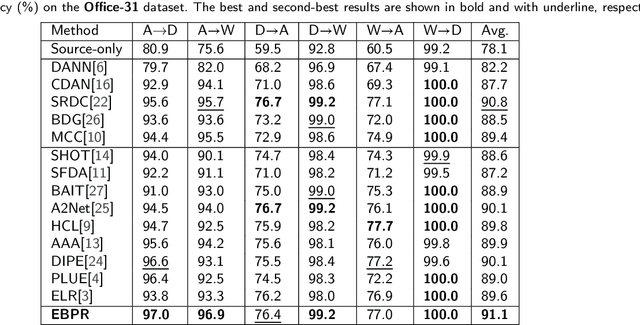


Source-free domain adaptation (SFDA), which involves adapting models without access to source data, is both demanding and challenging. Existing SFDA techniques typically rely on pseudo-labels generated from confidence levels, leading to negative transfer due to significant noise. To tackle this problem, Energy-Based Pseudo-Label Refining (EBPR) is proposed for SFDA. Pseudo-labels are created for all sample clusters according to their energy scores. Global and class energy thresholds are computed to selectively filter pseudo-labels. Furthermore, a contrastive learning strategy is introduced to filter difficult samples, aligning them with their augmented versions to learn more discriminative features. Our method is validated on the Office-31, Office-Home, and VisDA-C datasets, consistently finding that our model outperformed state-of-the-art methods.
SPARNet: Continual Test-Time Adaptation via Sample Partitioning Strategy and Anti-Forgetting Regularization
Jan 01, 2025



