Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Style Transfer and Content-Style Disentanglement
Nov 25, 2021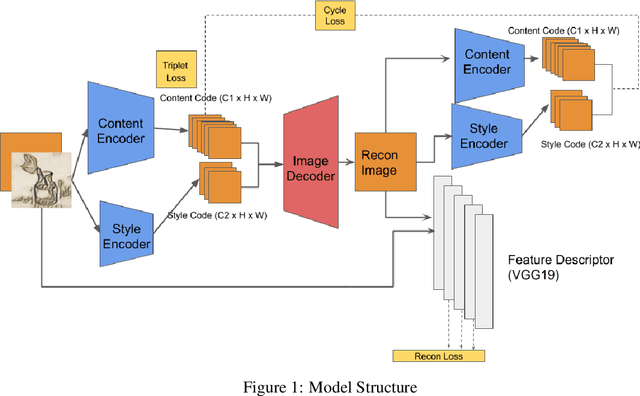
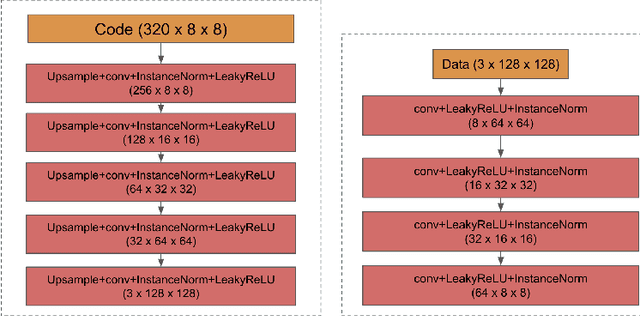

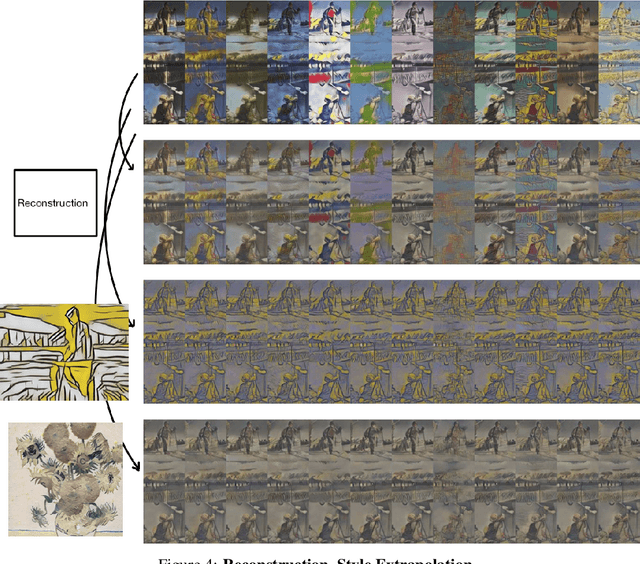
We propose a way of learning disentangled content-style representation of image, allowing us to extrapolate images to any style as well as interpolate between any pair of styles. By augmenting data set in a supervised setting and imposing triplet loss, we ensure the separation of information encoded by content and style representation. We also make use of cycle-consistency loss to guarantee that images could be reconstructed faithfully by their representation.
* 10 pages, 6 figures
Via