Test-time Adaptation (TTA) aims to improve model performance when the model encounters domain changes after deployment. The standard TTA mainly considers the case where the target domain is static, while the continual TTA needs to undergo a sequence of domain changes. This encounters a significant challenge as the model needs to adapt for the long-term and is unaware of when the domain changes occur. The quality of pseudo-labels is hard to guarantee. Noisy pseudo-labels produced by simple self-training methods can cause error accumulation and catastrophic forgetting. In this work, we propose a new framework named SPARNet which consists of two parts, sample partitioning strategy and anti-forgetting regularization. The sample partition strategy divides samples into two groups, namely reliable samples and unreliable samples. According to the characteristics of each group of samples, we choose different strategies to deal with different groups of samples. This ensures that reliable samples contribute more to the model. At the same time, the negative impacts of unreliable samples are eliminated by the mean teacher's consistency learning. Finally, we introduce a regularization term to alleviate the catastrophic forgetting problem, which can limit important parameters from excessive changes. This term enables long-term adaptation of parameters in the network. The effectiveness of our method is demonstrated in continual TTA scenario by conducting a large number of experiments on CIFAR10-C, CIFAR100-C and ImageNet-C.
SIDE: Self-supervised Intermediate Domain Exploration for Source-free Domain Adaptation
Oct 13, 2023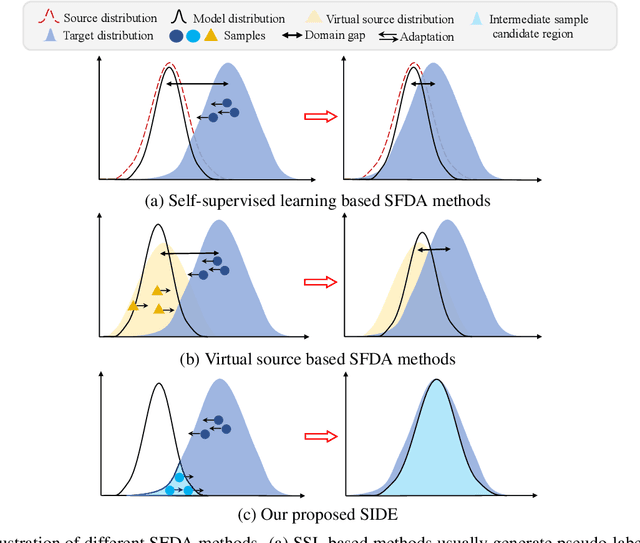
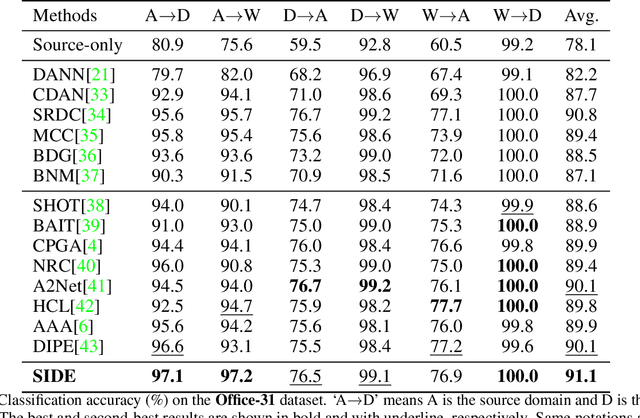
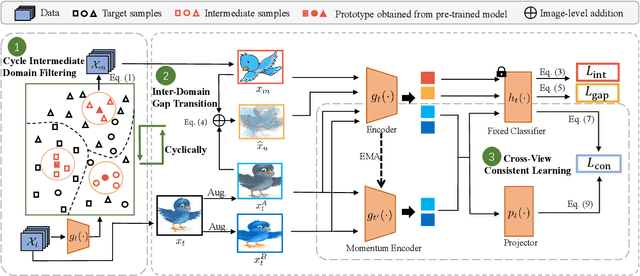
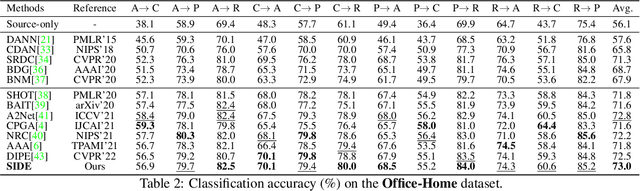
Domain adaptation aims to alleviate the domain shift when transferring the knowledge learned from the source domain to the target domain. Due to privacy issues, source-free domain adaptation (SFDA), where source data is unavailable during adaptation, has recently become very demanding yet challenging. Existing SFDA methods focus on either self-supervised learning of target samples or reconstruction of virtual source data. The former overlooks the transferable knowledge in the source model, whilst the latter introduces even more uncertainty. To address the above issues, this paper proposes self-supervised intermediate domain exploration (SIDE) that effectively bridges the domain gap with an intermediate domain, where samples are cyclically filtered out in a self-supervised fashion. First, we propose cycle intermediate domain filtering (CIDF) to cyclically select intermediate samples with similar distributions over source and target domains. Second, with the aid of those intermediate samples, an inter-domain gap transition (IDGT) module is developed to mitigate possible distribution mismatches between the source and target data. Finally, we introduce cross-view consistency learning (CVCL) to maintain the intrinsic class discriminability whilst adapting the model to the target domain. Extensive experiments on three popular benchmarks, i.e. Office-31, Office-Home and VisDA-C, show that our proposed SIDE achieves competitive performance against state-of-the-art methods.
Image Style Transfer and Content-Style Disentanglement
Nov 25, 2021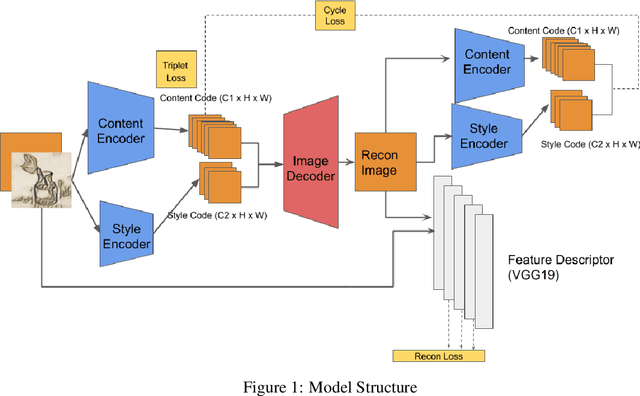
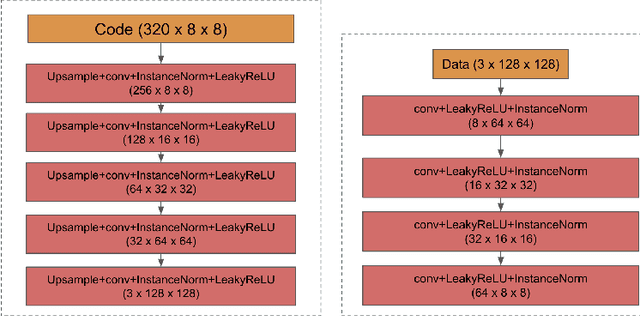

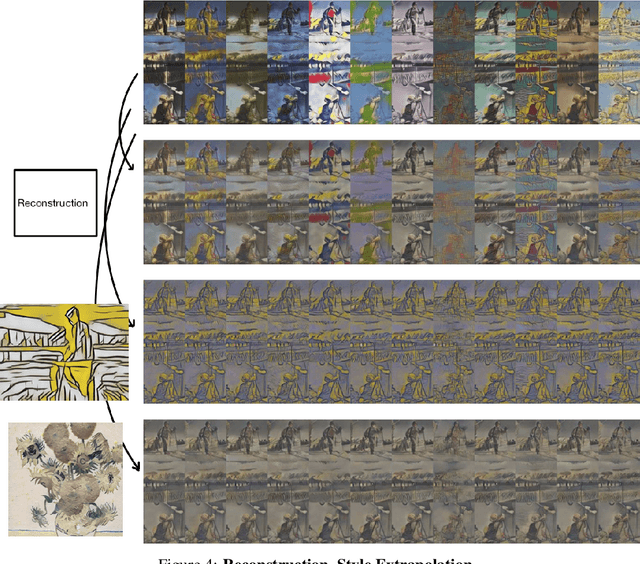
We propose a way of learning disentangled content-style representation of image, allowing us to extrapolate images to any style as well as interpolate between any pair of styles. By augmenting data set in a supervised setting and imposing triplet loss, we ensure the separation of information encoded by content and style representation. We also make use of cycle-consistency loss to guarantee that images could be reconstructed faithfully by their representation.